 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDAR-Anchored Collaborative Distillation for Robust 2D Representations
Feb 13, 2026As deep learning continues to advance, self-supervised learning has made considerable strides. It allows 2D image encoders to extract useful features for various downstream tasks, including those related to vision-based systems. Nevertheless, pre-trained 2D image encoders fall short in conducting the task under noisy and adverse weather conditions beyond clear daytime scenes, which require for robust visual perception. To address these issues, we propose a novel self-supervised approach, \textbf{Collaborative Distillation}, which leverages 3D LiDAR as self-supervision to improve robustness to noisy and adverse weather conditions in 2D image encoders while retaining their original capabilities. Our method outperforms competing methods in various downstream tasks across diverse conditions and exhibits strong generalization ability. In addition, our method also improves 3D awareness stemming from LiDAR's characteristics. This advancement highlights our method's practicality and adaptability in real-world scenarios.
The Devil is in the Details: Simple Remedies for Image-to-LiDAR Representation Learning
Jan 16, 2025LiDAR is a crucial sensor in autonomous driving, commonly used alongside cameras. By exploiting this camera-LiDAR setup and recent advances in image representation learning, prior studies have shown the promising potential of image-to-LiDAR distillation. These prior arts focus on the designs of their own losses to effectively distill the pre-trained 2D image representations into a 3D model. However, the other parts of the designs have been surprisingly unexplored. We find that fundamental design elements, e.g., the LiDAR coordinate system, quantization according to the existing input interface, and data utilization, are more critical than developing loss functions, which have been overlooked in prior works. In this work, we show that simple fixes to these designs notably outperform existing methods by 16% in 3D semantic segmentation on the nuScenes dataset and 13% in 3D object detection on the KITTI dataset in downstream task performance. We focus on overlooked design choices along the spatial and temporal axes. Spatially, prior work has used cylindrical coordinate and voxel sizes without considering their side effects yielded with a commonly deployed sparse convolution layer input interface, leading to spatial quantization errors in 3D models. Temporally, existing work has avoided cumbersome data curation by discarding unsynced data, limiting the use to only the small portion of data that is temporally synced across sensors. We analyze these effects and propose simple solutions for each overlooked aspect.
CLIP-Actor: Text-Driven Recommendation and Stylization for Animating Human Meshes
Jun 09, 2022
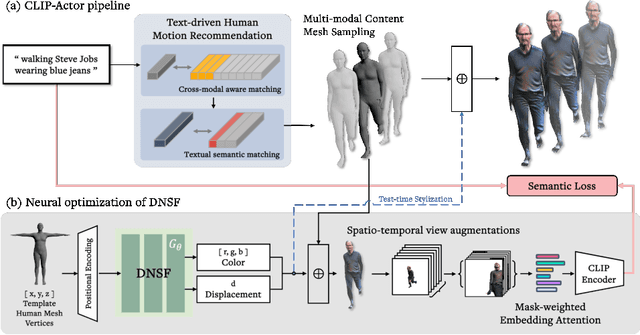
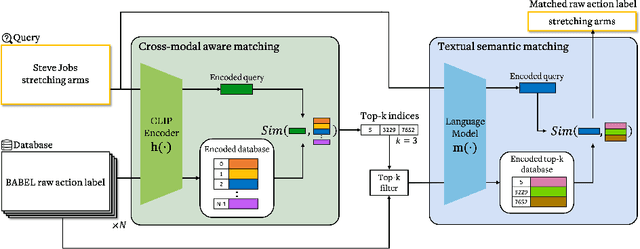
We propose CLIP-Actor, a text-driven motion recommendation and neural mesh stylization system for human mesh animation. CLIP-Actor animates a 3D human mesh to conform to a text prompt by recommending a motion sequence and learning mesh style attributes. Prior work fails to generate plausible results when the artist-designed mesh content does not conform to the text from the beginning. Instead, we build a text-driven human motion recommendation system by leveraging a large-scale human motion dataset with language labels. Given a natural language prompt, CLIP-Actor first suggests a human motion that conforms to the prompt in a coarse-to-fine manner. Then, we propose a synthesize-through-optimization method that detailizes and texturizes a recommended mesh sequence in a disentangled way from the pose of each frame. It allows the style attribute to conform to the prompt in a temporally-consistent and pose-agnostic manner. The decoupled neural optimization also enables spatio-temporal view augmentation from multi-frame human motion. We further propose the mask-weighted embedding attention, which stabilizes the optimization process by rejecting distracting renders containing scarce foreground pixels. We demonstrate that CLIP-Actor produces plausible and human-recognizable style 3D human mesh in motion with detailed geometry and texture from a natural language prompt.
Unified 3D Mesh Recovery of Humans and Animals by Learning Animal Exercise
Nov 03, 2021



We propose an end-to-end unified 3D mesh recovery of humans and quadruped animals trained in a weakly-supervised way. Unlike recent work focusing on a single target class only, we aim to recover 3D mesh of broader classes with a single multi-task model. However, there exists no dataset that can directly enable multi-task learning due to the absence of both human and animal annotations for a single object, e.g., a human image does not have animal pose annotations; thus, we have to devise a new way to exploit heterogeneous datasets. To make the unstable disjoint multi-task learning jointly trainable, we propose to exploit the morphological similarity between humans and animals, motivated by animal exercise where humans imitate animal poses. We realize the morphological similarity by semantic correspondences, called sub-keypoint, which enables joint training of human and animal mesh regression branches. Besides, we propose class-sensitive regularization methods to avoid a mean-shape bias and to improve the distinctiveness across multi-classes. Our method performs favorably against recent uni-modal models on various human and animal datasets while being far more compact.