 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Devil is in the Details: Simple Remedies for Image-to-LiDAR Representation Learning
Jan 16, 2025LiDAR is a crucial sensor in autonomous driving, commonly used alongside cameras. By exploiting this camera-LiDAR setup and recent advances in image representation learning, prior studies have shown the promising potential of image-to-LiDAR distillation. These prior arts focus on the designs of their own losses to effectively distill the pre-trained 2D image representations into a 3D model. However, the other parts of the designs have been surprisingly unexplored. We find that fundamental design elements, e.g., the LiDAR coordinate system, quantization according to the existing input interface, and data utilization, are more critical than developing loss functions, which have been overlooked in prior works. In this work, we show that simple fixes to these designs notably outperform existing methods by 16% in 3D semantic segmentation on the nuScenes dataset and 13% in 3D object detection on the KITTI dataset in downstream task performance. We focus on overlooked design choices along the spatial and temporal axes. Spatially, prior work has used cylindrical coordinate and voxel sizes without considering their side effects yielded with a commonly deployed sparse convolution layer input interface, leading to spatial quantization errors in 3D models. Temporally, existing work has avoided cumbersome data curation by discarding unsynced data, limiting the use to only the small portion of data that is temporally synced across sensors. We analyze these effects and propose simple solutions for each overlooked aspect.
MR-Occ: Efficient Camera-LiDAR 3D Semantic Occupancy Prediction Using Hierarchical Multi-Resolution Voxel Representation
Dec 29, 2024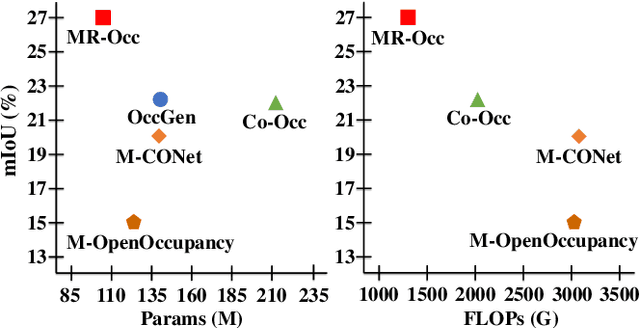
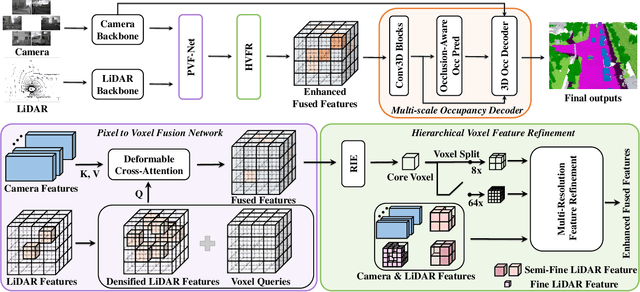
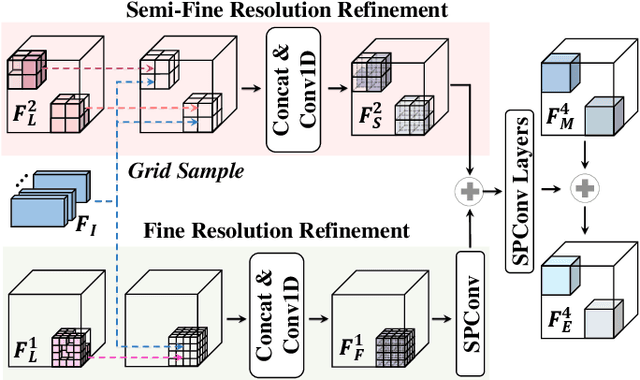
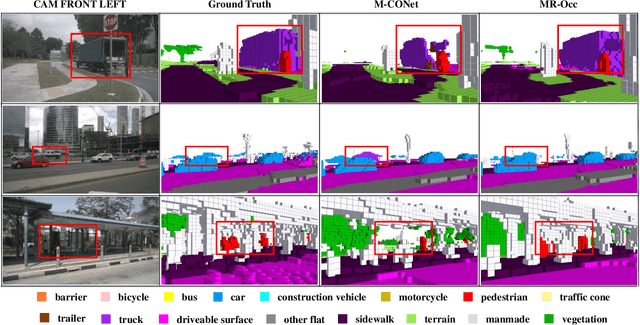
Accurate 3D perception is essential for understanding the environment in autonomous driving. Recent advancements in 3D semantic occupancy prediction have leveraged camera-LiDAR fusion to improve robustness and accuracy. However, current methods allocate computational resources uniformly across all voxels, leading to inefficiency, and they also fail to adequately address occlusions, resulting in reduced accuracy in challenging scenarios. We propose MR-Occ, a novel approach for camera-LiDAR fusion-based 3D semantic occupancy prediction, addressing these challenges through three key components: Hierarchical Voxel Feature Refinement (HVFR), Multi-scale Occupancy Decoder (MOD), and Pixel to Voxel Fusion Network (PVF-Net). HVFR improves performance by enhancing features for critical voxels, reducing computational cost. MOD introduces an `occluded' class to better handle regions obscured from sensor view, improving accuracy. PVF-Net leverages densified LiDAR features to effectively fuse camera and LiDAR data through a deformable attention mechanism. Extensive experiments demonstrate that MR-Occ achieves state-of-the-art performance on the nuScenes-Occupancy dataset, surpassing previous approaches by +5.2% in IoU and +5.3% in mIoU while using fewer parameters and FLOPs. Moreover, MR-Occ demonstrates superior performance on the SemanticKITTI dataset, further validating its effectiveness and generalizability across diverse 3D semantic occupancy benchmarks.
UFO: Unidentified Foreground Object Detection in 3D Point Cloud
Jan 08, 2024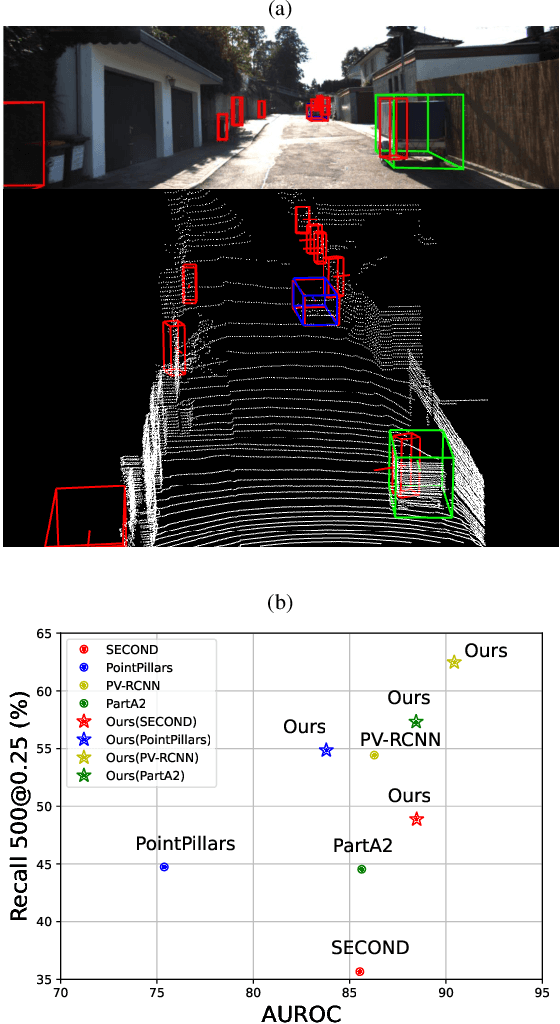
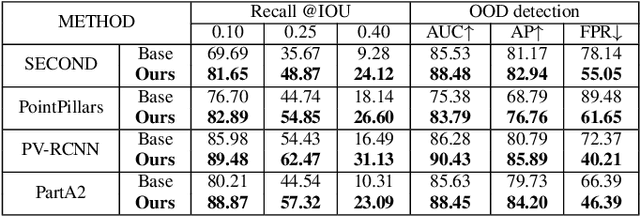
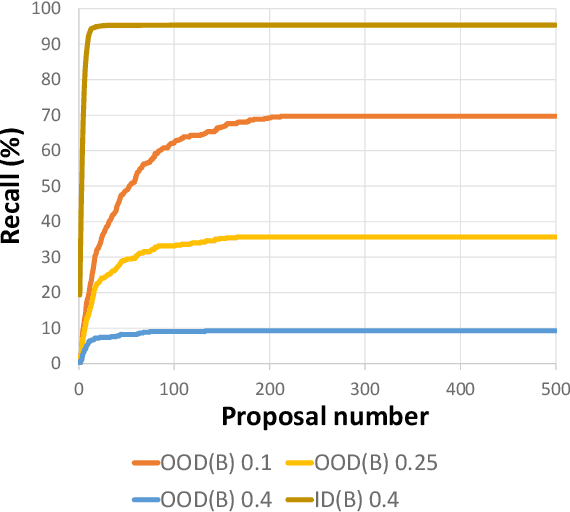
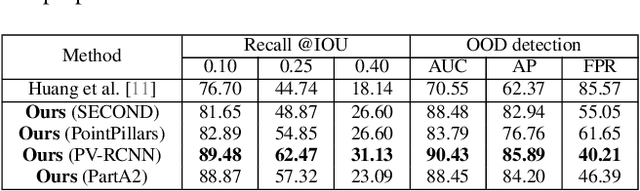
In this paper, we raise a new issue on Unidentified Foreground Object (UFO) detection in 3D point clouds, which is a crucial technology in autonomous driving in the wild. UFO detection is challenging in that existing 3D object detectors encounter extremely hard challenges in both 3D localization and Out-of-Distribution (OOD) detection. To tackle these challenges, we suggest a new UFO detection framework including three tasks: evaluation protocol, methodology, and benchmark. The evaluation includes a new approach to measure the performance on our goal, i.e. both localization and OOD detection of UFOs. The methodology includes practical techniques to enhance the performance of our goal. The benchmark is composed of the KITTI Misc benchmark and our additional synthetic benchmark for modeling a more diverse range of UFOs. The proposed framework consistently enhances performance by a large margin across all four baseline detectors: SECOND, PointPillars, PV-RCNN, and PartA2, giving insight for future work on UFO detection in the wild.
Three Factors to Improve Out-of-Distribution Detection
Aug 02, 2023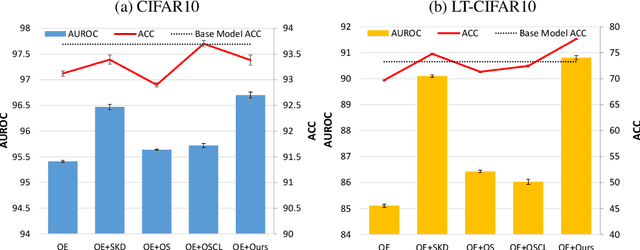
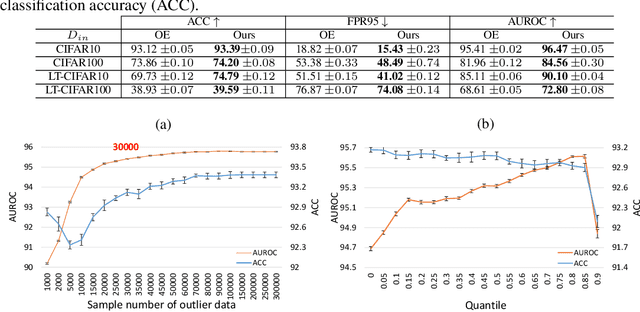
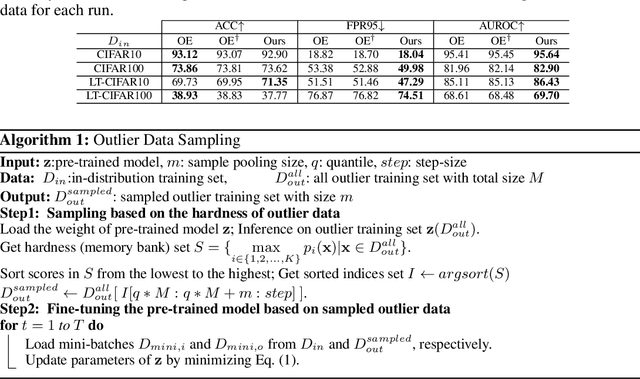

In the problem of out-of-distribution (OOD) detection, the usage of auxiliary data as outlier data for fine-tuning has demonstrated encouraging performance. However, previous methods have suffered from a trade-off between classification accuracy (ACC) and OOD detection performance (AUROC, FPR, AUPR). To improve this trade-off, we make three contributions: (i) Incorporating a self-knowledge distillation loss can enhance the accuracy of the network; (ii) Sampling semi-hard outlier data for training can improve OOD detection performance with minimal impact on accuracy; (iii) The introduction of our novel supervised contrastive learning can simultaneously improve OOD detection performance and the accuracy of the network. By incorporating all three factors, our approach enhances both accuracy and OOD detection performance by addressing the trade-off between classification and OOD detection. Our method achieves improvements over previous approaches in both performance metrics.
Balanced Energy Regularization Loss for Out-of-distribution Detection
Jun 18, 2023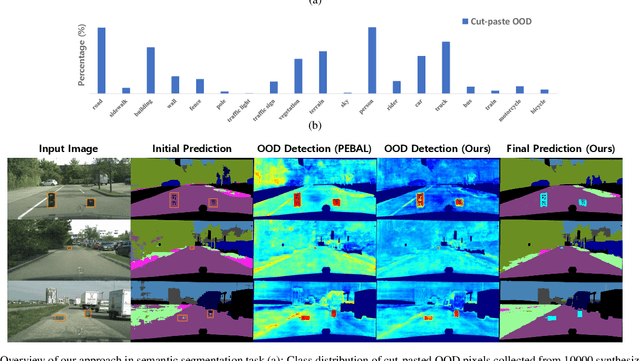
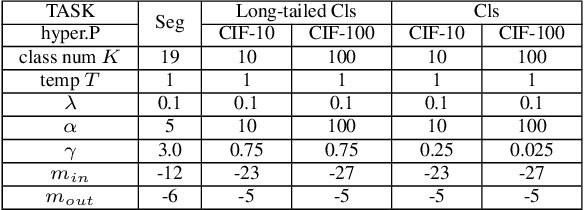
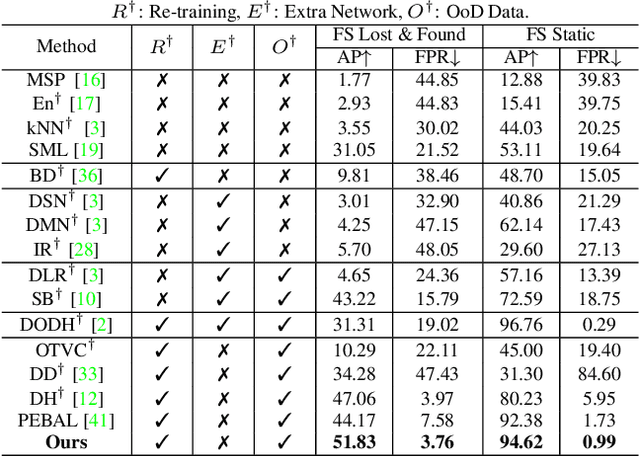
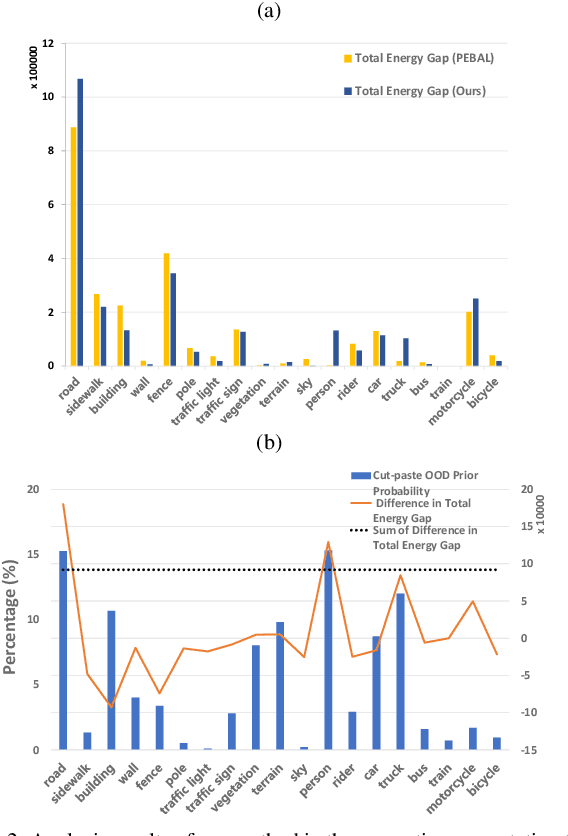
In the field of out-of-distribution (OOD) detection, a previous method that use auxiliary data as OOD data has shown promising performance. However, the method provides an equal loss to all auxiliary data to differentiate them from inliers. However, based on our observation, in various tasks, there is a general imbalance in the distribution of the auxiliary OOD data across classes. We propose a balanced energy regularization loss that is simple but generally effective for a variety of tasks. Our balanced energy regularization loss utilizes class-wise different prior probabilities for auxiliary data to address the class imbalance in OOD data. The main concept is to regularize auxiliary samples from majority classes, more heavily than those from minority classes. Our approach performs better for OOD detection in semantic segmentation, long-tailed image classification, and image classification than the prior energy regularization loss. Furthermore, our approach achieves state-of-the-art performance in two tasks: OOD detection in semantic segmentation and long-tailed image classification. Code is available at https://github.com/hyunjunChhoi/Balanced_Energy.