 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMR-Occ: Efficient Camera-LiDAR 3D Semantic Occupancy Prediction Using Hierarchical Multi-Resolution Voxel Representation
Dec 29, 2024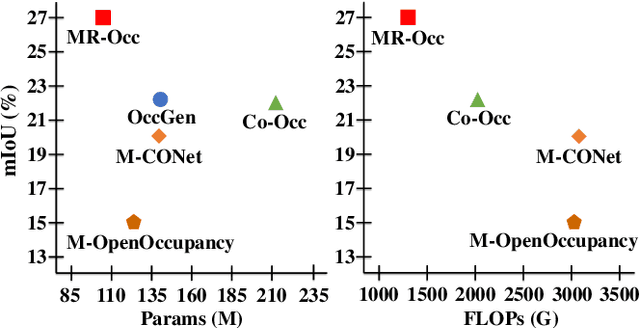
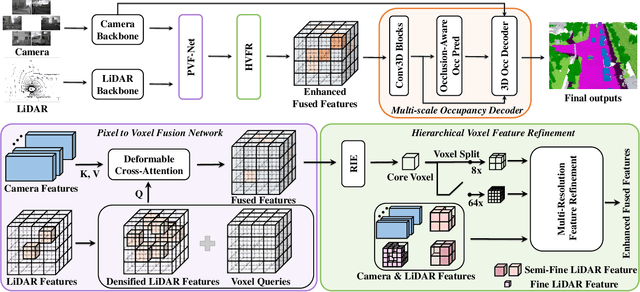
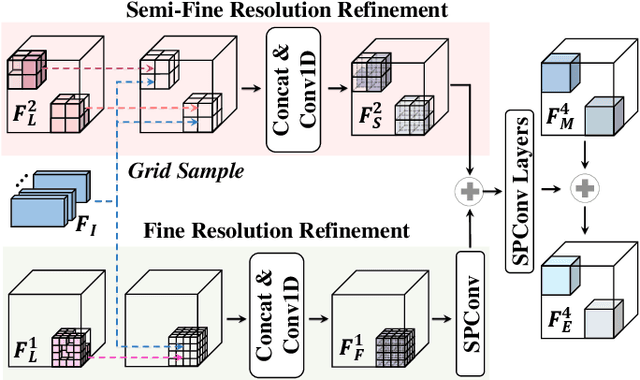
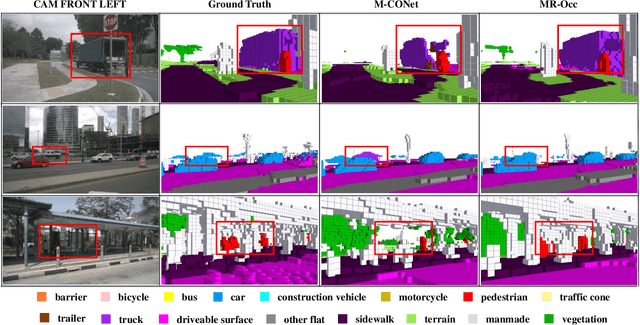
Accurate 3D perception is essential for understanding the environment in autonomous driving. Recent advancements in 3D semantic occupancy prediction have leveraged camera-LiDAR fusion to improve robustness and accuracy. However, current methods allocate computational resources uniformly across all voxels, leading to inefficiency, and they also fail to adequately address occlusions, resulting in reduced accuracy in challenging scenarios. We propose MR-Occ, a novel approach for camera-LiDAR fusion-based 3D semantic occupancy prediction, addressing these challenges through three key components: Hierarchical Voxel Feature Refinement (HVFR), Multi-scale Occupancy Decoder (MOD), and Pixel to Voxel Fusion Network (PVF-Net). HVFR improves performance by enhancing features for critical voxels, reducing computational cost. MOD introduces an `occluded' class to better handle regions obscured from sensor view, improving accuracy. PVF-Net leverages densified LiDAR features to effectively fuse camera and LiDAR data through a deformable attention mechanism. Extensive experiments demonstrate that MR-Occ achieves state-of-the-art performance on the nuScenes-Occupancy dataset, surpassing previous approaches by +5.2% in IoU and +5.3% in mIoU while using fewer parameters and FLOPs. Moreover, MR-Occ demonstrates superior performance on the SemanticKITTI dataset, further validating its effectiveness and generalizability across diverse 3D semantic occupancy benchmarks.
JoVALE: Detecting Human Actions in Video Using Audiovisual and Language Contexts
Dec 18, 2024Video Action Detection (VAD) involves localizing and categorizing action instances in videos. Videos inherently contain various information sources, including audio, visual cues, and surrounding scene contexts. Effectively leveraging this multi-modal information for VAD is challenging, as the model must accurately focus on action-relevant cues. In this study, we introduce a novel multi-modal VAD architecture called the Joint Actor-centric Visual, Audio, Language Encoder (JoVALE). JoVALE is the first VAD method to integrate audio and visual features with scene descriptive context derived from large image captioning models. The core principle of JoVALE is the actor-centric aggregation of audio, visual, and scene descriptive contexts, where action-related cues from each modality are identified and adaptively combined. We propose a specialized module called the Actor-centric Multi-modal Fusion Network, designed to capture the joint interactions among actors and multi-modal contexts through Transformer architecture. Our evaluation conducted on three popular VAD benchmarks, AVA, UCF101-24, and JHMDB51-21, demonstrates that incorporating multi-modal information leads to significant performance gains. JoVALE achieves state-of-the-art performances. The code will be available at \texttt{https://github.com/taeiin/AAAI2025-JoVALE}.
CRT-Fusion: Camera, Radar, Temporal Fusion Using Motion Information for 3D Object Detection
Nov 05, 2024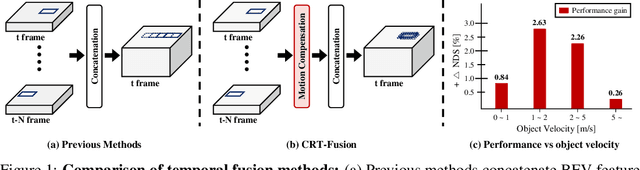
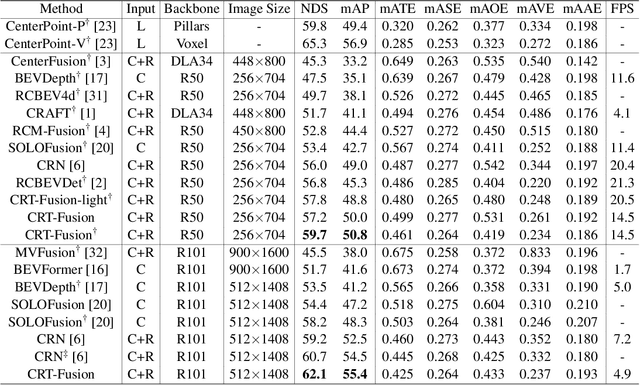
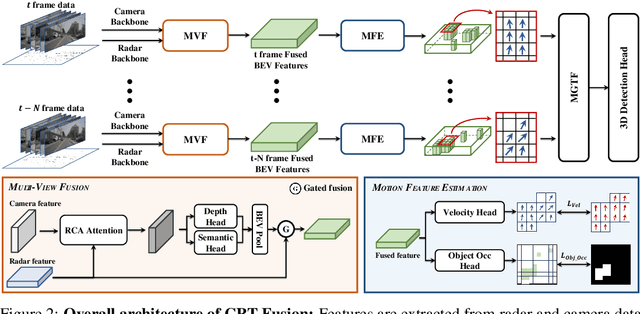
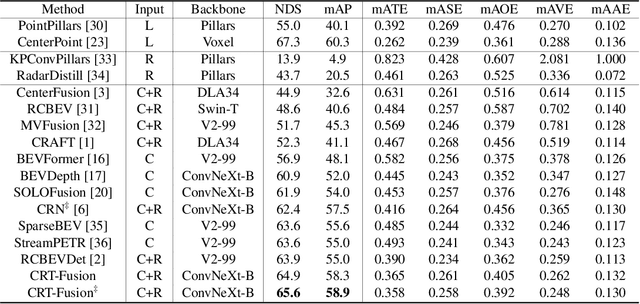
Accurate and robust 3D object detection is a critical component in autonomous vehicles and robotics. While recent radar-camera fusion methods have made significant progress by fusing information in the bird's-eye view (BEV) representation, they often struggle to effectively capture the motion of dynamic objects, leading to limited performance in real-world scenarios. In this paper, we introduce CRT-Fusion, a novel framework that integrates temporal information into radar-camera fusion to address this challenge. Our approach comprises three key modules: Multi-View Fusion (MVF), Motion Feature Estimator (MFE), and Motion Guided Temporal Fusion (MGTF). The MVF module fuses radar and image features within both the camera view and bird's-eye view, thereby generating a more precise unified BEV representation. The MFE module conducts two simultaneous tasks: estimation of pixel-wise velocity information and BEV segmentation. Based on the velocity and the occupancy score map obtained from the MFE module, the MGTF module aligns and fuses feature maps across multiple timestamps in a recurrent manner. By considering the motion of dynamic objects, CRT-Fusion can produce robust BEV feature maps, thereby improving detection accuracy and robustness. Extensive evaluations on the challenging nuScenes dataset demonstrate that CRT-Fusion achieves state-of-the-art performance for radar-camera-based 3D object detection. Our approach outperforms the previous best method in terms of NDS by +1.7%, while also surpassing the leading approach in mAP by +1.4%. These significant improvements in both metrics showcase the effectiveness of our proposed fusion strategy in enhancing the reliability and accuracy of 3D object detection.
JARViS: Detecting Actions in Video Using Unified Actor-Scene Context Relation Modeling
Aug 07, 2024



Video action detection (VAD) is a formidable vision task that involves the localization and classification of actions within the spatial and temporal dimensions of a video clip. Among the myriad VAD architectures, two-stage VAD methods utilize a pre-trained person detector to extract the region of interest features, subsequently employing these features for action detection. However, the performance of two-stage VAD methods has been limited as they depend solely on localized actor features to infer action semantics. In this study, we propose a new two-stage VAD framework called Joint Actor-scene context Relation modeling based on Visual Semantics (JARViS), which effectively consolidates cross-modal action semantics distributed globally across spatial and temporal dimensions using Transformer attention. JARViS employs a person detector to produce densely sampled actor features from a keyframe. Concurrently, it uses a video backbone to create spatio-temporal scene features from a video clip. Finally, the fine-grained interactions between actors and scenes are modeled through a Unified Action-Scene Context Transformer to directly output the final set of actions in parallel. Our experimental results demonstrate that JARViS outperforms existing methods by significant margins and achieves state-of-the-art performance on three popular VAD datasets, including AVA, UCF101-24, and JHMDB51-21.
RadarDistill: Boosting Radar-based Object Detection Performance via Knowledge Distillation from LiDAR Features
Mar 08, 2024The inherent noisy and sparse characteristics of radar data pose challenges in finding effective representations for 3D object detection. In this paper, we propose RadarDistill, a novel knowledge distillation (KD) method, which can improve the representation of radar data by leveraging LiDAR data. RadarDistill successfully transfers desirable characteristics of LiDAR features into radar features using three key components: Cross-Modality Alignment (CMA), Activation-based Feature Distillation (AFD), and Proposal-based Feature Distillation (PFD). CMA enhances the density of radar features through multiple layers of dilation operations, effectively addressing the challenges of inefficient knowledge transfer from LiDAR to radar. AFD is designed to transfer knowledge from significant areas of the LiDAR features, specifically those regions where activation intensity exceeds a predetermined threshold. PFD guides the radar network to mimic LiDAR network features in the object proposals for accurately detected results while moderating features for misdetected proposals like false positives. Our comparative analyses conducted on the nuScenes datasets demonstrate that RadarDistill achieves state-of-the-art (SOTA) performance for radar-only object detection task, recording 20.5% in mAP and 43.7% in NDS. Also, RadarDistill significantly improves the performance of the camera-radar fusion model.
PillarGen: Enhancing Radar Point Cloud Density and Quality via Pillar-based Point Generation Network
Mar 08, 2024In this paper, we present a novel point generation model, referred to as Pillar-based Point Generation Network (PillarGen), which facilitates the transformation of point clouds from one domain into another. PillarGen can produce synthetic point clouds with enhanced density and quality based on the provided input point clouds. The PillarGen model performs the following three steps: 1) pillar encoding, 2) Occupied Pillar Prediction (OPP), and 3) Pillar to Point Generation (PPG). The input point clouds are encoded using a pillar grid structure to generate pillar features. Then, OPP determines the active pillars used for point generation and predicts the center of points and the number of points to be generated for each active pillar. PPG generates the synthetic points for each active pillar based on the information provided by OPP. We evaluate the performance of PillarGen using our proprietary radar dataset, focusing on enhancing the density and quality of short-range radar data using the long-range radar data as supervision. Our experiments demonstrate that PillarGen outperforms traditional point upsampling methods in quantitative and qualitative measures. We also confirm that when PillarGen is incorporated into bird's eye view object detection, a significant improvement in detection accuracy is achieved.
RCM-Fusion: Radar-Camera Multi-Level Fusion for 3D Object Detection
Jul 27, 2023While LiDAR sensors have been succesfully applied to 3D object detection, the affordability of radar and camera sensors has led to a growing interest in fusiong radars and cameras for 3D object detection. However, previous radar-camera fusion models have not been able to fully utilize radar information in that initial 3D proposals were generated based on the camera features only and the instance-level fusion is subsequently conducted. In this paper, we propose radar-camera multi-level fusion (RCM-Fusion), which fuses radar and camera modalities at both the feature-level and instance-level to fully utilize radar information. At the feature-level, we propose a Radar Guided BEV Encoder which utilizes radar Bird's-Eye-View (BEV) features to transform image features into precise BEV representations and then adaptively combines the radar and camera BEV features. At the instance-level, we propose a Radar Grid Point Refinement module that reduces localization error by considering the characteristics of the radar point clouds. The experiments conducted on the public nuScenes dataset demonstrate that our proposed RCM-Fusion offers 11.8% performance gain in nuScenes detection score (NDS) over the camera-only baseline model and achieves state-of-the-art performaces among radar-camera fusion methods in the nuScenes 3D object detection benchmark. Code will be made publicly available.