 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo View Transform or Not to View Transform: NeRF-based Pre-training Perspective
Mar 30, 2026Neural radiance fields (NeRFs) have emerged as a prominent pre-training paradigm for vision-centric autonomous driving, which enhances 3D geometry and appearance understanding in a fully self-supervised manner. To apply NeRF-based pretraining to 3D perception models, recent approaches have simply applied NeRFs to volumetric features obtained from view transformation. However, coupling NeRFs with view transformation inherits conflicting priors; view transformation imposes discrete and rigid representations, whereas radiance fields assume continuous and adaptive functions. When these opposing assumptions are forced into a single pipeline, the misalignment surfaces as blurry and ambiguous 3D representations that ultimately limit 3D scene understanding. Moreover, the NeRF network for pre-training is discarded during downstream tasks, resulting in inefficient utilization of enhanced 3D representations through NeRF. In this paper, we propose a novel NeRF-Resembled Point-based 3D detector that can learn continuous 3D representation and thus avoid the misaligned priors from view transformation. NeRP3D preserves the pre-trained NeRF network regardless of the tasks, inheriting the principle of continuous 3D representation learning and leading to greater potentials for both scene reconstruction and detection tasks. Experiments on nuScenes dataset demonstrate that our proposed approach significantly improves previous state-of-the-art methods, outperforming not only pretext scene reconstruction tasks but also downstream detection tasks.
Class-Distribution Guided Active Learning for 3D Occupancy Prediction in Autonomous Driving
Mar 28, 20263D occupancy prediction provides dense spatial understanding critical for safe autonomous driving. However, this task suffers from a severe class imbalance due to its volumetric representation, where safety-critical objects (bicycles, traffic cones, pedestrians) occupy minimal voxels compared to dominant backgrounds. Additionally, voxel-level annotation is costly, yet dedicating effort to dominant classes is inefficient. To address these challenges, we propose a class-distribution guided active learning framework for selecting training samples to annotate in autonomous driving datasets. Our approach combines three complementary criteria to select the training samples. Inter-sample diversity prioritizes samples whose predicted class distributions differ from those of the labeled set, intra-set diversity prevents redundant sampling within each acquisition cycle, and frequency-weighted uncertainty emphasizes rare classes by reweighting voxel-level entropy with inverse per-sample class proportions. We ensure evaluation validity by using a geographically disjoint train/validation split of Occ3D-nuScenes, which reduces train-validation overlap and mitigates potential map memorization. With only 42.4% labeled data, our framework reaches 26.62 mIoU, comparable to full supervision and outperforming active learning baselines at the same budget. We further validate generality on SemanticKITTI using a different architecture, demonstrating consistent effectiveness across datasets.
* IEEE RA-L 2026
REOcc: Camera-Radar Fusion with Radar Feature Enrichment for 3D Occupancy Prediction
Nov 10, 2025



Vision-based 3D occupancy prediction has made significant advancements, but its reliance on cameras alone struggles in challenging environments. This limitation has driven the adoption of sensor fusion, among which camera-radar fusion stands out as a promising solution due to their complementary strengths. However, the sparsity and noise of the radar data limits its effectiveness, leading to suboptimal fusion performance. In this paper, we propose REOcc, a novel camera-radar fusion network designed to enrich radar feature representations for 3D occupancy prediction. Our approach introduces two main components, a Radar Densifier and a Radar Amplifier, which refine radar features by integrating spatial and contextual information, effectively enhancing spatial density and quality. Extensive experiments on the Occ3D-nuScenes benchmark demonstrate that REOcc achieves significant performance gains over the camera-only baseline model, particularly in dynamic object classes. These results underscore REOcc's capability to mitigate the sparsity and noise of the radar data. Consequently, radar complements camera data more effectively, unlocking the full potential of camera-radar fusion for robust and reliable 3D occupancy prediction.
LabelDistill: Label-guided Cross-modal Knowledge Distillation for Camera-based 3D Object Detection
Jul 14, 2024



Recent advancements in camera-based 3D object detection have introduced cross-modal knowledge distillation to bridge the performance gap with LiDAR 3D detectors, leveraging the precise geometric information in LiDAR point clouds. However, existing cross-modal knowledge distillation methods tend to overlook the inherent imperfections of LiDAR, such as the ambiguity of measurements on distant or occluded objects, which should not be transferred to the image detector. To mitigate these imperfections in LiDAR teacher, we propose a novel method that leverages aleatoric uncertainty-free features from ground truth labels. In contrast to conventional label guidance approaches, we approximate the inverse function of the teacher's head to effectively embed label inputs into feature space. This approach provides additional accurate guidance alongside LiDAR teacher, thereby boosting the performance of the image detector. Additionally, we introduce feature partitioning, which effectively transfers knowledge from the teacher modality while preserving the distinctive features of the student, thereby maximizing the potential of both modalities. Experimental results demonstrate that our approach improves mAP and NDS by 5.1 points and 4.9 points compared to the baseline model, proving the effectiveness of our approach. The code is available at https://github.com/sanmin0312/LabelDistill
RadarDistill: Boosting Radar-based Object Detection Performance via Knowledge Distillation from LiDAR Features
Mar 08, 2024The inherent noisy and sparse characteristics of radar data pose challenges in finding effective representations for 3D object detection. In this paper, we propose RadarDistill, a novel knowledge distillation (KD) method, which can improve the representation of radar data by leveraging LiDAR data. RadarDistill successfully transfers desirable characteristics of LiDAR features into radar features using three key components: Cross-Modality Alignment (CMA), Activation-based Feature Distillation (AFD), and Proposal-based Feature Distillation (PFD). CMA enhances the density of radar features through multiple layers of dilation operations, effectively addressing the challenges of inefficient knowledge transfer from LiDAR to radar. AFD is designed to transfer knowledge from significant areas of the LiDAR features, specifically those regions where activation intensity exceeds a predetermined threshold. PFD guides the radar network to mimic LiDAR network features in the object proposals for accurately detected results while moderating features for misdetected proposals like false positives. Our comparative analyses conducted on the nuScenes datasets demonstrate that RadarDistill achieves state-of-the-art (SOTA) performance for radar-only object detection task, recording 20.5% in mAP and 43.7% in NDS. Also, RadarDistill significantly improves the performance of the camera-radar fusion model.
RCM-Fusion: Radar-Camera Multi-Level Fusion for 3D Object Detection
Jul 27, 2023While LiDAR sensors have been succesfully applied to 3D object detection, the affordability of radar and camera sensors has led to a growing interest in fusiong radars and cameras for 3D object detection. However, previous radar-camera fusion models have not been able to fully utilize radar information in that initial 3D proposals were generated based on the camera features only and the instance-level fusion is subsequently conducted. In this paper, we propose radar-camera multi-level fusion (RCM-Fusion), which fuses radar and camera modalities at both the feature-level and instance-level to fully utilize radar information. At the feature-level, we propose a Radar Guided BEV Encoder which utilizes radar Bird's-Eye-View (BEV) features to transform image features into precise BEV representations and then adaptively combines the radar and camera BEV features. At the instance-level, we propose a Radar Grid Point Refinement module that reduces localization error by considering the characteristics of the radar point clouds. The experiments conducted on the public nuScenes dataset demonstrate that our proposed RCM-Fusion offers 11.8% performance gain in nuScenes detection score (NDS) over the camera-only baseline model and achieves state-of-the-art performaces among radar-camera fusion methods in the nuScenes 3D object detection benchmark. Code will be made publicly available.
Predict to Detect: Prediction-guided 3D Object Detection using Sequential Images
Jun 14, 2023Recent camera-based 3D object detection methods have introduced sequential frames to improve the detection performance hoping that multiple frames would mitigate the large depth estimation error. Despite improved detection performance, prior works rely on naive fusion methods (e.g., concatenation) or are limited to static scenes (e.g., temporal stereo), neglecting the importance of the motion cue of objects. These approaches do not fully exploit the potential of sequential images and show limited performance improvements. To address this limitation, we propose a novel 3D object detection model, P2D (Predict to Detect), that integrates a prediction scheme into a detection framework to explicitly extract and leverage motion features. P2D predicts object information in the current frame using solely past frames to learn temporal motion features. We then introduce a novel temporal feature aggregation method that attentively exploits Bird's-Eye-View (BEV) features based on predicted object information, resulting in accurate 3D object detection. Experimental results demonstrate that P2D improves mAP and NDS by 3.0% and 3.7% compared to the sequential image-based baseline, illustrating that incorporating a prediction scheme can significantly improve detection accuracy.
CRN: Camera Radar Net for Accurate, Robust, Efficient 3D Perception
Apr 03, 2023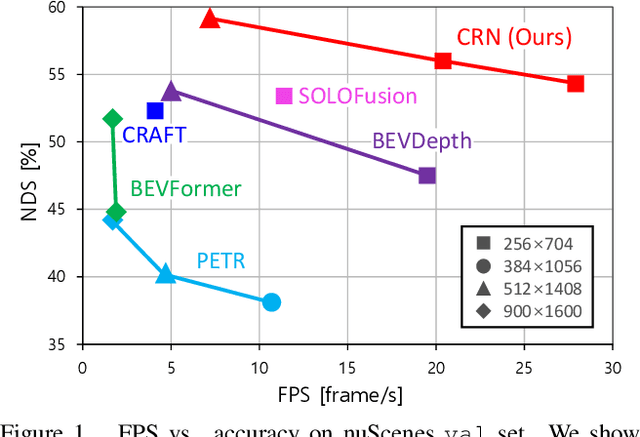
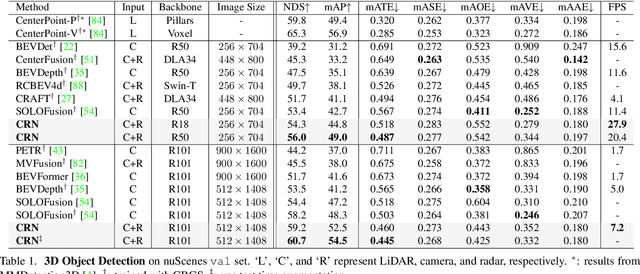
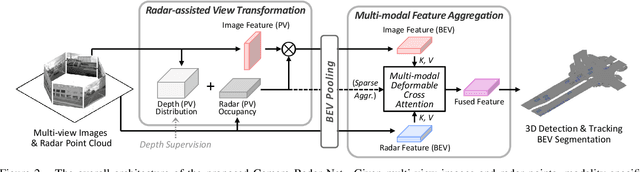
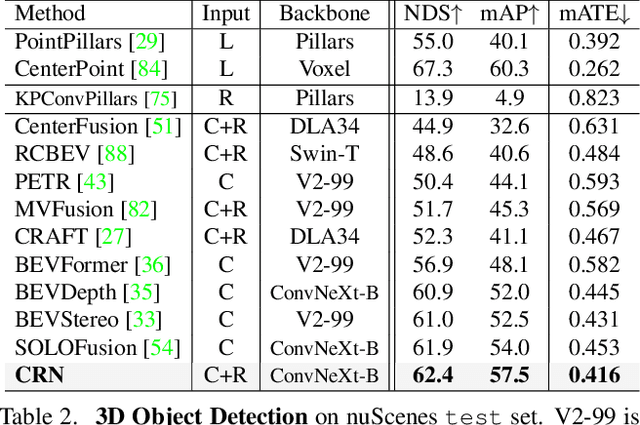
Autonomous driving requires an accurate and fast 3D perception system that includes 3D object detection, tracking, and segmentation. Although recent low-cost camera-based approaches have shown promising results, they are susceptible to poor illumination or bad weather conditions and have a large localization error. Hence, fusing camera with low-cost radar, which provides precise long-range measurement and operates reliably in all environments, is promising but has not yet been thoroughly investigated. In this paper, we propose Camera Radar Net (CRN), a novel camera-radar fusion framework that generates a semantically rich and spatially accurate bird's-eye-view (BEV) feature map for various tasks. To overcome the lack of spatial information in an image, we transform perspective view image features to BEV with the help of sparse but accurate radar points. We further aggregate image and radar feature maps in BEV using multi-modal deformable attention designed to tackle the spatial misalignment between inputs. CRN with real-time setting operates at 20 FPS while achieving comparable performance to LiDAR detectors on nuScenes, and even outperforms at a far distance on 100m setting. Moreover, CRN with offline setting yields 62.4% NDS, 57.5% mAP on nuScenes test set and ranks first among all camera and camera-radar 3D object detectors.
InstaGraM: Instance-level Graph Modeling for Vectorized HD Map Learning
Jan 10, 2023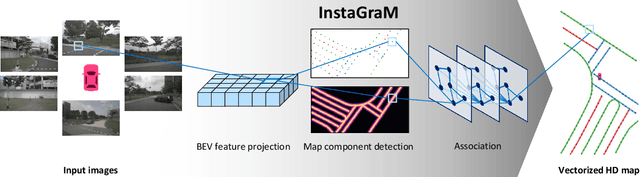
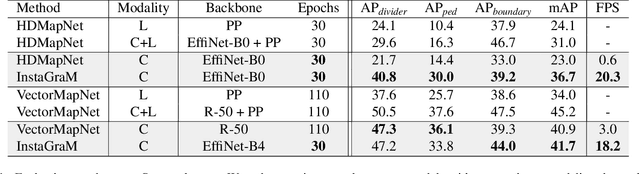
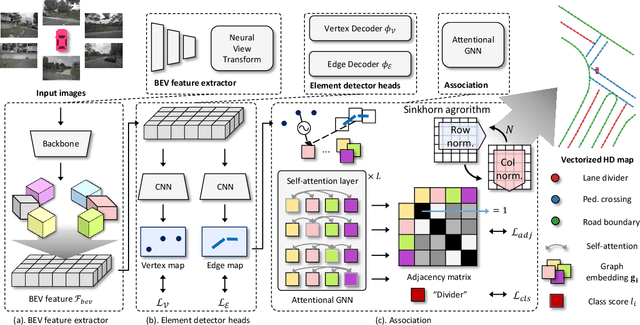
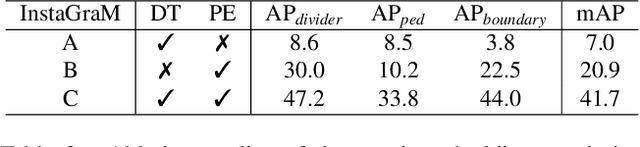
The construction of lightweight High-definition (HD) maps containing geometric and semantic information is of foremost importance for the large-scale deployment of autonomous driving. To automatically generate such type of map from a set of images captured by a vehicle, most works formulate this mapping as a segmentation problem, which implies heavy post-processing to obtain the final vectorized representation. Alternative techniques have the ability to generate an HD map in an end-to-end manner but rely on computationally expensive auto-regressive models. To bring camera-based to an applicable level, we propose InstaGraM, a fast end-to-end network generating a vectorized HD map via instance-level graph modeling of the map elements. Our strategy consists of three main stages: top-view feature extraction, road elements' vertices and edges detection, and conversion to a semantic vector representation. After top-down feature extraction, an encoder-decoder architecture is utilized to predict a set of vertices and edge maps of the road elements. Finally, these vertices along with edge maps are associated through an attentional graph neural network generating a semantic vectorized map. Instead of relying on a common segmentation approach, we propose to regress distance transform maps as they provide strong spatial relations and directional information between vertices. Comprehensive experiments on nuScenes dataset show that our proposed network outperforms HDMapNet by 13.7 mAP and achieves comparable accuracy with VectorMapNet 5x faster inference speed.
3D Dual-Fusion: Dual-Domain Dual-Query Camera-LiDAR Fusion for 3D Object Detection
Nov 24, 2022Fusing data from cameras and LiDAR sensors is an essential technique to achieve robust 3D object detection. One key challenge in camera-LiDAR fusion involves mitigating the large domain gap between the two sensors in terms of coordinates and data distribution when fusing their features. In this paper, we propose a novel camera-LiDAR fusion architecture called, 3D Dual-Fusion, which is designed to mitigate the gap between the feature representations of camera and LiDAR data. The proposed method fuses the features of the camera-view and 3D voxel-view domain and models their interactions through deformable attention. We redesign the transformer fusion encoder to aggregate the information from the two domains. Two major changes include 1) dual query-based deformable attention to fuse the dual-domain features interactively and 2) 3D local self-attention to encode the voxel-domain queries prior to dual-query decoding. The results of an experimental evaluation show that the proposed camera-LiDAR fusion architecture achieved competitive performance on the KITTI and nuScenes datasets, with state-of-the-art performances in some 3D object detection benchmarks categories.