 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining Instance-Centric Vision-Language Contexts for Human-Object Interaction Detection
Apr 02, 2026Human-Object Interaction (HOI) detection aims to localize human-object pairs and classify their interactions from a single image, a task that demands strong visual understanding and nuanced contextual reasoning. Recent approaches have leveraged Vision-Language Models (VLMs) to introduce semantic priors, significantly improving HOI detection performance. However, existing methods often fail to fully capitalize on the diverse contextual cues distributed across the entire scene. To overcome these limitations, we propose the Instance-centric Context Mining Network (InCoM-Net)-a novel framework that effectively integrates rich semantic knowledge extracted from VLMs with instance-specific features produced by an object detector. This design enables deeper interaction reasoning by modeling relationships not only within each detected instance but also across instances and their surrounding scene context. InCoM-Net comprises two core components: Instancecentric Context Refinement (ICR), which separately extracts intra-instance, inter-instance, and global contextual cues from VLM-derived features, and Progressive Context Aggregation (ProCA), which iteratively fuses these multicontext features with instance-level detector features to support high-level HOI reasoning. Extensive experiments on the HICO-DET and V-COCO benchmarks show that InCoM-Net achieves state-of-the-art performance, surpassing previous HOI detection methods. Code is available at https://github.com/nowuss/InCoM-Net.
CarPLAN: Context-Adaptive and Robust Planning with Dynamic Scene Awareness for Autonomous Driving
Mar 13, 2026Imitation learning (IL) is widely used for motion planning in autonomous driving due to its data efficiency and access to real-world driving data. For safe and robust real-world driving, IL-based planning requires capturing the complex driving contexts inherent in real-world data and enabling context-adaptive decision-making, rather than relying solely on expert trajectory imitation. In this paper, we propose CarPLAN, a novel IL-based motion planning framework that explicitly enhances driving context understanding and enables adaptive planning across diverse traffic scenarios. Our contributions are twofold: We introduce Displacement-Aware Predictive Encoding (DPE) to improve the model's spatial awareness by predicting future displacement vectors between the Autonomous Vehicle (AV) and surrounding scene elements. This allows the planner to account for relational spacing when generating trajectories. In addition to the standard imitation loss, we incorporate an augmented loss term that captures displacement prediction errors, ensuring planning decisions consider relative distances from other agents. To improve the model's ability to handle diverse driving contexts, we propose Context-Adaptive Multi-Expert Decoder (CMD), which leverages the Mixture of Experts (MoE) framework. CMD dynamically selects the most suitable expert decoders based on scene structure at each Transformer layer, enabling adaptive and context-aware planning in dynamic environments. We evaluate CarPLAN on the nuPlan benchmark and demonstrate state-of-the-art performance across all closed-loop simulation metrics. In particular, CarPLAN exhibits robust performance on challenging scenarios such as Test14-Hard, validating its effectiveness in complex driving conditions. Additional experiments on the Waymax benchmark further demonstrate its generalization capability across different benchmark settings.
STONE Dataset: A Scalable Multi-Modal Surround-View 3D Traversability Dataset for Off-Road Robot Navigation
Mar 12, 2026Reliable off-road navigation requires accurate estimation of traversable regions and robust perception under diverse terrain and sensing conditions. However, existing datasets lack both scalability and multi-modality, which limits progress in 3D traversability prediction. In this work, we introduce STONE, a large-scale multi-modal dataset for off-road navigation. STONE provides (1) trajectory-guided 3D traversability maps generated by a fully automated, annotation-free pipeline, and (2) comprehensive surround-view sensing with synchronized 128-channel LiDAR, six RGB cameras, and three 4D imaging radars. The dataset covers a wide range of environments and conditions, including day and night, grasslands, farmlands, construction sites, and lakes. Our auto-labeling pipeline reconstructs dense terrain surfaces from LiDAR scans, extracts geometric attributes such as slope, elevation, and roughness, and assigns traversability labels beyond the robot's trajectory using a Mahalanobis-distance-based criterion. This design enables scalable, geometry-aware ground-truth construction without manual annotation. Finally, we establish a benchmark for voxel-level 3D traversability prediction and provide strong baselines under both single-modal and multi-modal settings. STONE is available at: https://konyul.github.io/STONE-dataset/
Resilient Sensor Fusion under Adverse Sensor Failures via Multi-Modal Expert Fusion
Mar 25, 2025Modern autonomous driving perception systems utilize complementary multi-modal sensors, such as LiDAR and cameras. Although sensor fusion architectures enhance performance in challenging environments, they still suffer significant performance drops under severe sensor failures, such as LiDAR beam reduction, LiDAR drop, limited field of view, camera drop, and occlusion. This limitation stems from inter-modality dependencies in current sensor fusion frameworks. In this study, we introduce an efficient and robust LiDAR-camera 3D object detector, referred to as MoME, which can achieve robust performance through a mixture of experts approach. Our MoME fully decouples modality dependencies using three parallel expert decoders, which use camera features, LiDAR features, or a combination of both to decode object queries, respectively. We propose Multi-Expert Decoding (MED) framework, where each query is decoded selectively using one of three expert decoders. MoME utilizes an Adaptive Query Router (AQR) to select the most appropriate expert decoder for each query based on the quality of camera and LiDAR features. This ensures that each query is processed by the best-suited expert, resulting in robust performance across diverse sensor failure scenarios. We evaluated the performance of MoME on the nuScenes-R benchmark. Our MoME achieved state-of-the-art performance in extreme weather and sensor failure conditions, significantly outperforming the existing models across various sensor failure scenarios.
MR-Occ: Efficient Camera-LiDAR 3D Semantic Occupancy Prediction Using Hierarchical Multi-Resolution Voxel Representation
Dec 29, 2024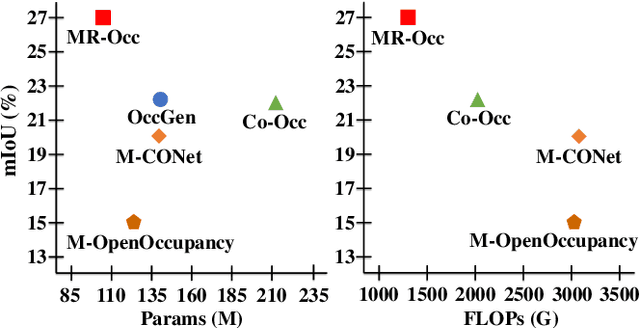
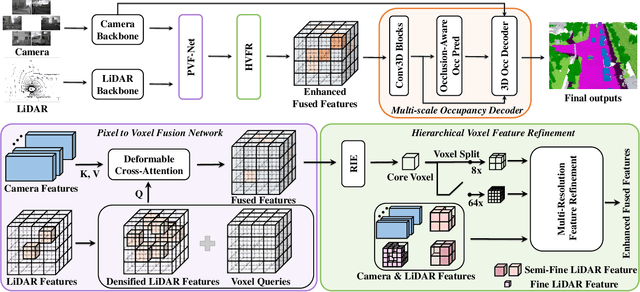
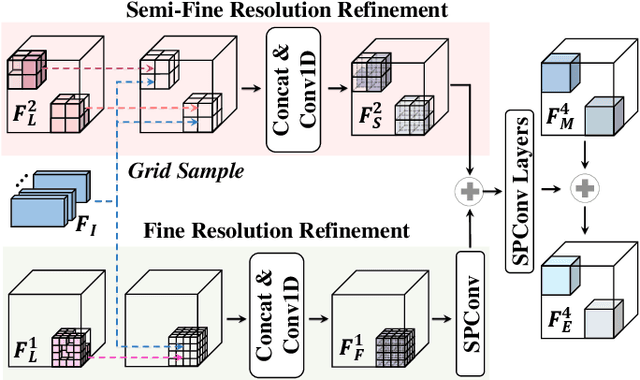
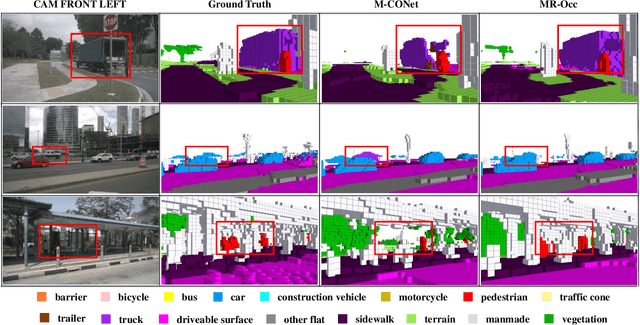
Accurate 3D perception is essential for understanding the environment in autonomous driving. Recent advancements in 3D semantic occupancy prediction have leveraged camera-LiDAR fusion to improve robustness and accuracy. However, current methods allocate computational resources uniformly across all voxels, leading to inefficiency, and they also fail to adequately address occlusions, resulting in reduced accuracy in challenging scenarios. We propose MR-Occ, a novel approach for camera-LiDAR fusion-based 3D semantic occupancy prediction, addressing these challenges through three key components: Hierarchical Voxel Feature Refinement (HVFR), Multi-scale Occupancy Decoder (MOD), and Pixel to Voxel Fusion Network (PVF-Net). HVFR improves performance by enhancing features for critical voxels, reducing computational cost. MOD introduces an `occluded' class to better handle regions obscured from sensor view, improving accuracy. PVF-Net leverages densified LiDAR features to effectively fuse camera and LiDAR data through a deformable attention mechanism. Extensive experiments demonstrate that MR-Occ achieves state-of-the-art performance on the nuScenes-Occupancy dataset, surpassing previous approaches by +5.2% in IoU and +5.3% in mIoU while using fewer parameters and FLOPs. Moreover, MR-Occ demonstrates superior performance on the SemanticKITTI dataset, further validating its effectiveness and generalizability across diverse 3D semantic occupancy benchmarks.
JoVALE: Detecting Human Actions in Video Using Audiovisual and Language Contexts
Dec 18, 2024Video Action Detection (VAD) involves localizing and categorizing action instances in videos. Videos inherently contain various information sources, including audio, visual cues, and surrounding scene contexts. Effectively leveraging this multi-modal information for VAD is challenging, as the model must accurately focus on action-relevant cues. In this study, we introduce a novel multi-modal VAD architecture called the Joint Actor-centric Visual, Audio, Language Encoder (JoVALE). JoVALE is the first VAD method to integrate audio and visual features with scene descriptive context derived from large image captioning models. The core principle of JoVALE is the actor-centric aggregation of audio, visual, and scene descriptive contexts, where action-related cues from each modality are identified and adaptively combined. We propose a specialized module called the Actor-centric Multi-modal Fusion Network, designed to capture the joint interactions among actors and multi-modal contexts through Transformer architecture. Our evaluation conducted on three popular VAD benchmarks, AVA, UCF101-24, and JHMDB51-21, demonstrates that incorporating multi-modal information leads to significant performance gains. JoVALE achieves state-of-the-art performances. The code will be available at \texttt{https://github.com/taeiin/AAAI2025-JoVALE}.
ProtoOcc: Accurate, Efficient 3D Occupancy Prediction Using Dual Branch Encoder-Prototype Query Decoder
Dec 11, 2024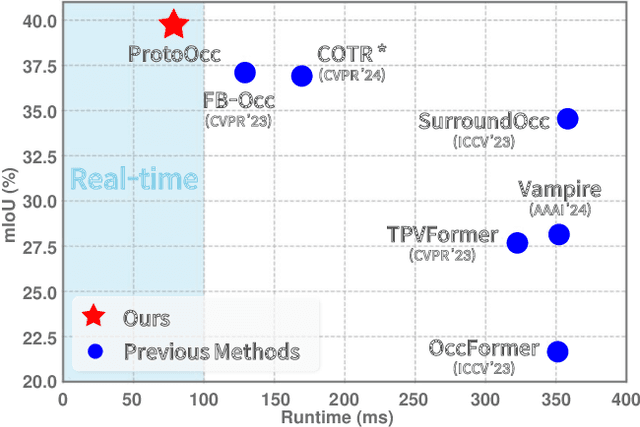
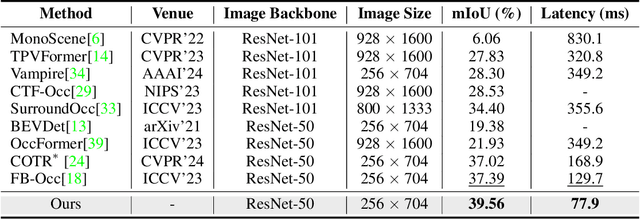
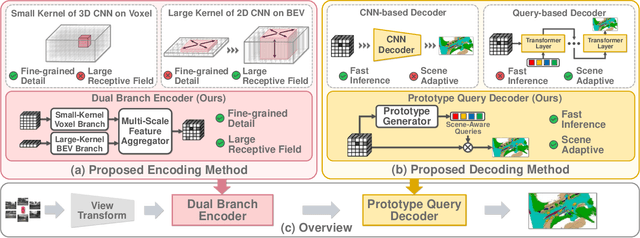
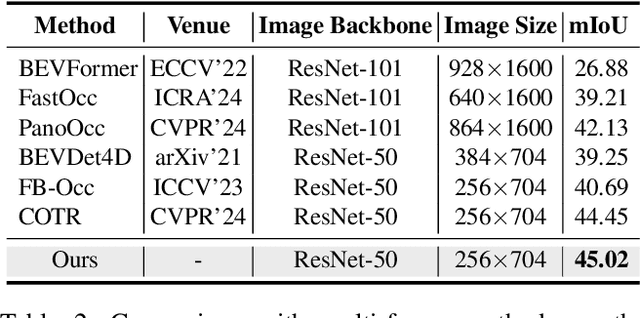
In this paper, we introduce ProtoOcc, a novel 3D occupancy prediction model designed to predict the occupancy states and semantic classes of 3D voxels through a deep semantic understanding of scenes. ProtoOcc consists of two main components: the Dual Branch Encoder (DBE) and the Prototype Query Decoder (PQD). The DBE produces a new 3D voxel representation by combining 3D voxel and BEV representations across multiple scales through a dual branch structure. This design enhances both performance and computational efficiency by providing a large receptive field for the BEV representation while maintaining a smaller receptive field for the voxel representation. The PQD introduces Prototype Queries to accelerate the decoding process. Scene-Adaptive Prototypes are derived from the 3D voxel features of input sample, while Scene-Agnostic Prototypes are computed by applying Scene-Adaptive Prototypes to an Exponential Moving Average during the training phase. By using these prototype-based queries for decoding, we can directly predict 3D occupancy in a single step, eliminating the need for iterative Transformer decoding. Additionally, we propose the Robust Prototype Learning, which injects noise into prototype generation process and trains the model to denoise during the training phase. ProtoOcc achieves state-of-the-art performance with 45.02% mIoU on the Occ3D-nuScenes benchmark. For single-frame method, it reaches 39.56% mIoU with an inference speed of 12.83 FPS on an NVIDIA RTX 3090. Our code can be found at https://github.com/SPA-junghokim/ProtoOcc.
CRT-Fusion: Camera, Radar, Temporal Fusion Using Motion Information for 3D Object Detection
Nov 05, 2024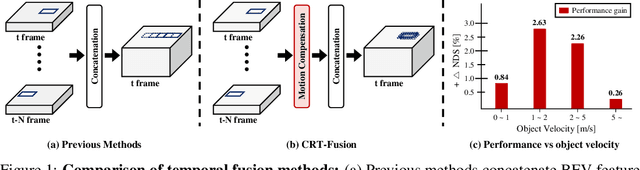
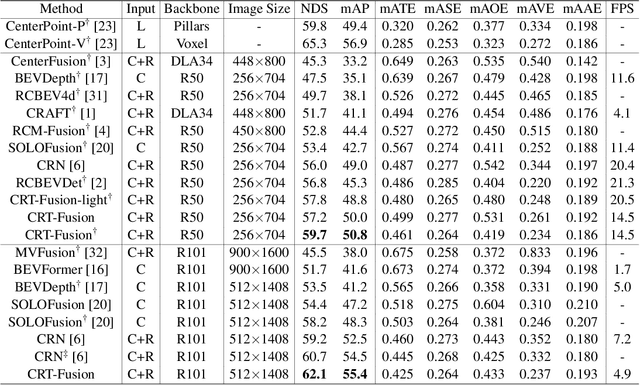
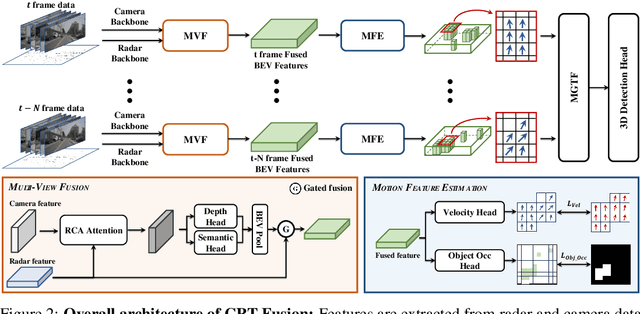
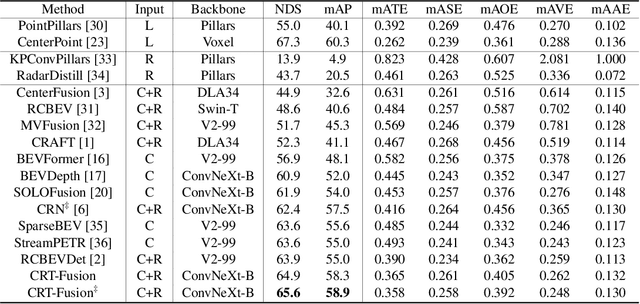
Accurate and robust 3D object detection is a critical component in autonomous vehicles and robotics. While recent radar-camera fusion methods have made significant progress by fusing information in the bird's-eye view (BEV) representation, they often struggle to effectively capture the motion of dynamic objects, leading to limited performance in real-world scenarios. In this paper, we introduce CRT-Fusion, a novel framework that integrates temporal information into radar-camera fusion to address this challenge. Our approach comprises three key modules: Multi-View Fusion (MVF), Motion Feature Estimator (MFE), and Motion Guided Temporal Fusion (MGTF). The MVF module fuses radar and image features within both the camera view and bird's-eye view, thereby generating a more precise unified BEV representation. The MFE module conducts two simultaneous tasks: estimation of pixel-wise velocity information and BEV segmentation. Based on the velocity and the occupancy score map obtained from the MFE module, the MGTF module aligns and fuses feature maps across multiple timestamps in a recurrent manner. By considering the motion of dynamic objects, CRT-Fusion can produce robust BEV feature maps, thereby improving detection accuracy and robustness. Extensive evaluations on the challenging nuScenes dataset demonstrate that CRT-Fusion achieves state-of-the-art performance for radar-camera-based 3D object detection. Our approach outperforms the previous best method in terms of NDS by +1.7%, while also surpassing the leading approach in mAP by +1.4%. These significant improvements in both metrics showcase the effectiveness of our proposed fusion strategy in enhancing the reliability and accuracy of 3D object detection.
JARViS: Detecting Actions in Video Using Unified Actor-Scene Context Relation Modeling
Aug 07, 2024



Video action detection (VAD) is a formidable vision task that involves the localization and classification of actions within the spatial and temporal dimensions of a video clip. Among the myriad VAD architectures, two-stage VAD methods utilize a pre-trained person detector to extract the region of interest features, subsequently employing these features for action detection. However, the performance of two-stage VAD methods has been limited as they depend solely on localized actor features to infer action semantics. In this study, we propose a new two-stage VAD framework called Joint Actor-scene context Relation modeling based on Visual Semantics (JARViS), which effectively consolidates cross-modal action semantics distributed globally across spatial and temporal dimensions using Transformer attention. JARViS employs a person detector to produce densely sampled actor features from a keyframe. Concurrently, it uses a video backbone to create spatio-temporal scene features from a video clip. Finally, the fine-grained interactions between actors and scenes are modeled through a Unified Action-Scene Context Transformer to directly output the final set of actions in parallel. Our experimental results demonstrate that JARViS outperforms existing methods by significant margins and achieves state-of-the-art performance on three popular VAD datasets, including AVA, UCF101-24, and JHMDB51-21.
Distribution-Aware Robust Learning from Long-Tailed Data with Noisy Labels
Jul 23, 2024Deep neural networks have demonstrated remarkable advancements in various fields using large, well-annotated datasets. However, real-world data often exhibit long-tailed distributions and label noise, significantly degrading generalization performance. Recent studies addressing these issues have focused on noisy sample selection methods that estimate the centroid of each class based on high-confidence samples within each target class. The performance of these methods is limited because they use only the training samples within each class for class centroid estimation, making the quality of centroids susceptible to long-tailed distributions and noisy labels. In this study, we present a robust training framework called Distribution-aware Sample Selection and Contrastive Learning (DaSC). Specifically, DaSC introduces a Distribution-aware Class Centroid Estimation (DaCC) to generate enhanced class centroids. DaCC performs weighted averaging of the features from all samples, with weights determined based on model predictions. Additionally, we propose a confidence-aware contrastive learning strategy to obtain balanced and robust representations. The training samples are categorized into high-confidence and low-confidence samples. Our method then applies Semi-supervised Balanced Contrastive Loss (SBCL) using high-confidence samples, leveraging reliable label information to mitigate class bias. For the low-confidence samples, our method computes Mixup-enhanced Instance Discrimination Loss (MIDL) to improve their representations in a self-supervised manner. Our experimental results on CIFAR and real-world noisy-label datasets demonstrate the superior performance of the proposed DaSC compared to previous approaches.