 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution-Aware Robust Learning from Long-Tailed Data with Noisy Labels
Jul 23, 2024Deep neural networks have demonstrated remarkable advancements in various fields using large, well-annotated datasets. However, real-world data often exhibit long-tailed distributions and label noise, significantly degrading generalization performance. Recent studies addressing these issues have focused on noisy sample selection methods that estimate the centroid of each class based on high-confidence samples within each target class. The performance of these methods is limited because they use only the training samples within each class for class centroid estimation, making the quality of centroids susceptible to long-tailed distributions and noisy labels. In this study, we present a robust training framework called Distribution-aware Sample Selection and Contrastive Learning (DaSC). Specifically, DaSC introduces a Distribution-aware Class Centroid Estimation (DaCC) to generate enhanced class centroids. DaCC performs weighted averaging of the features from all samples, with weights determined based on model predictions. Additionally, we propose a confidence-aware contrastive learning strategy to obtain balanced and robust representations. The training samples are categorized into high-confidence and low-confidence samples. Our method then applies Semi-supervised Balanced Contrastive Loss (SBCL) using high-confidence samples, leveraging reliable label information to mitigate class bias. For the low-confidence samples, our method computes Mixup-enhanced Instance Discrimination Loss (MIDL) to improve their representations in a self-supervised manner. Our experimental results on CIFAR and real-world noisy-label datasets demonstrate the superior performance of the proposed DaSC compared to previous approaches.
ST-CoNAL: Consistency-Based Acquisition Criterion Using Temporal Self-Ensemble for Active Learning
Jul 05, 2022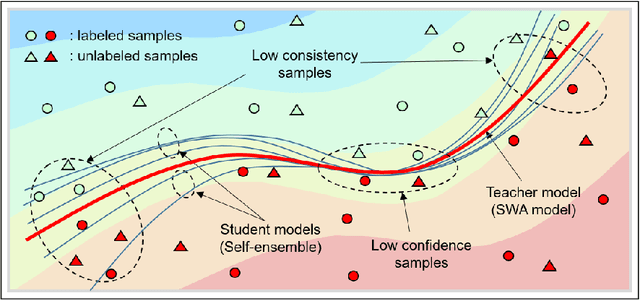
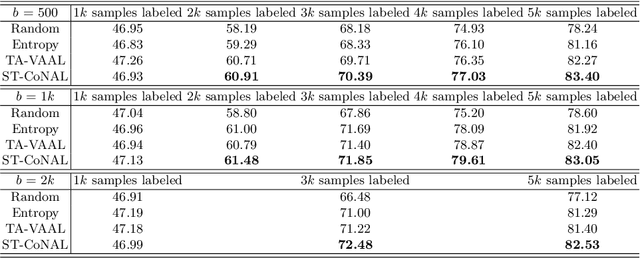
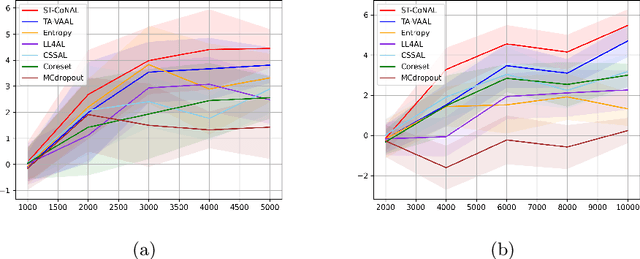
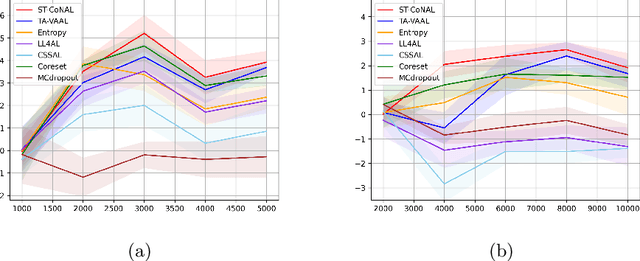
Modern deep learning has achieved great success in various fields. However, it requires the labeling of huge amounts of data, which is expensive and labor-intensive. Active learning (AL), which identifies the most informative samples to be labeled, is becoming increasingly important to maximize the efficiency of the training process. The existing AL methods mostly use only a single final fixed model for acquiring the samples to be labeled. This strategy may not be good enough in that the structural uncertainty of a model for given training data is not considered to acquire the samples. In this study, we propose a novel acquisition criterion based on temporal self-ensemble generated by conventional stochastic gradient descent (SGD) optimization. These self-ensemble models are obtained by capturing the intermediate network weights obtained through SGD iterations. Our acquisition function relies on a consistency measure between the student and teacher models. The student models are given a fixed number of temporal self-ensemble models, and the teacher model is constructed by averaging the weights of the student models. Using the proposed acquisition criterion, we present an AL algorithm, namely student-teacher consistency-based AL (ST-CoNAL). Experiments conducted for image classification tasks on CIFAR-10, CIFAR-100, Caltech-256, and Tiny ImageNet datasets demonstrate that the proposed ST-CoNAL achieves significantly better performance than the existing acquisition methods. Furthermore, extensive experiments show the robustness and effectiveness of our methods.
DBN-Mix: Training Dual Branch Network Using Bilateral Mixup Augmentation for Long-Tailed Visual Recognition
Jul 05, 2022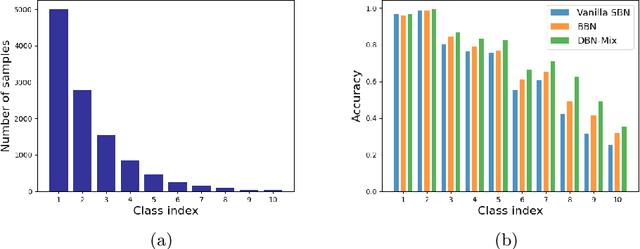
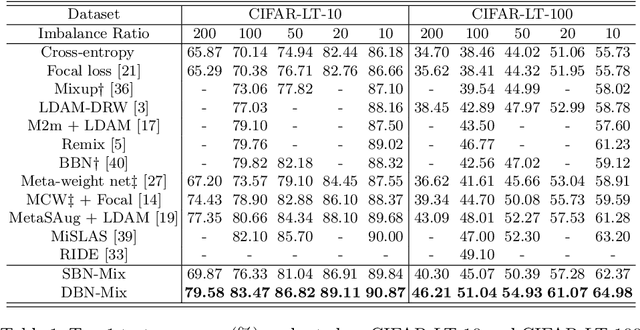
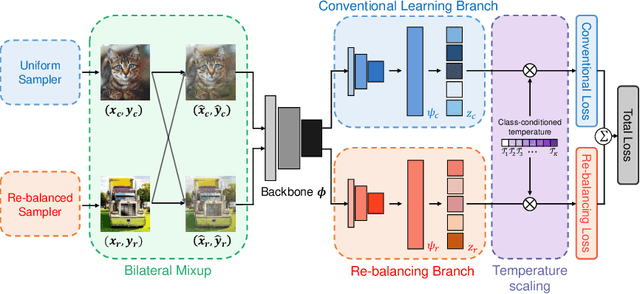
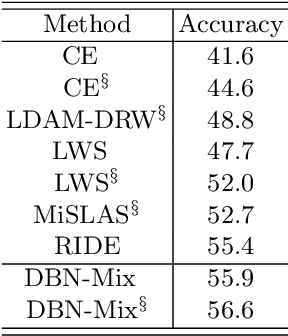
There is a growing interest in the challenging visual perception task of learning from long-tailed class distributions. The extreme class imbalance in the training dataset biases the model to prefer to recognize majority-class data over minority-class data. Recently, the dual branch network (DBN) framework has been proposed, where two branch networks; the conventional branch and the re-balancing branch were employed to improve the accuracy of long-tailed visual recognition. The re-balancing branch uses a reverse sampler to generate class-balanced training samples to mitigate bias due to class imbalance. Although this strategy has been quite successful in handling bias, using a reversed sampler for training can degrade the representation learning performance. To alleviate this issue, the conventional method used a carefully designed cumulative learning strategy, in which the influence of the re-balancing branch gradually increases throughout the entire training phase. In this study, we aim to develop a simple yet effective method to improve the performance of DBN without cumulative learning that is difficult to optimize. We devise a simple data augmentation method termed bilateral mixup augmentation, which combines one sample from the uniform sampler with another sample from the reversed sampler to produce a training sample. Furthermore, we present class-conditional temperature scaling that mitigates bias toward the majority class for the proposed DBN architecture. Our experiments performed on widely used long-tailed visual recognition datasets show that bilateral mixup augmentation is quite effective in improving the representation learning performance of DBNs, and that the proposed method achieves state-of-the-art performance for some categories.