 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarPLAN: Context-Adaptive and Robust Planning with Dynamic Scene Awareness for Autonomous Driving
Mar 13, 2026Imitation learning (IL) is widely used for motion planning in autonomous driving due to its data efficiency and access to real-world driving data. For safe and robust real-world driving, IL-based planning requires capturing the complex driving contexts inherent in real-world data and enabling context-adaptive decision-making, rather than relying solely on expert trajectory imitation. In this paper, we propose CarPLAN, a novel IL-based motion planning framework that explicitly enhances driving context understanding and enables adaptive planning across diverse traffic scenarios. Our contributions are twofold: We introduce Displacement-Aware Predictive Encoding (DPE) to improve the model's spatial awareness by predicting future displacement vectors between the Autonomous Vehicle (AV) and surrounding scene elements. This allows the planner to account for relational spacing when generating trajectories. In addition to the standard imitation loss, we incorporate an augmented loss term that captures displacement prediction errors, ensuring planning decisions consider relative distances from other agents. To improve the model's ability to handle diverse driving contexts, we propose Context-Adaptive Multi-Expert Decoder (CMD), which leverages the Mixture of Experts (MoE) framework. CMD dynamically selects the most suitable expert decoders based on scene structure at each Transformer layer, enabling adaptive and context-aware planning in dynamic environments. We evaluate CarPLAN on the nuPlan benchmark and demonstrate state-of-the-art performance across all closed-loop simulation metrics. In particular, CarPLAN exhibits robust performance on challenging scenarios such as Test14-Hard, validating its effectiveness in complex driving conditions. Additional experiments on the Waymax benchmark further demonstrate its generalization capability across different benchmark settings.
ProtoOcc: Accurate, Efficient 3D Occupancy Prediction Using Dual Branch Encoder-Prototype Query Decoder
Dec 11, 2024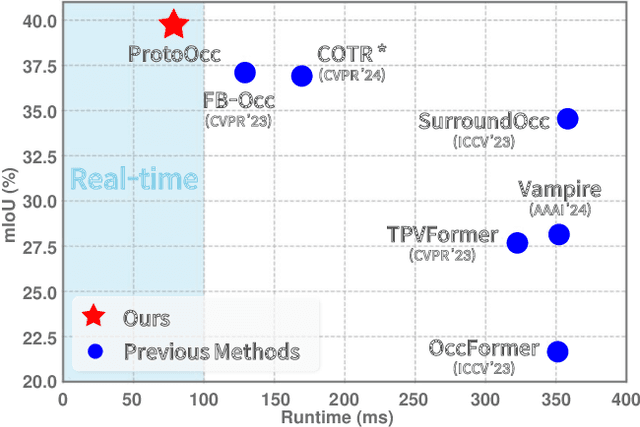
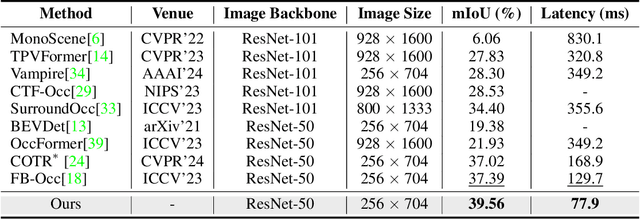
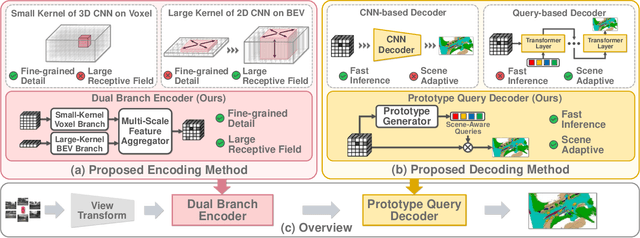
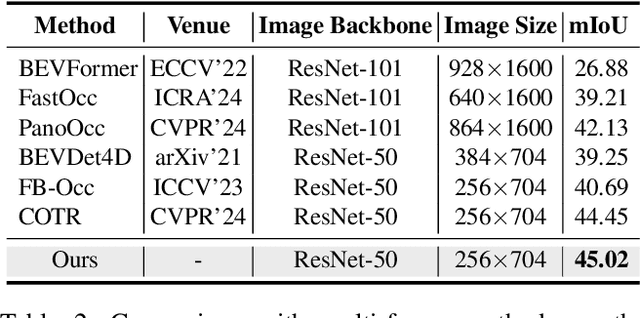
In this paper, we introduce ProtoOcc, a novel 3D occupancy prediction model designed to predict the occupancy states and semantic classes of 3D voxels through a deep semantic understanding of scenes. ProtoOcc consists of two main components: the Dual Branch Encoder (DBE) and the Prototype Query Decoder (PQD). The DBE produces a new 3D voxel representation by combining 3D voxel and BEV representations across multiple scales through a dual branch structure. This design enhances both performance and computational efficiency by providing a large receptive field for the BEV representation while maintaining a smaller receptive field for the voxel representation. The PQD introduces Prototype Queries to accelerate the decoding process. Scene-Adaptive Prototypes are derived from the 3D voxel features of input sample, while Scene-Agnostic Prototypes are computed by applying Scene-Adaptive Prototypes to an Exponential Moving Average during the training phase. By using these prototype-based queries for decoding, we can directly predict 3D occupancy in a single step, eliminating the need for iterative Transformer decoding. Additionally, we propose the Robust Prototype Learning, which injects noise into prototype generation process and trains the model to denoise during the training phase. ProtoOcc achieves state-of-the-art performance with 45.02% mIoU on the Occ3D-nuScenes benchmark. For single-frame method, it reaches 39.56% mIoU with an inference speed of 12.83 FPS on an NVIDIA RTX 3090. Our code can be found at https://github.com/SPA-junghokim/ProtoOcc.
Mask2Map: Vectorized HD Map Construction Using Bird's Eye View Segmentation Masks
Jul 19, 2024In this paper, we introduce Mask2Map, a novel end-to-end online HD map construction method designed for autonomous driving applications. Our approach focuses on predicting the class and ordered point set of map instances within a scene, represented in the bird's eye view (BEV). Mask2Map consists of two primary components: the Instance-Level Mask Prediction Network (IMPNet) and the Mask-Driven Map Prediction Network (MMPNet). IMPNet generates Mask-Aware Queries and BEV Segmentation Masks to capture comprehensive semantic information globally. Subsequently, MMPNet enhances these query features using local contextual information through two submodules: the Positional Query Generator (PQG) and the Geometric Feature Extractor (GFE). PQG extracts instance-level positional queries by embedding BEV positional information into Mask-Aware Queries, while GFE utilizes BEV Segmentation Masks to generate point-level geometric features. However, we observed limited performance in Mask2Map due to inter-network inconsistency stemming from different predictions to Ground Truth (GT) matching between IMPNet and MMPNet. To tackle this challenge, we propose the Inter-network Denoising Training method, which guides the model to denoise the output affected by both noisy GT queries and perturbed GT Segmentation Masks. Our evaluation conducted on nuScenes and Argoverse2 benchmarks demonstrates that Mask2Map achieves remarkable performance improvements over previous state-of-the-art methods, with gains of 10.1% mAP and 4.1 mAP, respectively. Our code can be found at https://github.com/SehwanChoi0307/Mask2Map.
R-Pred: Two-Stage Motion Prediction Via Tube-Query Attention-Based Trajectory Refinement
Nov 21, 2022



Predicting the future motion of dynamic agents is of paramount importance to ensure safety or assess risks in motion planning for autonomous robots. In this paper, we propose a two-stage motion prediction method, referred to as R-Pred, that effectively utilizes both the scene and interaction context using a cascade of the initial trajectory proposal network and the trajectory refinement network. The initial trajectory proposal network produces M trajectory proposals corresponding to M modes of a future trajectory distribution. The trajectory refinement network enhances each of M proposals using 1) the tube-query scene attention (TQSA) and 2) the proposal-level interaction attention (PIA). TQSA uses tube-queries to aggregate the local scene context features pooled from proximity around the trajectory proposals of interest. PIA further enhances the trajectory proposals by modeling inter-agent interactions using a group of trajectory proposals selected based on their distances from neighboring agents. Our experiments conducted on the Argoverse and nuScenes datasets demonstrate that the proposed refinement network provides significant performance improvements compared to the single-stage baseline and that R-Pred achieves state-of-the-art performance in some categories of the benchmark.