 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelectively Dilated Convolution for Accuracy-Preserving Sparse Pillar-based Embedded 3D Object Detection
Aug 25, 2024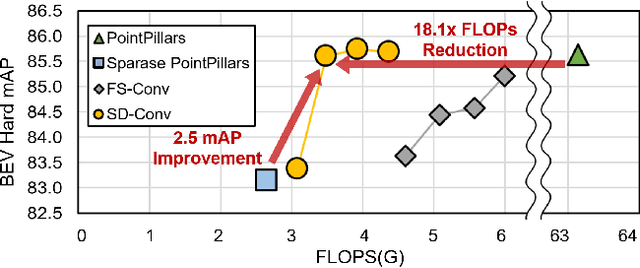


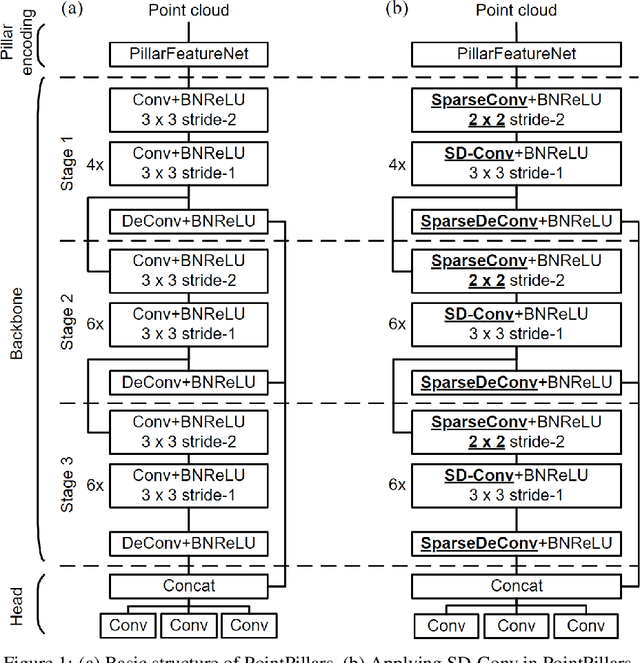
Pillar-based 3D object detection has gained traction in self-driving technology due to its speed and accuracy facilitated by the artificial densification of pillars for GPU-friendly processing. However, dense pillar processing fundamentally wastes computation since it ignores the inherent sparsity of pillars derived from scattered point cloud data. Motivated by recent embedded accelerators with native sparsity support, sparse pillar convolution methods like submanifold convolution (SubM-Conv) aimed to reduce these redundant computations by applying convolution only on active pillars but suffered considerable accuracy loss. Our research identifies that this accuracy loss is due to the restricted fine-grained spatial information flow (fSIF) of SubM-Conv in sparse pillar networks. To overcome this restriction, we propose a selectively dilated (SD-Conv) convolution that evaluates the importance of encoded pillars and selectively dilates the convolution output, enhancing the receptive field for critical pillars and improving object detection accuracy. To facilitate actual acceleration with this novel convolution approach, we designed SPADE+ as a cost-efficient augmentation to existing embedded sparse convolution accelerators. This design supports the SD-Conv without significant demands in area and SRAM size, realizing superior trade-off between the speedup and model accuracy. This strategic enhancement allows our method to achieve extreme pillar sparsity, leading to up to 18.1x computational savings and 16.2x speedup on the embedded accelerators, without compromising object detection accuracy.
PillarAcc: Sparse PointPillars Accelerator for Real-Time Point Cloud 3D Object Detection on Edge Devices
May 15, 2023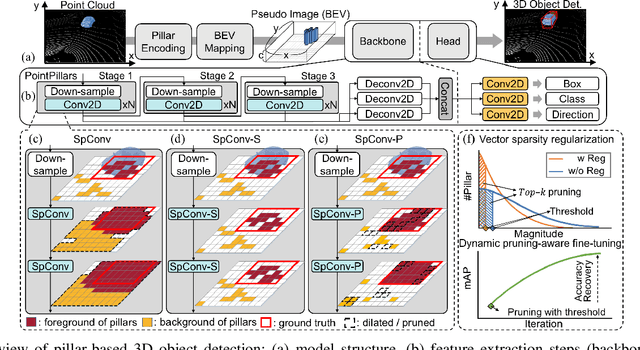
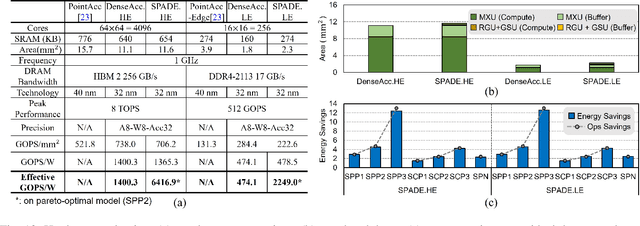
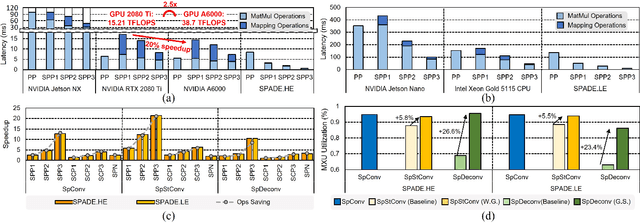
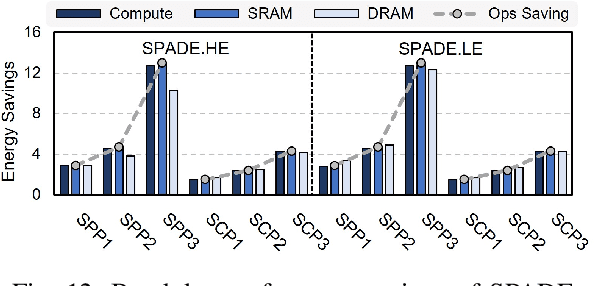
3D object detection using point cloud (PC) data is vital for autonomous driving perception pipelines, where efficient encoding is key to meeting stringent resource and latency requirements. PointPillars, a widely adopted bird's-eye view (BEV) encoding, aggregates 3D point cloud data into 2D pillars for high-accuracy 3D object detection. However, most state-of-the-art methods employing PointPillar overlook the inherent sparsity of pillar encoding, missing opportunities for significant computational reduction. In this study, we propose a groundbreaking algorithm-hardware co-design that accelerates sparse convolution processing and maximizes sparsity utilization in pillar-based 3D object detection networks. We investigate sparsification opportunities using an advanced pillar-pruning method, achieving an optimal balance between accuracy and sparsity. We introduce PillarAcc, a state-of-the-art sparsity support mechanism that enhances sparse pillar convolution through linear complexity input-output mapping generation and conflict-free gather-scatter memory access. Additionally, we propose dataflow optimization techniques, dynamically adjusting the pillar processing schedule for optimal hardware utilization under diverse sparsity operations. We evaluate PillarAcc on various cutting-edge 3D object detection networks and benchmarks, achieving remarkable speedup and energy savings compared to representative edge platforms, demonstrating record-breaking PointPillars speed of 500FPS with minimal compromise in accuracy.
Improving Diversity of Multiple Trajectory Prediction based on Map-adaptive Lane Loss
Jun 17, 2022
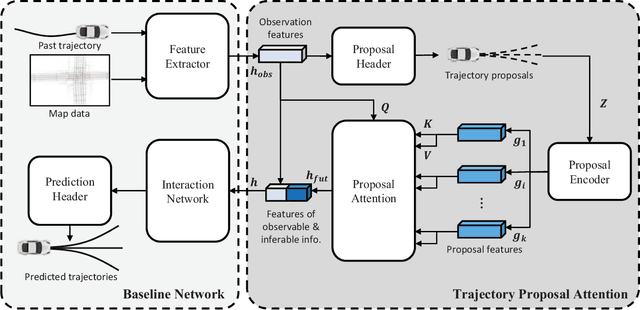
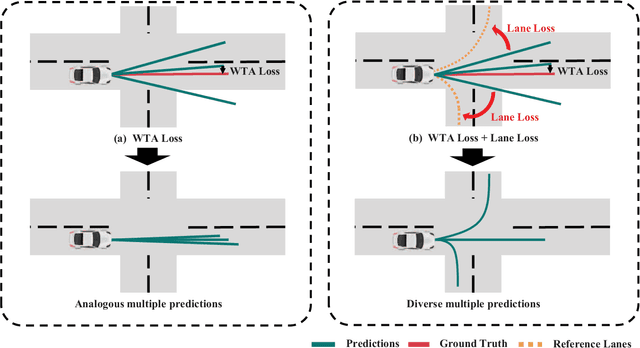

Prior arts in the field of motion predictions for autonomous driving tend to focus on finding a trajectory that is close to the ground truth trajectory. Such problem formulations and approaches, however, frequently lead to loss of diversity and biased trajectory predictions. Therefore, they are unsuitable for real-world autonomous driving where diverse and road-dependent multimodal trajectory predictions are critical for safety. To this end, this study proposes a novel loss function, \textit{Lane Loss}, that ensures map-adaptive diversity and accommodates geometric constraints. A two-stage trajectory prediction architecture with a novel trajectory candidate proposal module, \textit{Trajectory Prediction Attention (TPA)}, is trained with Lane Loss encourages multiple trajectories to be diversely distributed, covering feasible maneuvers in a map-aware manner. Furthermore, considering that the existing trajectory performance metrics are focusing on evaluating the accuracy based on the ground truth future trajectory, a quantitative evaluation metric is also suggested to evaluate the diversity of predicted multiple trajectories. The experiments performed on the Argoverse dataset show that the proposed method significantly improves the diversity of the predicted trajectories without sacrificing the prediction accuracy.
SCALE-Net: Scalable Vehicle Trajectory Prediction Network under Random Number of Interacting Vehicles via Edge-enhanced Graph Convolutional Neural Network
Feb 28, 2020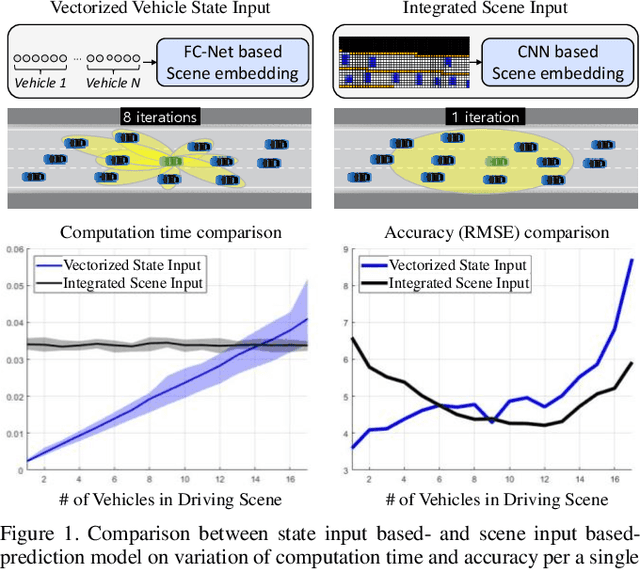

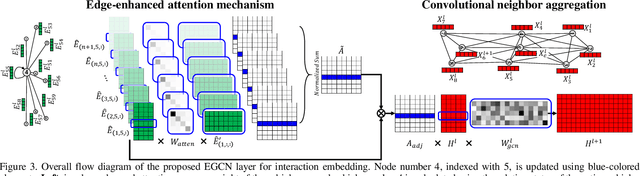
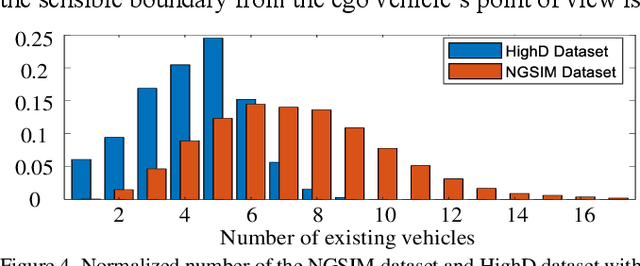
Predicting the future trajectory of surrounding vehicles in a randomly varying traffic level is one of the most challenging problems in developing an autonomous vehicle. Since there is no pre-defined number of interacting vehicles participate in, the prediction network has to be scalable with respect to the vehicle number in order to guarantee the consistency in terms of both accuracy and computational load. In this paper, the first fully scalable trajectory prediction network, SCALE-Net, is proposed that can ensure both higher prediction performance and consistent computational load regardless of the number of surrounding vehicles. The SCALE-Net employs the Edge-enhance Graph Convolutional Neural Network (EGCN) for the inter-vehicular interaction embedding network. Since the proposed EGCN is inherently scalable with respect to the graph node (an agent in this study), the model can be operated independently from the total number of vehicles considered. We evaluated the scalability of the SCALE-Net on the publically available NGSIM datasets by comparing variations on computation time and prediction accuracy per single driving scene with respect to the varying vehicle number. The experimental test shows that both computation time and prediction performance of the SCALE-Net consistently outperform those of previous models regardless of the level of traffic complexities.