 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelectively Dilated Convolution for Accuracy-Preserving Sparse Pillar-based Embedded 3D Object Detection
Paper and Code
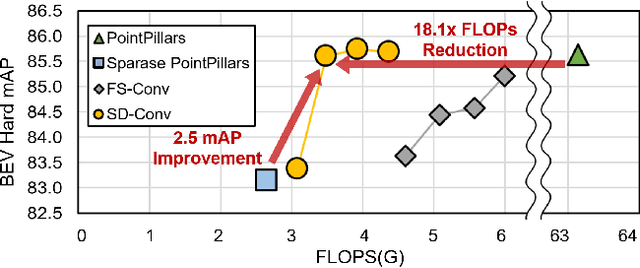


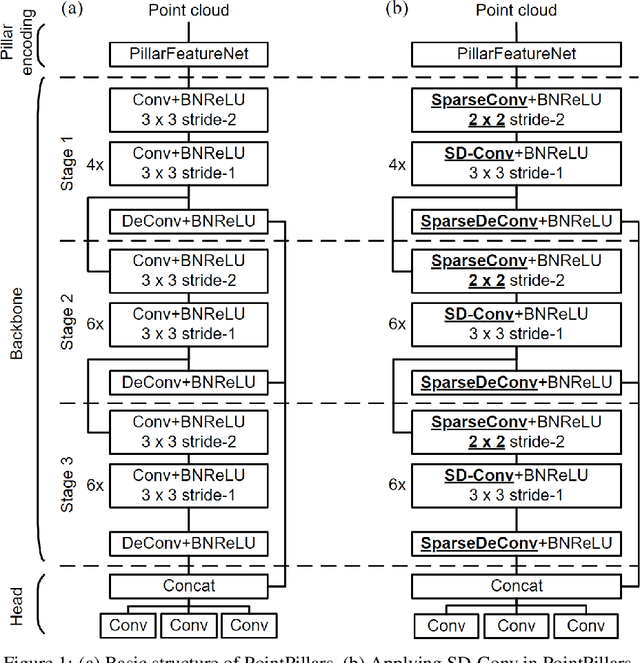
Pillar-based 3D object detection has gained traction in self-driving technology due to its speed and accuracy facilitated by the artificial densification of pillars for GPU-friendly processing. However, dense pillar processing fundamentally wastes computation since it ignores the inherent sparsity of pillars derived from scattered point cloud data. Motivated by recent embedded accelerators with native sparsity support, sparse pillar convolution methods like submanifold convolution (SubM-Conv) aimed to reduce these redundant computations by applying convolution only on active pillars but suffered considerable accuracy loss. Our research identifies that this accuracy loss is due to the restricted fine-grained spatial information flow (fSIF) of SubM-Conv in sparse pillar networks. To overcome this restriction, we propose a selectively dilated (SD-Conv) convolution that evaluates the importance of encoded pillars and selectively dilates the convolution output, enhancing the receptive field for critical pillars and improving object detection accuracy. To facilitate actual acceleration with this novel convolution approach, we designed SPADE+ as a cost-efficient augmentation to existing embedded sparse convolution accelerators. This design supports the SD-Conv without significant demands in area and SRAM size, realizing superior trade-off between the speedup and model accuracy. This strategic enhancement allows our method to achieve extreme pillar sparsity, leading to up to 18.1x computational savings and 16.2x speedup on the embedded accelerators, without compromising object detection accuracy.