 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTangram: Unlocking Non-Uniform KV Cache for Efficient Multi-turn LLM Serving
Jun 04, 2026Multi-turn Large Language Model (LLM) serving is critical for consistent user experiences, yet the linear growth of the Key-Value (KV) cache imposes significant pressure on GPU memory and bandwidth. Non-uniform KV compression effectively preserves more information by considering the individual importance of each KV cache. However, such KV cache heterogeneity introduces various systemic challenges - including memory fragmentation, scheduling complexities, and diminished kernel utilization - which collectively lead to significant inefficiencies in existing LLM serving systems. To overcome these challenges, we present Tangram, a novel serving system designed to make Non-uniform KV caches practical. Tangram addresses systemic inefficiencies through three core techniques: (1) Deterministic Budget Allocation assigns a static memory footprint to each head based on its intrinsic pattern, entirely eliminating dynamic scheduling overhead and prefill stalls; (2) Head Group Page clusters attention heads with similar retention demands and manages them with independent, vectorized page tables, thereby maximizing physical memory reclamation; and (3) Ahead-of-Time (AOT) Load Balancing leverages static budget profiles to ensure uniform GPU utilization without runtime overhead. Experimental results show that Tangram improves throughput by up to 2.6x compared to existing baselines, while fully preserving model accuracy. Our implementation is publicly available at https://github.com/aiha-lab/TANGRAM.
SPOC: Safety-Aware Planning Under Partial Observability And Physical Constraints
Feb 25, 2026Embodied Task Planning with large language models faces safety challenges in real-world environments, where partial observability and physical constraints must be respected. Existing benchmarks often overlook these critical factors, limiting their ability to evaluate both feasibility and safety. We introduce SPOC, a benchmark for safety-aware embodied task planning, which integrates strict partial observability, physical constraints, step-by-step planning, and goal-condition-based evaluation. Covering diverse household hazards such as fire, fluid, injury, object damage, and pollution, SPOC enables rigorous assessment through both state and constraint-based online metrics. Experiments with state-of-the-art LLMs reveal that current models struggle to ensure safety-aware planning, particularly under implicit constraints. Code and dataset are available at https://github.com/khm159/SPOC
Resilient Multi-Agent Negotiation for Medical Supply Chains:Integrating LLMs and Blockchain for Transparent Coordination
Jul 23, 2025Global health emergencies, such as the COVID-19 pandemic, have exposed critical weaknesses in traditional medical supply chains, including inefficiencies in resource allocation, lack of transparency, and poor adaptability to dynamic disruptions. This paper presents a novel hybrid framework that integrates blockchain technology with a decentralized, large language model (LLM) powered multi-agent negotiation system to enhance the resilience and accountability of medical supply chains during crises. In this system, autonomous agents-representing manufacturers, distributors, and healthcare institutions-engage in structured, context-aware negotiation and decision-making processes facilitated by LLMs, enabling rapid and ethical allocation of scarce medical resources. The off-chain agent layer supports adaptive reasoning and local decision-making, while the on-chain blockchain layer ensures immutable, transparent, and auditable enforcement of decisions via smart contracts. The framework also incorporates a formal cross-layer communication protocol to bridge decentralized negotiation with institutional enforcement. A simulation environment emulating pandemic scenarios evaluates the system's performance, demonstrating improvements in negotiation efficiency, fairness of allocation, supply chain responsiveness, and auditability. This research contributes an innovative approach that synergizes blockchain trust guarantees with the adaptive intelligence of LLM-driven agents, providing a robust and scalable solution for critical supply chain coordination under uncertainty.
Saliency-Aware Quantized Imitation Learning for Efficient Robotic Control
May 21, 2025



Deep neural network (DNN)-based policy models, such as vision-language-action (VLA) models, excel at automating complex decision-making from multi-modal inputs. However, scaling these models greatly increases computational overhead, complicating deployment in resource-constrained settings like robot manipulation and autonomous driving. To address this, we propose Saliency-Aware Quantized Imitation Learning (SQIL), which combines quantization-aware training with a selective loss-weighting strategy for mission-critical states. By identifying these states via saliency scores and emphasizing them in the training loss, SQIL preserves decision fidelity under low-bit precision. We validate SQIL's generalization capability across extensive simulation benchmarks with environment variations, real-world tasks, and cross-domain tasks (self-driving, physics simulation), consistently recovering full-precision performance. Notably, a 4-bit weight-quantized VLA model for robotic manipulation achieves up to 2.5x speedup and 2.5x energy savings on an edge GPU with minimal accuracy loss. These results underline SQIL's potential for efficiently deploying large IL-based policy models on resource-limited devices.
Quantization-Aware Imitation-Learning for Resource-Efficient Robotic Control
Dec 02, 2024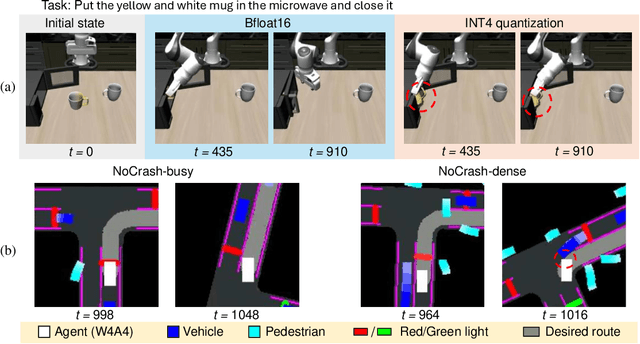
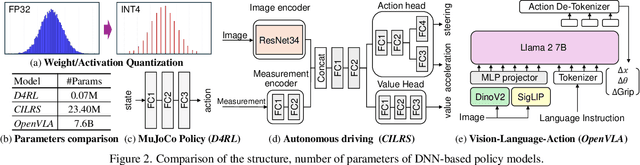
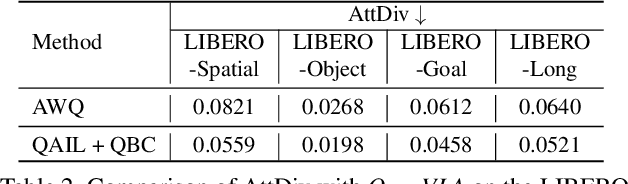
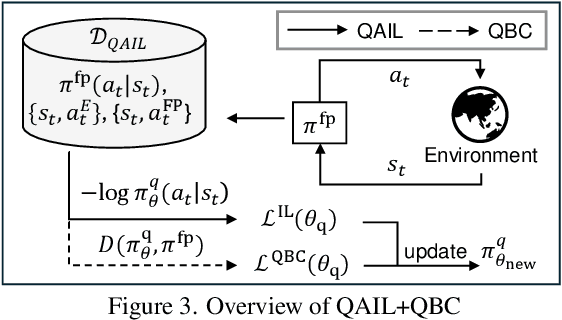
Deep neural network (DNN)-based policy models like vision-language-action (VLA) models are transformative in automating complex decision-making across applications by interpreting multi-modal data. However, scaling these models greatly increases computational costs, which presents challenges in fields like robot manipulation and autonomous driving that require quick, accurate responses. To address the need for deployment on resource-limited hardware, we propose a new quantization framework for IL-based policy models that fine-tunes parameters to enhance robustness against low-bit precision errors during training, thereby maintaining efficiency and reliability under constrained conditions. Our evaluations with representative robot manipulation for 4-bit weight-quantization on a real edge GPU demonstrate that our framework achieves up to 2.5x speedup and 2.5x energy savings while preserving accuracy. For 4-bit weight and activation quantized self-driving models, the framework achieves up to 3.7x speedup and 3.1x energy saving on a low-end GPU. These results highlight the practical potential of deploying IL-based policy models on resource-constrained devices.
ContextMix: A context-aware data augmentation method for industrial visual inspection systems
Jan 18, 2024



While deep neural networks have achieved remarkable performance, data augmentation has emerged as a crucial strategy to mitigate overfitting and enhance network performance. These techniques hold particular significance in industrial manufacturing contexts. Recently, image mixing-based methods have been introduced, exhibiting improved performance on public benchmark datasets. However, their application to industrial tasks remains challenging. The manufacturing environment generates massive amounts of unlabeled data on a daily basis, with only a few instances of abnormal data occurrences. This leads to severe data imbalance. Thus, creating well-balanced datasets is not straightforward due to the high costs associated with labeling. Nonetheless, this is a crucial step for enhancing productivity. For this reason, we introduce ContextMix, a method tailored for industrial applications and benchmark datasets. ContextMix generates novel data by resizing entire images and integrating them into other images within the batch. This approach enables our method to learn discriminative features based on varying sizes from resized images and train informative secondary features for object recognition using occluded images. With the minimal additional computation cost of image resizing, ContextMix enhances performance compared to existing augmentation techniques. We evaluate its effectiveness across classification, detection, and segmentation tasks using various network architectures on public benchmark datasets. Our proposed method demonstrates improved results across a range of robustness tasks. Its efficacy in real industrial environments is particularly noteworthy, as demonstrated using the passive component dataset.
Proxy Anchor-based Unsupervised Learning for Continuous Generalized Category Discovery
Jul 20, 2023
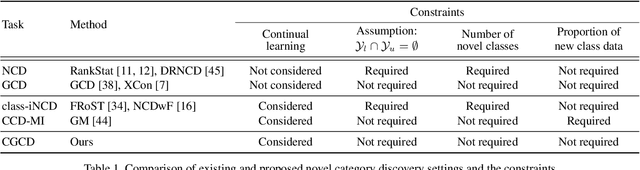
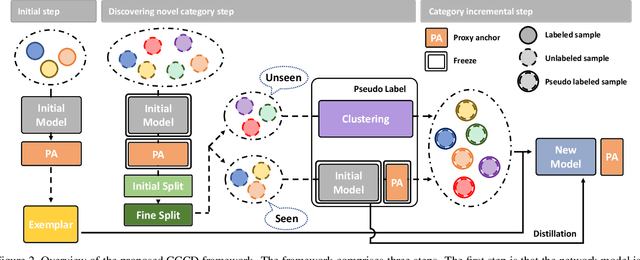
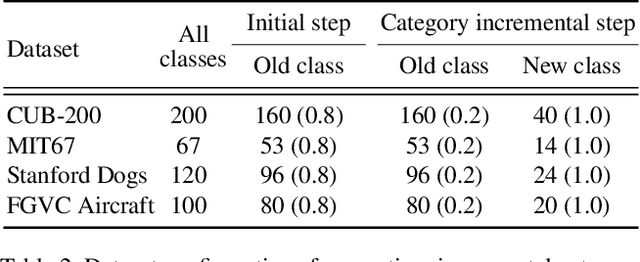
Recent advances in deep learning have significantly improved the performance of various computer vision applications. However, discovering novel categories in an incremental learning scenario remains a challenging problem due to the lack of prior knowledge about the number and nature of new categories. Existing methods for novel category discovery are limited by their reliance on labeled datasets and prior knowledge about the number of novel categories and the proportion of novel samples in the batch. To address the limitations and more accurately reflect real-world scenarios, in this paper, we propose a novel unsupervised class incremental learning approach for discovering novel categories on unlabeled sets without prior knowledge. The proposed method fine-tunes the feature extractor and proxy anchors on labeled sets, then splits samples into old and novel categories and clusters on the unlabeled dataset. Furthermore, the proxy anchors-based exemplar generates representative category vectors to mitigate catastrophic forgetting. Experimental results demonstrate that our proposed approach outperforms the state-of-the-art methods on fine-grained datasets under real-world scenarios.
PillarAcc: Sparse PointPillars Accelerator for Real-Time Point Cloud 3D Object Detection on Edge Devices
May 15, 2023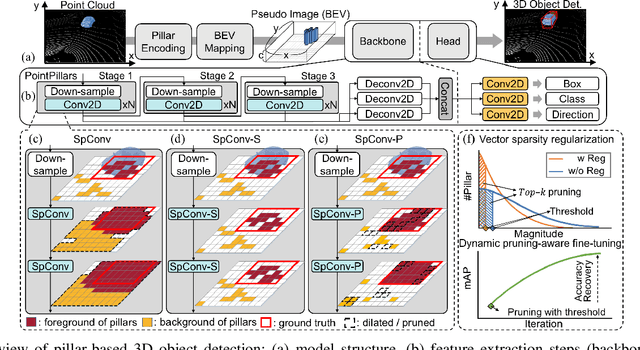
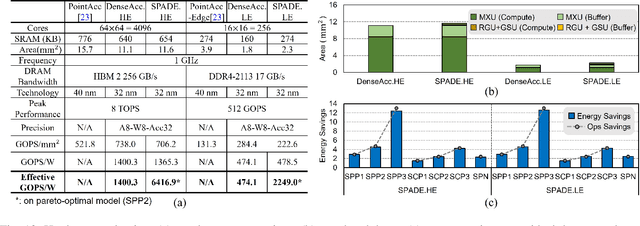
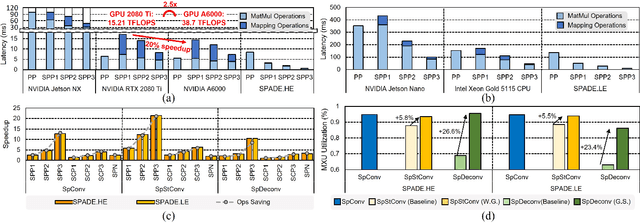
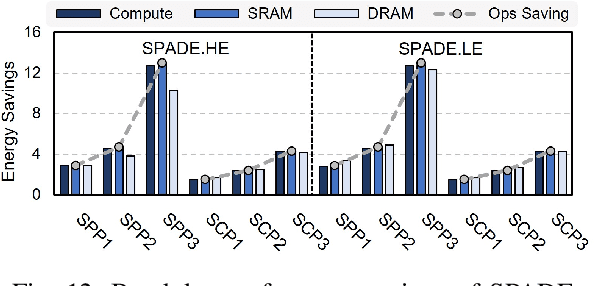
3D object detection using point cloud (PC) data is vital for autonomous driving perception pipelines, where efficient encoding is key to meeting stringent resource and latency requirements. PointPillars, a widely adopted bird's-eye view (BEV) encoding, aggregates 3D point cloud data into 2D pillars for high-accuracy 3D object detection. However, most state-of-the-art methods employing PointPillar overlook the inherent sparsity of pillar encoding, missing opportunities for significant computational reduction. In this study, we propose a groundbreaking algorithm-hardware co-design that accelerates sparse convolution processing and maximizes sparsity utilization in pillar-based 3D object detection networks. We investigate sparsification opportunities using an advanced pillar-pruning method, achieving an optimal balance between accuracy and sparsity. We introduce PillarAcc, a state-of-the-art sparsity support mechanism that enhances sparse pillar convolution through linear complexity input-output mapping generation and conflict-free gather-scatter memory access. Additionally, we propose dataflow optimization techniques, dynamically adjusting the pillar processing schedule for optimal hardware utilization under diverse sparsity operations. We evaluate PillarAcc on various cutting-edge 3D object detection networks and benchmarks, achieving remarkable speedup and energy savings compared to representative edge platforms, demonstrating record-breaking PointPillars speed of 500FPS with minimal compromise in accuracy.
AI-KD: Adversarial learning and Implicit regularization for self-Knowledge Distillation
Nov 20, 2022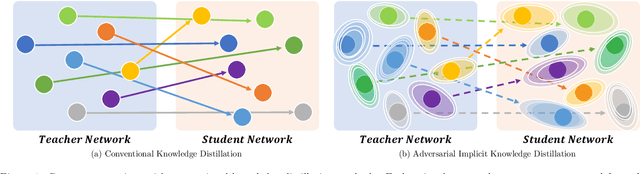
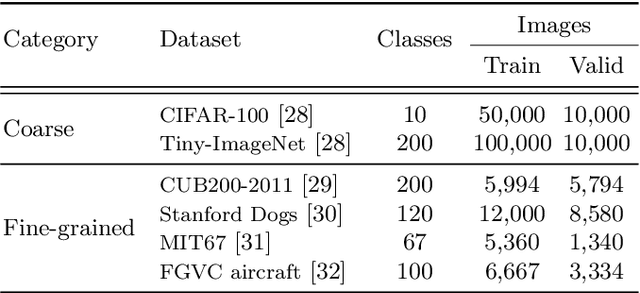
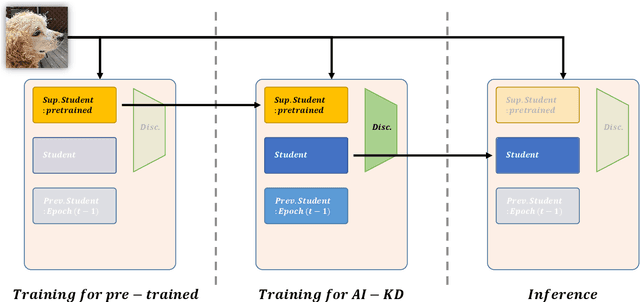
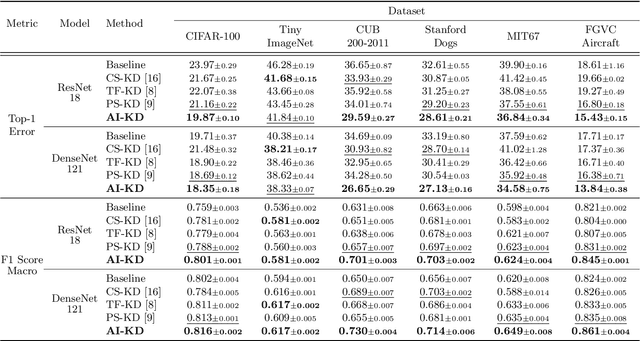
We present a novel adversarial penalized self-knowledge distillation method, named adversarial learning and implicit regularization for self-knowledge distillation (AI-KD), which regularizes the training procedure by adversarial learning and implicit distillations. Our model not only distills the deterministic and progressive knowledge which are from the pre-trained and previous epoch predictive probabilities but also transfers the knowledge of the deterministic predictive distributions using adversarial learning. The motivation is that the self-knowledge distillation methods regularize the predictive probabilities with soft targets, but the exact distributions may be hard to predict. Our method deploys a discriminator to distinguish the distributions between the pre-trained and student models while the student model is trained to fool the discriminator in the trained procedure. Thus, the student model not only can learn the pre-trained model's predictive probabilities but also align the distributions between the pre-trained and student models. We demonstrate the effectiveness of the proposed method with network architectures on multiple datasets and show the proposed method achieves better performance than state-of-the-art methods.