 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Gender Diversity on Scientific Team Impact: A Team Roles Perspective
Dec 29, 2025The influence of gender diversity on the success of scientific teams is of great interest to academia. However, prior findings remain inconsistent, and most studies operationalize diversity in aggregate terms, overlooking internal role differentiation. This limitation obscures a more nuanced understanding of how gender diversity shapes team impact. In particular, the effect of gender diversity across different team roles remains poorly understood. To this end, we define a scientific team as all coauthors of a paper and measure team impact through five-year citation counts. Using author contribution statements, we classified members into leadership and support roles. Drawing on more than 130,000 papers from PLOS journals, most of which are in biomedical-related disciplines, we employed multivariable regression to examine the association between gender diversity in these roles and team impact. Furthermore, we apply a threshold regression model to investigate how team size moderates this relationship. The results show that (1) the relationship between gender diversity and team impact follows an inverted U-shape for both leadership and support groups; (2) teams with an all-female leadership group and an all-male support group achieve higher impact than other team types. Interestingly, (3) the effect of leadership-group gender diversity is significantly negative for small teams but becomes positive and statistically insignificant in large teams. In contrast, the estimates for support-group gender diversity remain significant and positive, regardless of team size.
MaTableGPT: GPT-based Table Data Extractor from Materials Science Literature
Jun 08, 2024Efficiently extracting data from tables in the scientific literature is pivotal for building large-scale databases. However, the tables reported in materials science papers exist in highly diverse forms; thus, rule-based extractions are an ineffective approach. To overcome this challenge, we present MaTableGPT, which is a GPT-based table data extractor from the materials science literature. MaTableGPT features key strategies of table data representation and table splitting for better GPT comprehension and filtering hallucinated information through follow-up questions. When applied to a vast volume of water splitting catalysis literature, MaTableGPT achieved an extraction accuracy (total F1 score) of up to 96.8%. Through comprehensive evaluations of the GPT usage cost, labeling cost, and extraction accuracy for the learning methods of zero-shot, few-shot and fine-tuning, we present a Pareto-front mapping where the few-shot learning method was found to be the most balanced solution owing to both its high extraction accuracy (total F1 score>95%) and low cost (GPT usage cost of 5.97 US dollars and labeling cost of 10 I/O paired examples). The statistical analyses conducted on the database generated by MaTableGPT revealed valuable insights into the distribution of the overpotential and elemental utilization across the reported catalysts in the water splitting literature.
ContextMix: A context-aware data augmentation method for industrial visual inspection systems
Jan 18, 2024



While deep neural networks have achieved remarkable performance, data augmentation has emerged as a crucial strategy to mitigate overfitting and enhance network performance. These techniques hold particular significance in industrial manufacturing contexts. Recently, image mixing-based methods have been introduced, exhibiting improved performance on public benchmark datasets. However, their application to industrial tasks remains challenging. The manufacturing environment generates massive amounts of unlabeled data on a daily basis, with only a few instances of abnormal data occurrences. This leads to severe data imbalance. Thus, creating well-balanced datasets is not straightforward due to the high costs associated with labeling. Nonetheless, this is a crucial step for enhancing productivity. For this reason, we introduce ContextMix, a method tailored for industrial applications and benchmark datasets. ContextMix generates novel data by resizing entire images and integrating them into other images within the batch. This approach enables our method to learn discriminative features based on varying sizes from resized images and train informative secondary features for object recognition using occluded images. With the minimal additional computation cost of image resizing, ContextMix enhances performance compared to existing augmentation techniques. We evaluate its effectiveness across classification, detection, and segmentation tasks using various network architectures on public benchmark datasets. Our proposed method demonstrates improved results across a range of robustness tasks. Its efficacy in real industrial environments is particularly noteworthy, as demonstrated using the passive component dataset.
Bespoke Nanoparticle Synthesis and Chemical Knowledge Discovery Via Autonomous Experimentations
Sep 01, 2023The optimization of nanomaterial synthesis using numerous synthetic variables is considered to be extremely laborious task because the conventional combinatorial explorations are prohibitively expensive. In this work, we report an autonomous experimentation platform developed for the bespoke design of nanoparticles (NPs) with targeted optical properties. This platform operates in a closed-loop manner between a batch synthesis module of NPs and a UV- Vis spectroscopy module, based on the feedback of the AI optimization modeling. With silver (Ag) NPs as a representative example, we demonstrate that the Bayesian optimizer implemented with the early stopping criterion can efficiently produce Ag NPs precisely possessing the desired absorption spectra within only 200 iterations (when optimizing among five synthetic reagents). In addition to the outstanding material developmental efficiency, the analysis of synthetic variables further reveals a novel chemistry involving the effects of citrate in Ag NP synthesis. The amount of citrate is a key to controlling the competitions between spherical and plate-shaped NPs and, as a result, affects the shapes of the absorption spectra as well. Our study highlights both capabilities of the platform to enhance search efficiencies and to provide a novel chemical knowledge by analyzing datasets accumulated from the autonomous experimentations.
Robustness of SAM: Segment Anything Under Corruptions and Beyond
Jun 13, 2023



Segment anything model (SAM), as the name suggests, is claimed to be capable of cutting out any object. SAM is a vision foundation model which demonstrates impressive zero-shot transfer performance with the guidance of a prompt. However, there is currently a lack of comprehensive evaluation of its robustness performance under various types of corruptions. Prior works show that SAM is biased towards texture (style) rather than shape, motivated by which we start by investigating SAM's robustness against style transfer, which is synthetic corruption. With the effect of corruptions interpreted as a style change, we further evaluate its robustness on 15 common corruptions with 5 severity levels for each real-world corruption. Beyond the corruptions, we further evaluate the SAM robustness on local occlusion and adversarial perturbations. Overall, this work provides a comprehensive empirical study on the robustness of the SAM under corruptions and beyond.
Attack-SAM: Towards Attacking Segment Anything Model With Adversarial Examples
May 08, 2023



Segment Anything Model (SAM) has attracted significant attention recently, due to its impressive performance on various downstream tasks in a zero-short manner. Computer vision (CV) area might follow the natural language processing (NLP) area to embark on a path from task-specific vision models toward foundation models. However, deep vision models are widely recognized as vulnerable to adversarial examples, which fool the model to make wrong predictions with imperceptible perturbation. Such vulnerability to adversarial attacks causes serious concerns when applying deep models to security-sensitive applications. Therefore, it is critical to know whether the vision foundation model SAM can also be fooled by adversarial attacks. To the best of our knowledge, our work is the first of its kind to conduct a comprehensive investigation on how to attack SAM with adversarial examples. With the basic attack goal set to mask removal, we investigate the adversarial robustness of SAM in the full white-box setting and transfer-based black-box settings. Beyond the basic goal of mask removal, we further investigate and find that it is possible to generate any desired mask by the adversarial attack.
Machine vision for vial positioning detection toward the safe automation of material synthesis
Jun 15, 2022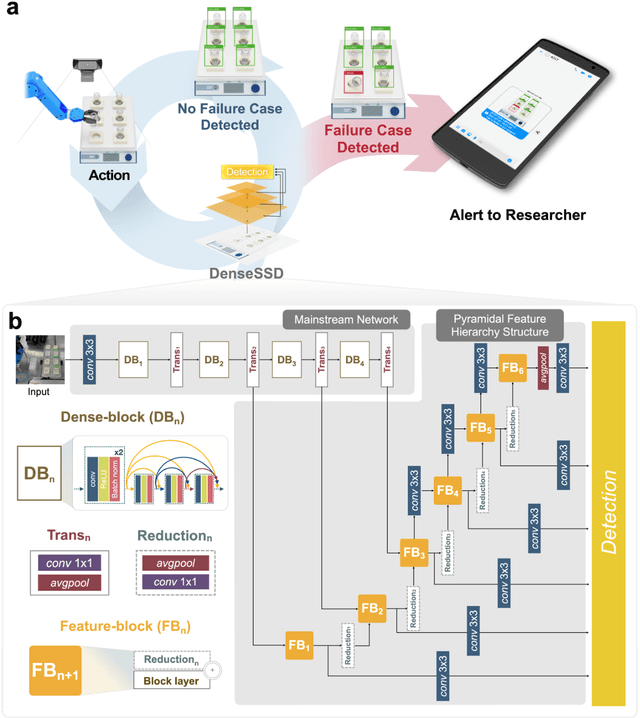

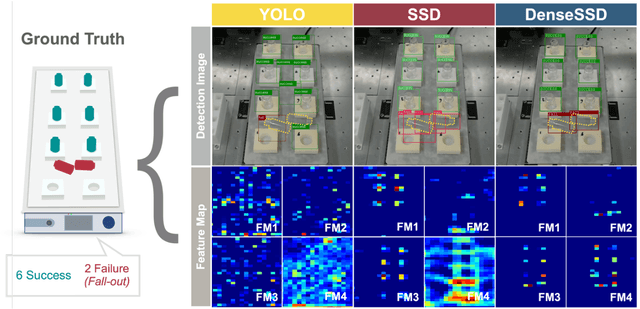
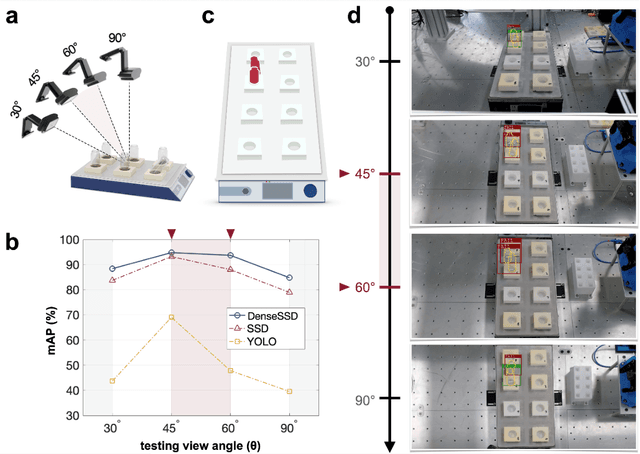
Although robot-based automation in chemistry laboratories can accelerate the material development process, surveillance-free environments may lead to dangerous accidents primarily due to machine control errors. Object detection techniques can play vital roles in addressing these safety issues; however, state-of-the-art detectors, including single-shot detector (SSD) models, suffer from insufficient accuracy in environments involving complex and noisy scenes. With the aim of improving safety in a surveillance-free laboratory, we report a novel deep learning (DL)-based object detector, namely, DenseSSD. For the foremost and frequent problem of detecting vial positions, DenseSSD achieved a mean average precision (mAP) over 95% based on a complex dataset involving both empty and solution-filled vials, greatly exceeding those of conventional detectors; such high precision is critical to minimizing failure-induced accidents. Additionally, DenseSSD was observed to be highly insensitive to the environmental changes, maintaining its high precision under the variations of solution colors or testing view angles. The robustness of DenseSSD would allow the utilized equipment settings to be more flexible. This work demonstrates that DenseSSD is useful for enhancing safety in an automated material synthesis environment, and it can be extended to various applications where high detection accuracy and speed are both needed.
Predicting failure characteristics of structural materials via deep learning based on nondestructive void topology
May 17, 2022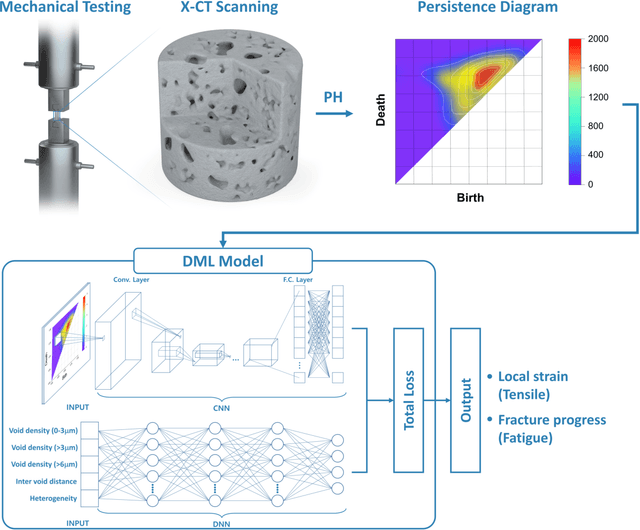

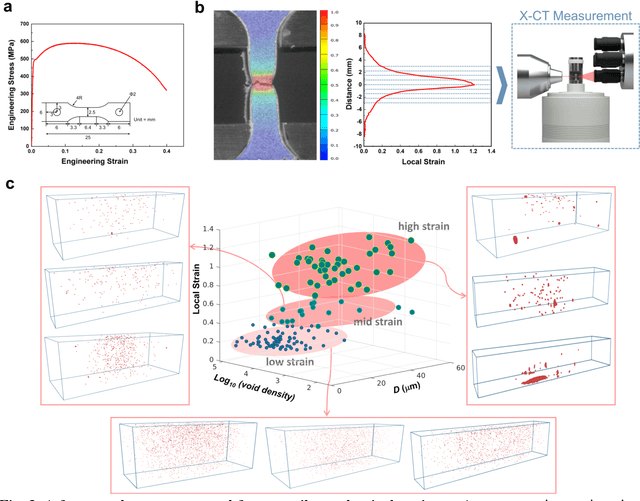
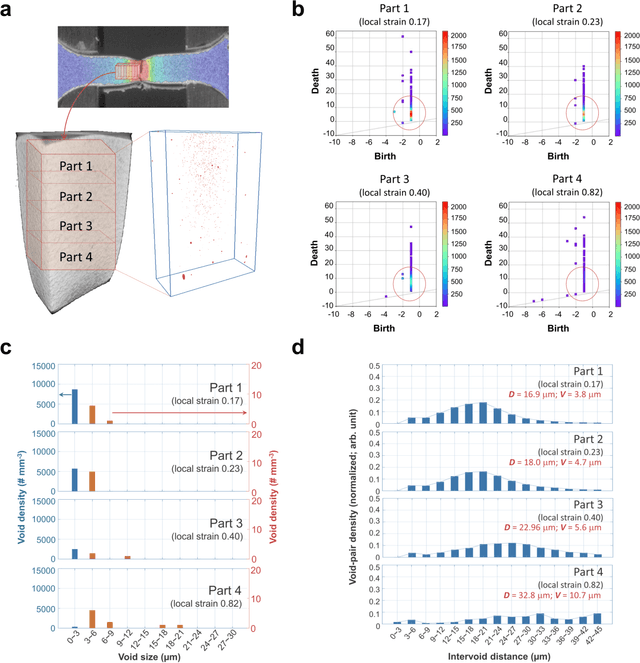
Accurate predictions of the failure progression of structural materials is critical for preventing failure-induced accidents. Despite considerable mechanics modeling-based efforts, accurate prediction remains a challenging task in real-world environments due to unexpected damage factors and defect evolutions. Here, we report a novel method for predicting material failure characteristics that uniquely combines nondestructive X-ray computed tomography (X-CT), persistent homology (PH), and deep multimodal learning (DML). The combined method exploits the microstructural defect state at the time of material examination as an input, and outputs the failure-related properties. Our method is demonstrated to be effective using two types of fracture datasets (tensile and fatigue datasets) with ferritic low alloy steel as a representative structural material. The method achieves a mean absolute error (MAE) of 0.09 in predicting the local strain with the tensile dataset and an MAE of 0.14 in predicting the fracture progress with the fatigue dataset. These high accuracies are mainly due to PH processing of the X-CT images, which transforms complex and noisy three-dimensional X-CT images into compact two-dimensional persistence diagrams that preserve key topological features such as the internal void size, density, and distribution. The combined PH and DML processing of 3D X-CT data is our unique approach enabling reliable failure predictions at the time of material examination based on void topology progressions, and the method can be extended to various nondestructive failure tests for practical use.
Identification of Crystal Symmetry from Noisy Diffraction Patterns by A Shape Analysis and Deep Learning
May 26, 2020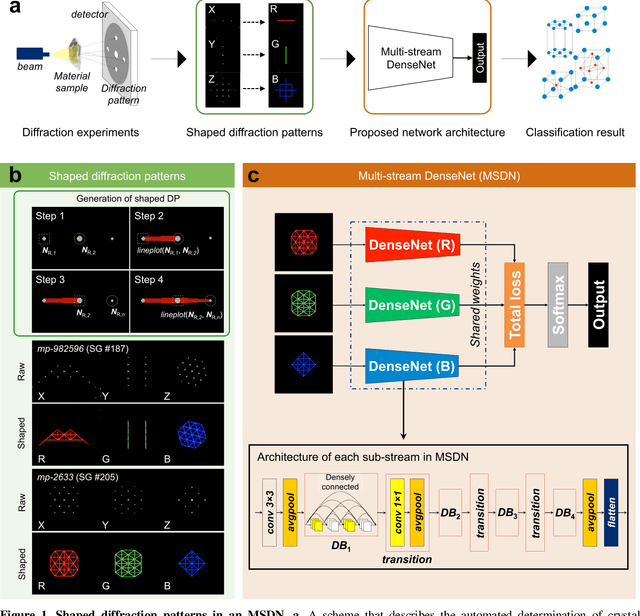
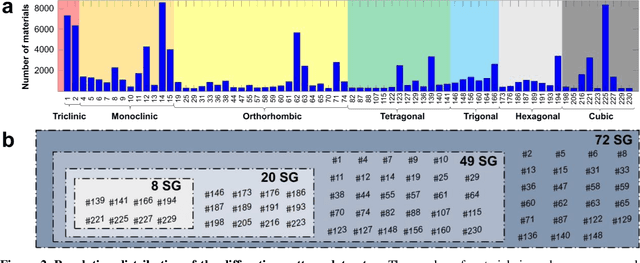
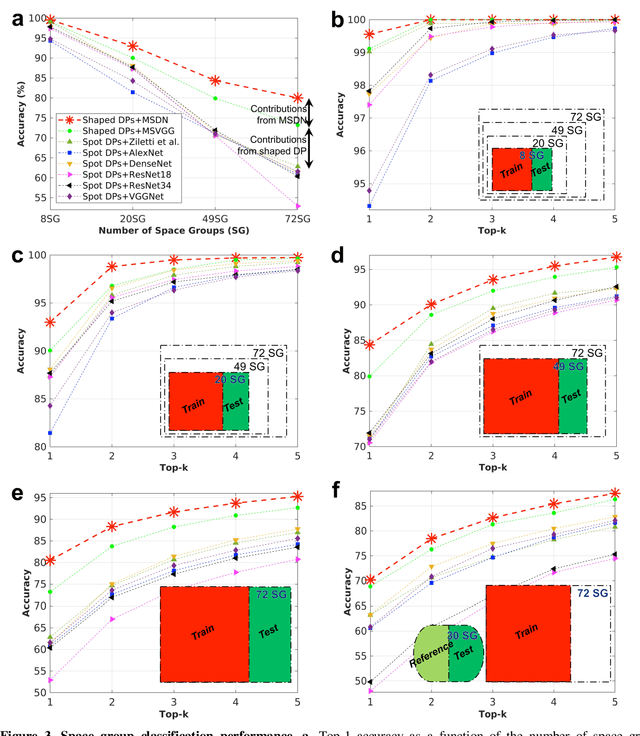
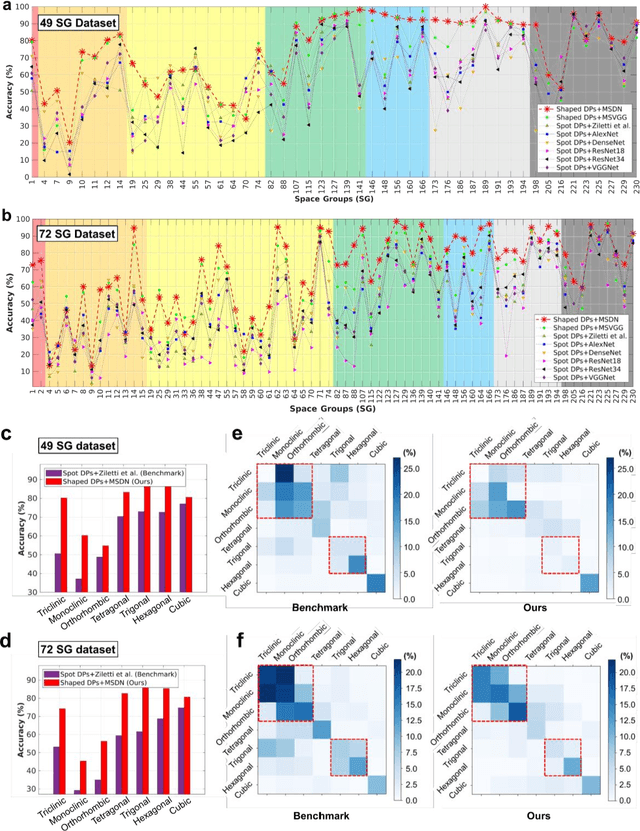
The robust and automated determination of crystal symmetry is of utmost importance in material characterization and analysis. Recent studies have shown that deep learning (DL) methods can effectively reveal the correlations between X-ray or electron-beam diffraction patterns and crystal symmetry. Despite their promise, most of these studies have been limited to identifying relatively few classes into which a target material may be grouped. On the other hand, the DL-based identification of crystal symmetry suffers from a drastic drop in accuracy for problems involving classification into tens or hundreds of symmetry classes (e.g., up to 230 space groups), severely limiting its practical usage. Here, we demonstrate that a combined approach of shaping diffraction patterns and implementing them in a multistream DenseNet (MSDN) substantially improves the accuracy of classification. Even with an imbalanced dataset of 108,658 individual crystals sampled from 72 space groups, our model achieves 80.2% space group classification accuracy, outperforming conventional benchmark models by 17-27 percentage points (%p). The enhancement can be largely attributed to the pattern shaping strategy, through which the subtle changes in patterns between symmetrically close crystal systems (e.g., monoclinic vs. orthorhombic or trigonal vs. hexagonal) are well differentiated. We additionally find that the novel MSDN architecture is advantageous for capturing patterns in a richer but less redundant manner relative to conventional convolutional neural networks. The newly proposed protocols in regard to both input descriptor processing and DL architecture enable accurate space group classification and thus improve the practical usage of the DL approach in crystal symmetry identification.