 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaTableGPT: GPT-based Table Data Extractor from Materials Science Literature
Jun 08, 2024Efficiently extracting data from tables in the scientific literature is pivotal for building large-scale databases. However, the tables reported in materials science papers exist in highly diverse forms; thus, rule-based extractions are an ineffective approach. To overcome this challenge, we present MaTableGPT, which is a GPT-based table data extractor from the materials science literature. MaTableGPT features key strategies of table data representation and table splitting for better GPT comprehension and filtering hallucinated information through follow-up questions. When applied to a vast volume of water splitting catalysis literature, MaTableGPT achieved an extraction accuracy (total F1 score) of up to 96.8%. Through comprehensive evaluations of the GPT usage cost, labeling cost, and extraction accuracy for the learning methods of zero-shot, few-shot and fine-tuning, we present a Pareto-front mapping where the few-shot learning method was found to be the most balanced solution owing to both its high extraction accuracy (total F1 score>95%) and low cost (GPT usage cost of 5.97 US dollars and labeling cost of 10 I/O paired examples). The statistical analyses conducted on the database generated by MaTableGPT revealed valuable insights into the distribution of the overpotential and elemental utilization across the reported catalysts in the water splitting literature.
Pipelines for Procedural Information Extraction from Scientific Literature: Towards Recipes using Machine Learning and Data Science
Dec 16, 2019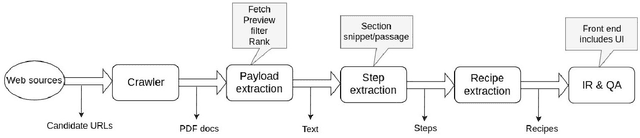
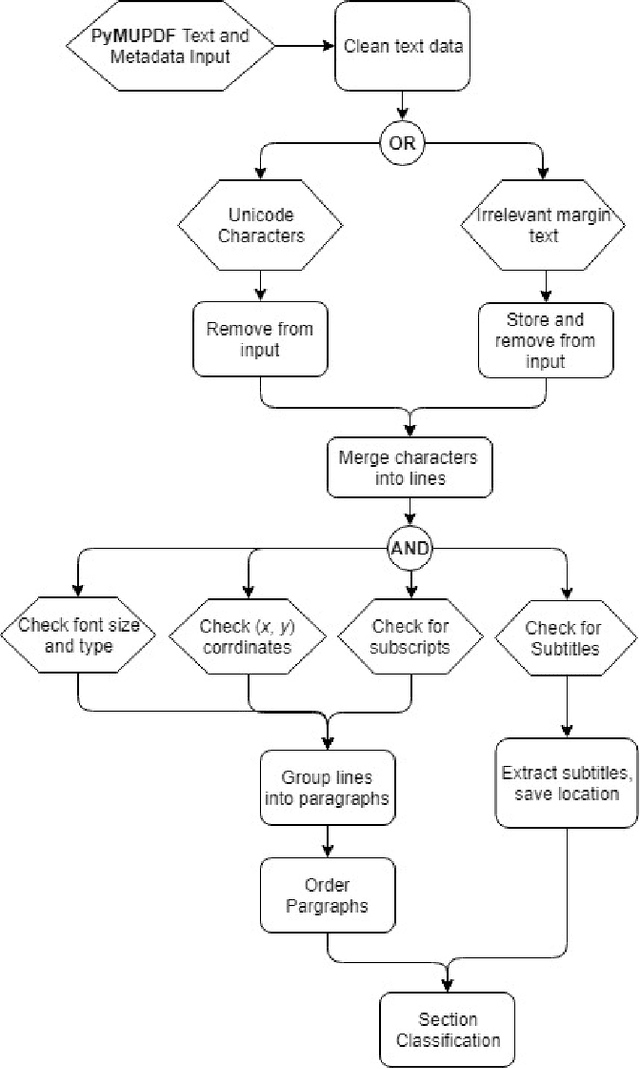
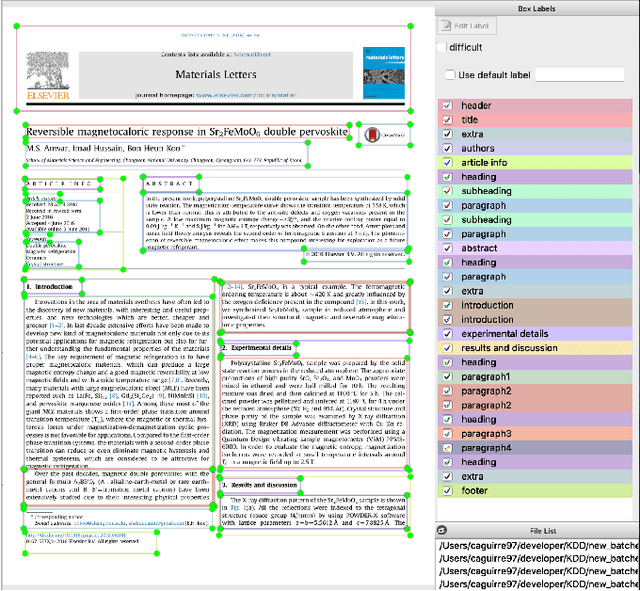

This paper describes a machine learning and data science pipeline for structured information extraction from documents, implemented as a suite of open-source tools and extensions to existing tools. It centers around a methodology for extracting procedural information in the form of recipes, stepwise procedures for creating an artifact (in this case synthesizing a nanomaterial), from published scientific literature. From our overall goal of producing recipes from free text, we derive the technical objectives of a system consisting of pipeline stages: document acquisition and filtering, payload extraction, recipe step extraction as a relationship extraction task, recipe assembly, and presentation through an information retrieval interface with question answering (QA) functionality. This system meets computational information and knowledge management (CIKM) requirements of metadata-driven payload extraction, named entity extraction, and relationship extraction from text. Functional contributions described in this paper include semi-supervised machine learning methods for PDF filtering and payload extraction tasks, followed by structured extraction and data transformation tasks beginning with section extraction, recipe steps as information tuples, and finally assembled recipes. Measurable objective criteria for extraction quality include precision and recall of recipe steps, ordering constraints, and QA accuracy, precision, and recall. Results, key novel contributions, and significant open problems derived from this work center around the attribution of these holistic quality measures to specific machine learning and inference stages of the pipeline, each with their performance measures. The desired recipes contain identified preconditions, material inputs, and operations, and constitute the overall output generated by our computational information and knowledge management (CIKM) system.