 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Molecular Dynamics to a Non-Autoregressive Ionic Transport Predictor
May 10, 2026Unlike most static material properties widely studied in the machine learning literature, ionic transport properties are inherently dynamic, making their fast and accurate prediction from static atomic structures challenging. The current standard approach, molecular dynamics (MD) simulations, suffers from prohibitively high computational cost. Recent autoregressive learning-based MD acceleration methods requiring sequential inference remain slow and prone to error accumulation; in contrast, existing non-autoregressive material property prediction models are less accurate because they fail to exploit dynamics. Moreover, existing methods typically benefit from datasets either with or without atomic trajectories, but not both. To overcome these limitations, we propose a non-autoregressive learning framework based on auxiliary modality learning, which treats atomic trajectories as an auxiliary modality during training but does not require them at inference. This enables the predictor to learn dynamics without sequential inference while benefiting from both types of datasets. As a result, our framework achieves over 200 times speedup compared to autoregressive models on the dataset with atomic trajectories while substantially reducing prediction error relative to non-autoregressive benchmarks across both types of datasets. Our code is available at https://github.com/jykim-git/MD.
Transformer-assisted Parametric CSI Feedback for mmWave Massive MIMO Systems
Oct 09, 2024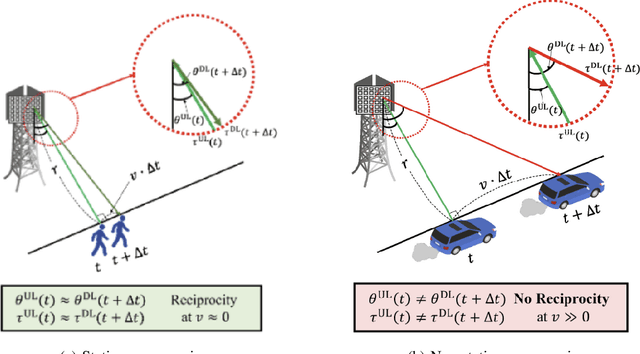
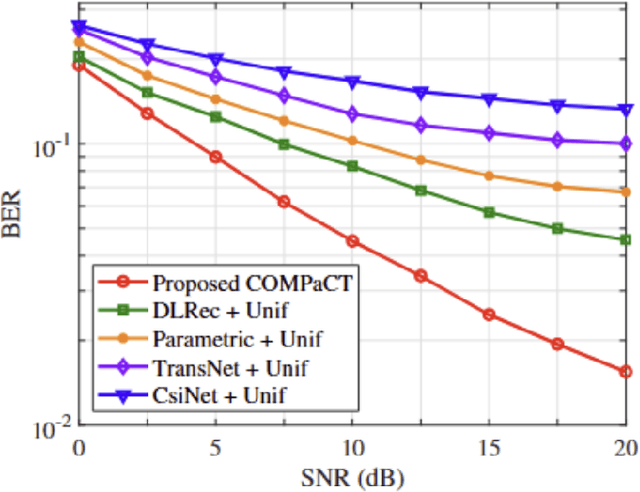
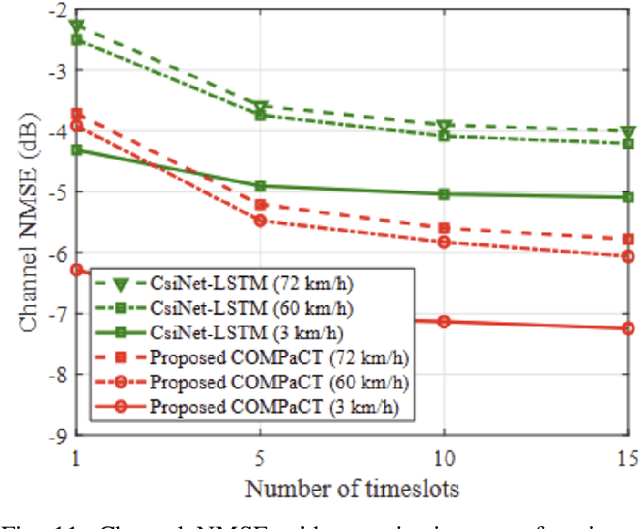
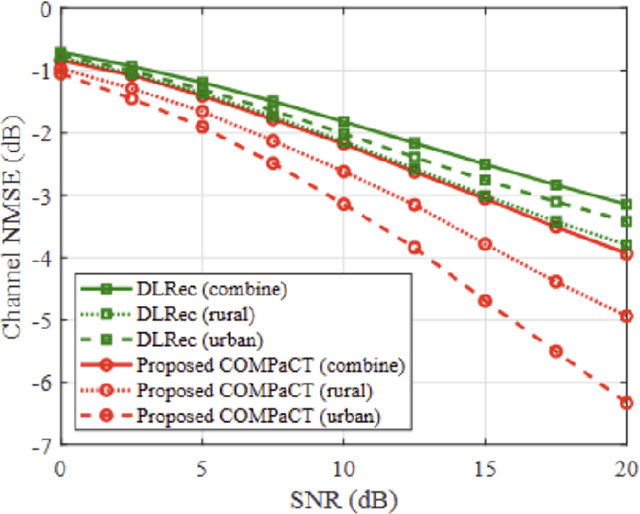
As a key technology to meet the ever-increasing data rate demand in beyond 5G and 6G communications, millimeter-wave (mmWave) massive multiple-input multiple-output (MIMO) systems have gained much attention recently.To make the most of mmWave massive MIMO systems, acquisition of accurate channel state information (CSI) at the base station (BS) is crucial. However, this task is by no means easy due to the CSI feedback overhead induced by the large number of antennas. In this paper, we propose a parametric CSI feedback technique for mmWave massive MIMO systems. Key idea of the proposed technique is to compress the mmWave MIMO channel matrix into a few geometric channel parameters (e.g., angles, delays, and path gains). Due to the limited scattering of mmWave signal, the number of channel parameters is much smaller than the number of antennas, thereby reducing the CSI feedback overhead significantly. Moreover, by exploiting the deep learning (DL) technique for the channel parameter extraction and the MIMO channel reconstruction, we can effectively suppress the channel quantization error. From the numerical results, we demonstrate that the proposed technique outperforms the conventional CSI feedback techniques in terms of normalized mean square error (NMSE) and bit error rate (BER).
Text-to-Battery Recipe: A language modeling-based protocol for automatic battery recipe extraction and retrieval
Jul 22, 2024



Recent studies have increasingly applied natural language processing (NLP) to automatically extract experimental research data from the extensive battery materials literature. Despite the complex process involved in battery manufacturing -- from material synthesis to cell assembly -- there has been no comprehensive study systematically organizing this information. In response, we propose a language modeling-based protocol, Text-to-Battery Recipe (T2BR), for the automatic extraction of end-to-end battery recipes, validated using a case study on batteries containing LiFePO4 cathode material. We report machine learning-based paper filtering models, screening 2,174 relevant papers from the keyword-based search results, and unsupervised topic models to identify 2,876 paragraphs related to cathode synthesis and 2,958 paragraphs related to cell assembly. Then, focusing on the two topics, two deep learning-based named entity recognition models are developed to extract a total of 30 entities -- including precursors, active materials, and synthesis methods -- achieving F1 scores of 88.18% and 94.61%. The accurate extraction of entities enables the systematic generation of 165 end-toend recipes of LiFePO4 batteries. Our protocol and results offer valuable insights into specific trends, such as associations between precursor materials and synthesis methods, or combinations between different precursor materials. We anticipate that our findings will serve as a foundational knowledge base for facilitating battery-recipe information retrieval. The proposed protocol will significantly accelerate the review of battery material literature and catalyze innovations in battery design and development.
MMSci: A Multimodal Multi-Discipline Dataset for PhD-Level Scientific Comprehension
Jul 06, 2024The rapid advancement of Large Language Models (LLMs) and Large Multimodal Models (LMMs) has heightened the demand for AI-based scientific assistants capable of understanding scientific articles and figures. Despite progress, there remains a significant gap in evaluating models' comprehension of professional, graduate-level, and even PhD-level scientific content. Current datasets and benchmarks primarily focus on relatively simple scientific tasks and figures, lacking comprehensive assessments across diverse advanced scientific disciplines. To bridge this gap, we collected a multimodal, multidisciplinary dataset from open-access scientific articles published in Nature Communications journals. This dataset spans 72 scientific disciplines, ensuring both diversity and quality. We created benchmarks with various tasks and settings to comprehensively evaluate LMMs' capabilities in understanding scientific figures and content. Our evaluation revealed that these tasks are highly challenging: many open-source models struggled significantly, and even GPT-4V and GPT-4o faced difficulties. We also explored using our dataset as training resources by constructing visual instruction-following data, enabling the 7B LLaVA model to achieve performance comparable to GPT-4V/o on our benchmark. Additionally, we investigated the use of our interleaved article texts and figure images for pre-training LMMs, resulting in improvements on the material generation task. The source dataset, including articles, figures, constructed benchmarks, and visual instruction-following data, is open-sourced.
MaTableGPT: GPT-based Table Data Extractor from Materials Science Literature
Jun 08, 2024Efficiently extracting data from tables in the scientific literature is pivotal for building large-scale databases. However, the tables reported in materials science papers exist in highly diverse forms; thus, rule-based extractions are an ineffective approach. To overcome this challenge, we present MaTableGPT, which is a GPT-based table data extractor from the materials science literature. MaTableGPT features key strategies of table data representation and table splitting for better GPT comprehension and filtering hallucinated information through follow-up questions. When applied to a vast volume of water splitting catalysis literature, MaTableGPT achieved an extraction accuracy (total F1 score) of up to 96.8%. Through comprehensive evaluations of the GPT usage cost, labeling cost, and extraction accuracy for the learning methods of zero-shot, few-shot and fine-tuning, we present a Pareto-front mapping where the few-shot learning method was found to be the most balanced solution owing to both its high extraction accuracy (total F1 score>95%) and low cost (GPT usage cost of 5.97 US dollars and labeling cost of 10 I/O paired examples). The statistical analyses conducted on the database generated by MaTableGPT revealed valuable insights into the distribution of the overpotential and elemental utilization across the reported catalysts in the water splitting literature.
Accelerated materials language processing enabled by GPT
Aug 18, 2023



Materials language processing (MLP) is one of the key facilitators of materials science research, as it enables the extraction of structured information from massive materials science literature. Prior works suggested high-performance MLP models for text classification, named entity recognition (NER), and extractive question answering (QA), which require complex model architecture, exhaustive fine-tuning and a large number of human-labelled datasets. In this study, we develop generative pretrained transformer (GPT)-enabled pipelines where the complex architectures of prior MLP models are replaced with strategic designs of prompt engineering. First, we develop a GPT-enabled document classification method for screening relevant documents, achieving comparable accuracy and reliability compared to prior models, with only small dataset. Secondly, for NER task, we design an entity-centric prompts, and learning few-shot of them improved the performance on most of entities in three open datasets. Finally, we develop an GPT-enabled extractive QA model, which provides improved performance and shows the possibility of automatically correcting annotations. While our findings confirm the potential of GPT-enabled MLP models as well as their value in terms of reliability and practicability, our scientific methods and systematic approach are applicable to any materials science domain to accelerate the information extraction of scientific literature.
Rate-Splitting Multiple Access for 6G Networks: Ten Promising Scenarios and Applications
Jun 22, 2023



In the upcoming 6G era, multiple access (MA) will play an essential role in achieving high throughput performances required in a wide range of wireless applications. Since MA and interference management are closely related issues, the conventional MA techniques are limited in that they cannot provide near-optimal performance in universal interference regimes. Recently, rate-splitting multiple access (RSMA) has been gaining much attention. RSMA splits an individual message into two parts: a common part, decodable by every user, and a private part, decodable only by the intended user. Each user first decodes the common message and then decodes its private message by applying successive interference cancellation (SIC). By doing so, RSMA not only embraces the existing MA techniques as special cases but also provides significant performance gains by efficiently mitigating inter-user interference in a broad range of interference regimes. In this article, we first present the theoretical foundation of RSMA. Subsequently, we put forth four key benefits of RSMA: spectral efficiency, robustness, scalability, and flexibility. Upon this, we describe how RSMA can enable ten promising scenarios and applications along with future research directions to pave the way for 6G.
Phase-Shift Design and Channel Modeling for Focused Beams in IRS-Assisted FSO Systems
Apr 20, 2022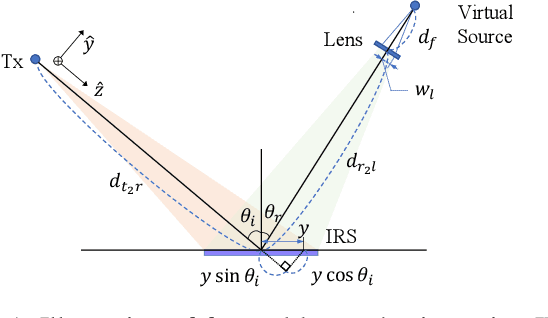



Interest in free-space optics (FSO) is rapidly growing as a potential solution for the backhaul of next-generation mobile or low-orbit satellite communications. Various techniques have been suggested for employing an intelligent reflecting surface (IRS) in FSO systems, such as anomalous reflection, power amplification, and beam splitting. It is possible to deliver more power to the receiver (Rx) by collimating or focusing the reflected beam at the Rx lens. In this study, we propose a phase-shift design of an IRS for beam focusing. In addition, we propose a new pointing error model and an outage performance analysis applicable when the beam width is comparable to or less than the aperture size of the Rx. The analytical results are validated by Monte Carlo simulations. This study provides essential preliminary results for future researches that assume a focused beam in FSO systems.