 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPIN-Bench: How Well Do LLMs Plan Strategically and Reason Socially?
Mar 16, 2025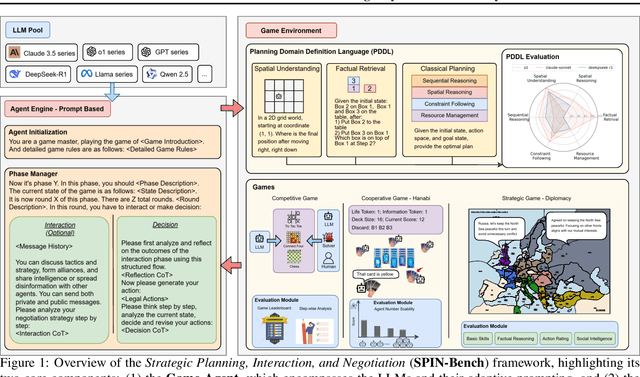
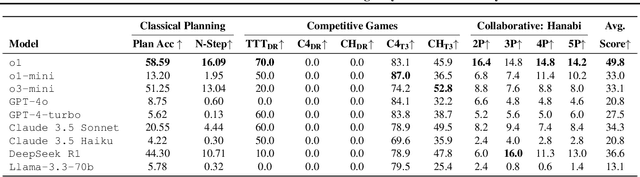

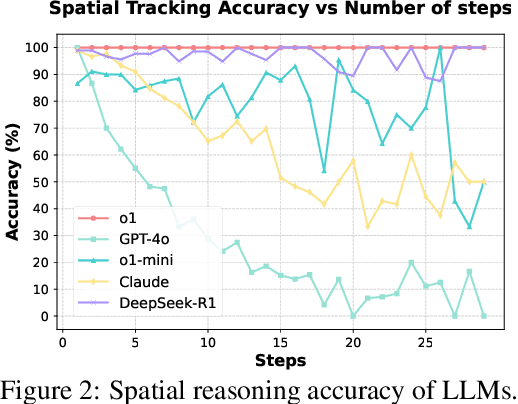
Reasoning and strategic behavior in \emph{social interactions} is a hallmark of intelligence. This form of reasoning is significantly more sophisticated than isolated planning or reasoning tasks in static settings (e.g., math problem solving). In this paper, we present \textit{Strategic Planning, Interaction, and Negotiation} (\textbf{SPIN-Bench}), a new multi-domain evaluation designed to measure the intelligence of \emph{strategic planning} and \emph{social reasoning}. While many existing benchmarks focus on narrow planning or single-agent reasoning, SPIN-Bench combines classical PDDL tasks, competitive board games, cooperative card games, and multi-agent negotiation scenarios in one unified framework. The framework includes both a benchmark as well as an arena to simulate and evaluate the variety of social settings to test reasoning and strategic behavior of AI agents. We formulate the benchmark SPIN-Bench by systematically varying action spaces, state complexity, and the number of interacting agents to simulate a variety of social settings where success depends on not only methodical and step-wise decision making, but also \emph{conceptual inference} of other (adversarial or cooperative) participants. Our experiments reveal that while contemporary LLMs handle \emph{basic fact retrieval} and \emph{short-range planning} reasonably well, they encounter significant performance bottlenecks in tasks requiring \emph{deep multi-hop reasoning} over large state spaces and \emph{socially adept} coordination under uncertainty. We envision SPIN-Bench as a catalyst for future research on robust multi-agent planning, social reasoning, and human--AI teaming.
MMSci: A Multimodal Multi-Discipline Dataset for PhD-Level Scientific Comprehension
Jul 06, 2024The rapid advancement of Large Language Models (LLMs) and Large Multimodal Models (LMMs) has heightened the demand for AI-based scientific assistants capable of understanding scientific articles and figures. Despite progress, there remains a significant gap in evaluating models' comprehension of professional, graduate-level, and even PhD-level scientific content. Current datasets and benchmarks primarily focus on relatively simple scientific tasks and figures, lacking comprehensive assessments across diverse advanced scientific disciplines. To bridge this gap, we collected a multimodal, multidisciplinary dataset from open-access scientific articles published in Nature Communications journals. This dataset spans 72 scientific disciplines, ensuring both diversity and quality. We created benchmarks with various tasks and settings to comprehensively evaluate LMMs' capabilities in understanding scientific figures and content. Our evaluation revealed that these tasks are highly challenging: many open-source models struggled significantly, and even GPT-4V and GPT-4o faced difficulties. We also explored using our dataset as training resources by constructing visual instruction-following data, enabling the 7B LLaVA model to achieve performance comparable to GPT-4V/o on our benchmark. Additionally, we investigated the use of our interleaved article texts and figure images for pre-training LMMs, resulting in improvements on the material generation task. The source dataset, including articles, figures, constructed benchmarks, and visual instruction-following data, is open-sourced.