 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMacRAG: Compress, Slice, and Scale-up for Multi-Scale Adaptive Context RAG
May 10, 2025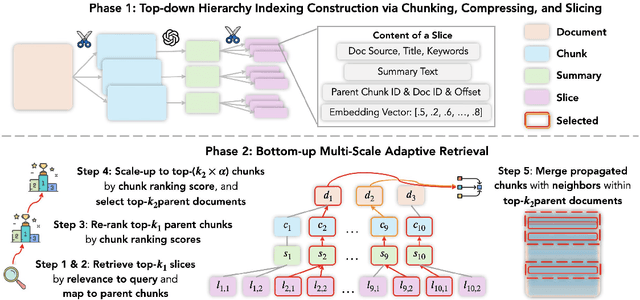

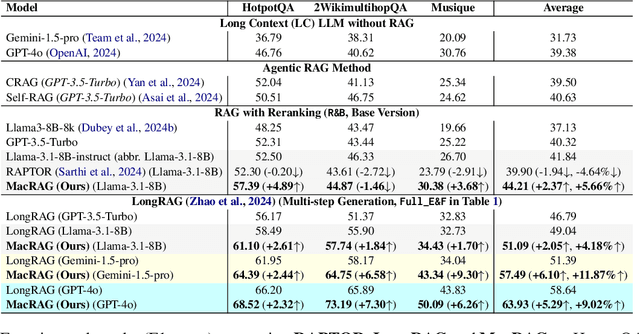
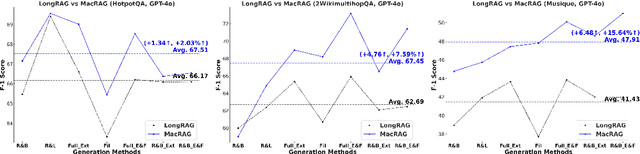
Long-context (LC) Large Language Models (LLMs) combined with Retrieval-Augmented Generation (RAG) hold strong potential for complex multi-hop and large-document tasks. However, existing RAG systems often suffer from imprecise retrieval, incomplete context coverage under constrained context windows, and fragmented information caused by suboptimal context construction. We introduce Multi-scale Adaptive Context RAG (MacRAG), a hierarchical retrieval framework that compresses and partitions documents into coarse-to-fine granularities, then adaptively merges relevant contexts through chunk- and document-level expansions in real time. By starting from the finest-level retrieval and progressively incorporating higher-level and broader context, MacRAG constructs effective query-specific long contexts, optimizing both precision and coverage. Evaluations on the challenging LongBench expansions of HotpotQA, 2WikiMultihopQA, and Musique confirm that MacRAG consistently surpasses baseline RAG pipelines on single- and multi-step generation with Llama-3.1-8B, Gemini-1.5-pro, and GPT-4o. Our results establish MacRAG as an efficient, scalable solution for real-world long-context, multi-hop reasoning. Our code is available at https://github.com/Leezekun/MacRAG.
MMSci: A Multimodal Multi-Discipline Dataset for PhD-Level Scientific Comprehension
Jul 06, 2024The rapid advancement of Large Language Models (LLMs) and Large Multimodal Models (LMMs) has heightened the demand for AI-based scientific assistants capable of understanding scientific articles and figures. Despite progress, there remains a significant gap in evaluating models' comprehension of professional, graduate-level, and even PhD-level scientific content. Current datasets and benchmarks primarily focus on relatively simple scientific tasks and figures, lacking comprehensive assessments across diverse advanced scientific disciplines. To bridge this gap, we collected a multimodal, multidisciplinary dataset from open-access scientific articles published in Nature Communications journals. This dataset spans 72 scientific disciplines, ensuring both diversity and quality. We created benchmarks with various tasks and settings to comprehensively evaluate LMMs' capabilities in understanding scientific figures and content. Our evaluation revealed that these tasks are highly challenging: many open-source models struggled significantly, and even GPT-4V and GPT-4o faced difficulties. We also explored using our dataset as training resources by constructing visual instruction-following data, enabling the 7B LLaVA model to achieve performance comparable to GPT-4V/o on our benchmark. Additionally, we investigated the use of our interleaved article texts and figure images for pre-training LMMs, resulting in improvements on the material generation task. The source dataset, including articles, figures, constructed benchmarks, and visual instruction-following data, is open-sourced.