 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropyCache: Decoded Token Entropy Guided KV Caching for Diffusion Language Models
Mar 19, 2026Diffusion-based large language models (dLLMs) rely on bidirectional attention, which prevents lossless KV caching and requires a full forward pass at every denoising step. Existing approximate KV caching methods reduce this cost by selectively updating cached states, but their decision overhead scales with context length or model depth. We propose EntropyCache, a training-free KV caching method that uses the maximum entropy of newly decoded token distributions as a constant-cost signal for deciding when to recompute. Our design is grounded in two empirical observations: (1) decoded token entropy correlates with KV cache drift, providing a cheap proxy for cache staleness, and (2) feature volatility of decoded tokens persists for multiple steps after unmasking, motivating recomputation of the $k$ most recently decoded tokens. The skip-or-recompute decision requires only $O(V)$ computation per step, independent of context length and model scale. Experiments on LLaDA-8B-Instruct and Dream-7B-Instruct show that EntropyCache achieves $15.2\times$-$26.4\times$ speedup on standard benchmarks and $22.4\times$-$24.1\times$ on chain-of-thought benchmarks, with competitive accuracy and decision overhead accounting for only $0.5\%$ of inference time. Code is available at https://github.com/mscheong01/EntropyCache.
MacRAG: Compress, Slice, and Scale-up for Multi-Scale Adaptive Context RAG
May 10, 2025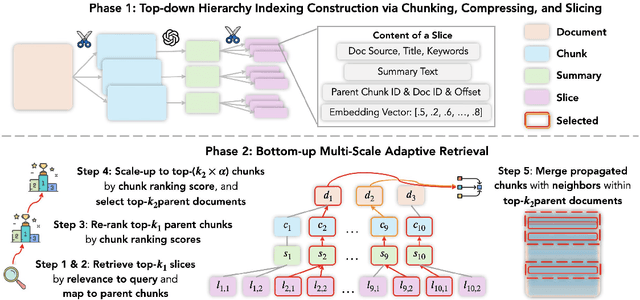

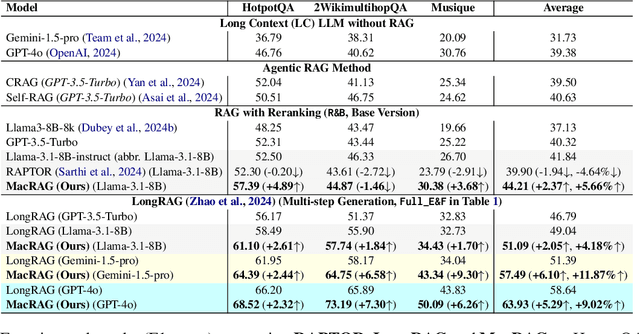
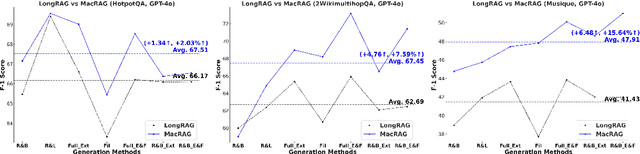
Long-context (LC) Large Language Models (LLMs) combined with Retrieval-Augmented Generation (RAG) hold strong potential for complex multi-hop and large-document tasks. However, existing RAG systems often suffer from imprecise retrieval, incomplete context coverage under constrained context windows, and fragmented information caused by suboptimal context construction. We introduce Multi-scale Adaptive Context RAG (MacRAG), a hierarchical retrieval framework that compresses and partitions documents into coarse-to-fine granularities, then adaptively merges relevant contexts through chunk- and document-level expansions in real time. By starting from the finest-level retrieval and progressively incorporating higher-level and broader context, MacRAG constructs effective query-specific long contexts, optimizing both precision and coverage. Evaluations on the challenging LongBench expansions of HotpotQA, 2WikiMultihopQA, and Musique confirm that MacRAG consistently surpasses baseline RAG pipelines on single- and multi-step generation with Llama-3.1-8B, Gemini-1.5-pro, and GPT-4o. Our results establish MacRAG as an efficient, scalable solution for real-world long-context, multi-hop reasoning. Our code is available at https://github.com/Leezekun/MacRAG.
Grouped Sequency-arranged Rotation: Optimizing Rotation Transformation for Quantization for Free
May 02, 2025



Large Language Models (LLMs) face deployment challenges due to high computational costs, and while Post-Training Quantization (PTQ) offers a solution, existing rotation-based methods struggle at very low bit-widths like 2-bit. We introduce a novel, training-free approach to construct an improved rotation matrix, addressing the limitations of current methods. The key contributions include leveraging the Walsh-Hadamard transform with sequency ordering, which clusters similar frequency components to reduce quantization error compared to standard Hadamard matrices, significantly improving performance. Furthermore, we propose a Grouped Sequency-arranged Rotation (GSR) using block-diagonal matrices with smaller Walsh blocks, effectively isolating outlier impacts and achieving performance comparable to optimization-based methods without requiring any training. Our method demonstrates robust performance on reasoning tasks and Perplexity (PPL) score on WikiText-2. Our method also enhances results even when applied over existing learned rotation techniques.
Efficient and Scalable Estimation of Tool Representations in Vector Space
Sep 02, 2024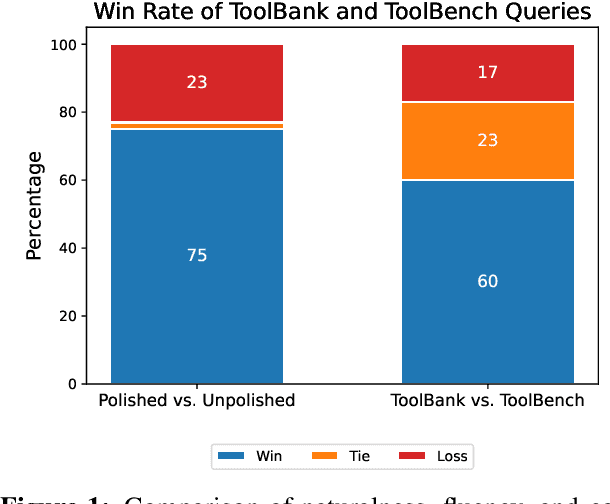
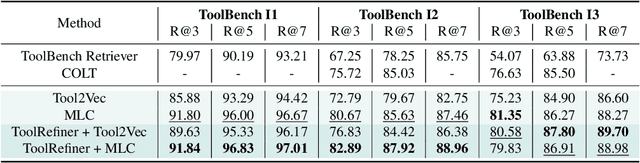
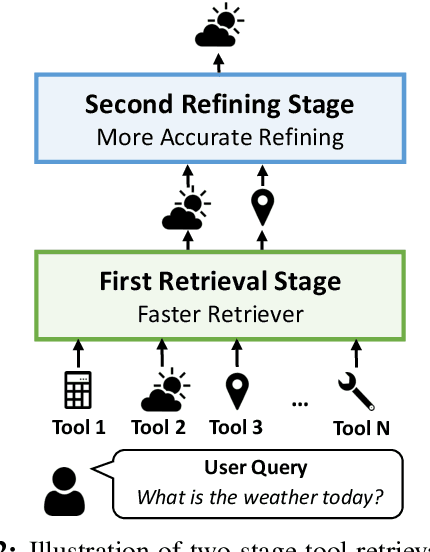
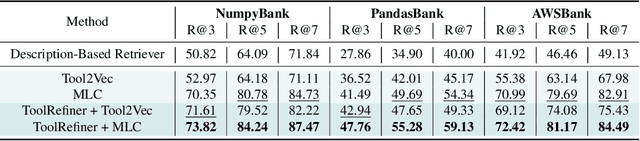
Recent advancements in function calling and tool use have significantly enhanced the capabilities of large language models (LLMs) by enabling them to interact with external information sources and execute complex tasks. However, the limited context window of LLMs presents challenges when a large number of tools are available, necessitating efficient methods to manage prompt length and maintain accuracy. Existing approaches, such as fine-tuning LLMs or leveraging their reasoning capabilities, either require frequent retraining or incur significant latency overhead. A more efficient solution involves training smaller models to retrieve the most relevant tools for a given query, although this requires high quality, domain-specific data. To address those challenges, we present a novel framework for generating synthetic data for tool retrieval applications and an efficient data-driven tool retrieval strategy using small encoder models. Empowered by LLMs, we create ToolBank, a new tool retrieval dataset that reflects real human user usages. For tool retrieval methodologies, we propose novel approaches: (1) Tool2Vec: usage-driven tool embedding generation for tool retrieval, (2) ToolRefiner: a staged retrieval method that iteratively improves the quality of retrieved tools, and (3) MLC: framing tool retrieval as a multi-label classification problem. With these new methods, we achieve improvements of up to 27.28 in Recall@K on the ToolBench dataset and 30.5 in Recall@K on ToolBank. Additionally, we present further experimental results to rigorously validate our methods. Our code is available at \url{https://github.com/SqueezeAILab/Tool2Vec}
MMSci: A Multimodal Multi-Discipline Dataset for PhD-Level Scientific Comprehension
Jul 06, 2024The rapid advancement of Large Language Models (LLMs) and Large Multimodal Models (LMMs) has heightened the demand for AI-based scientific assistants capable of understanding scientific articles and figures. Despite progress, there remains a significant gap in evaluating models' comprehension of professional, graduate-level, and even PhD-level scientific content. Current datasets and benchmarks primarily focus on relatively simple scientific tasks and figures, lacking comprehensive assessments across diverse advanced scientific disciplines. To bridge this gap, we collected a multimodal, multidisciplinary dataset from open-access scientific articles published in Nature Communications journals. This dataset spans 72 scientific disciplines, ensuring both diversity and quality. We created benchmarks with various tasks and settings to comprehensively evaluate LMMs' capabilities in understanding scientific figures and content. Our evaluation revealed that these tasks are highly challenging: many open-source models struggled significantly, and even GPT-4V and GPT-4o faced difficulties. We also explored using our dataset as training resources by constructing visual instruction-following data, enabling the 7B LLaVA model to achieve performance comparable to GPT-4V/o on our benchmark. Additionally, we investigated the use of our interleaved article texts and figure images for pre-training LMMs, resulting in improvements on the material generation task. The source dataset, including articles, figures, constructed benchmarks, and visual instruction-following data, is open-sourced.
Hadamard Product for Low-rank Bilinear Pooling
Mar 26, 2017
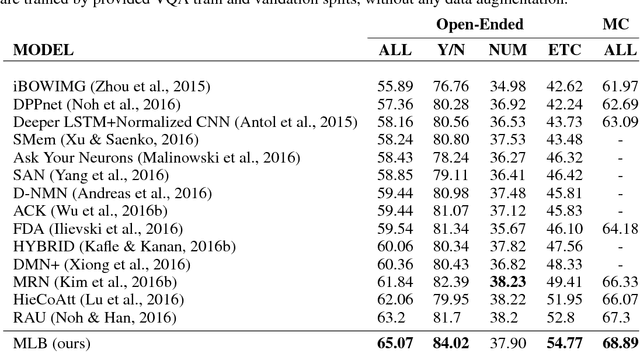

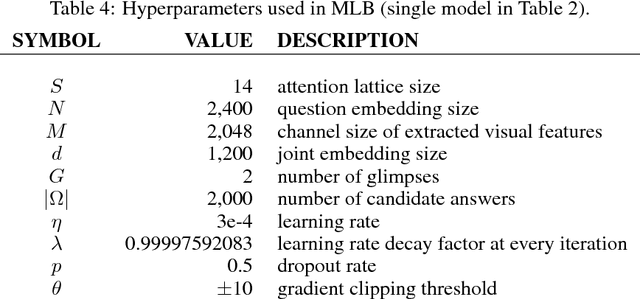
Bilinear models provide rich representations compared with linear models. They have been applied in various visual tasks, such as object recognition, segmentation, and visual question-answering, to get state-of-the-art performances taking advantage of the expanded representations. However, bilinear representations tend to be high-dimensional, limiting the applicability to computationally complex tasks. We propose low-rank bilinear pooling using Hadamard product for an efficient attention mechanism of multimodal learning. We show that our model outperforms compact bilinear pooling in visual question-answering tasks with the state-of-the-art results on the VQA dataset, having a better parsimonious property.