 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaEvolve: Adaptive LLM Driven Zeroth-Order Optimization
Feb 23, 2026The paradigm of automated program generation is shifting from one-shot generation to inference-time search, where Large Language Models (LLMs) function as semantic mutation operators within evolutionary loops. While effective, these systems are currently governed by static schedules that fail to account for the non-stationary dynamics of the search process. This rigidity results in substantial computational waste, as resources are indiscriminately allocated to stagnating populations while promising frontiers remain under-exploited. We introduce AdaEvolve, a framework that reformulates LLM-driven evolution as a hierarchical adaptive optimization problem. AdaEvolve uses an "accumulated improvement signal" to unify decisions across three levels: Local Adaptation, which dynamically modulates the exploration intensity within a population of solution candidates; Global Adaptation, which routes the global resource budget via bandit-based scheduling across different solution candidate populations; and Meta-Guidance which generates novel solution tactics based on the previously generated solutions and their corresponding improvements when the progress stalls. We demonstrate that AdaEvolve consistently outperforms the open-sourced baselines across 185 different open-ended optimization problems including combinatorial, systems optimization and algorithm design problems.
Agentic Test-Time Scaling for WebAgents
Feb 12, 2026Test-time scaling has become a standard way to improve performance and boost reliability of neural network models. However, its behavior on agentic, multi-step tasks remains less well-understood: small per-step errors can compound over long horizons; and we find that naive policies that uniformly increase sampling show diminishing returns. In this work, we present CATTS, a simple technique for dynamically allocating compute for multi-step agents. We first conduct an empirical study of inference-time scaling for web agents. We find that uniformly increasing per-step compute quickly saturates in long-horizon environments. We then investigate stronger aggregation strategies, including an LLM-based Arbiter that can outperform naive voting, but that can overrule high-consensus decisions. We show that uncertainty statistics derived from the agent's own vote distribution (entropy and top-1/top-2 margin) correlate with downstream success and provide a practical signal for dynamic compute allocation. Based on these findings, we introduce Confidence-Aware Test-Time Scaling (CATTS), which uses vote-derived uncertainty to allocate compute only when decisions are genuinely contentious. CATTS improves performance on WebArena-Lite and GoBrowse by up to 9.1% over React while using up to 2.3x fewer tokens than uniform scaling, providing both efficiency gains and an interpretable decision rule.
Plan-and-Act: Improving Planning of Agents for Long-Horizon Tasks
Mar 12, 2025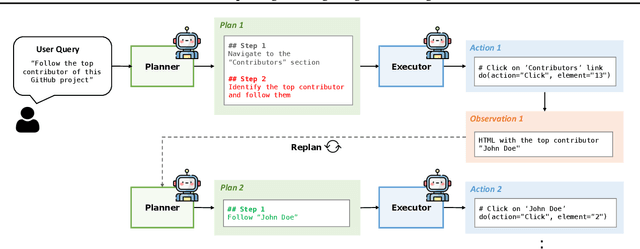
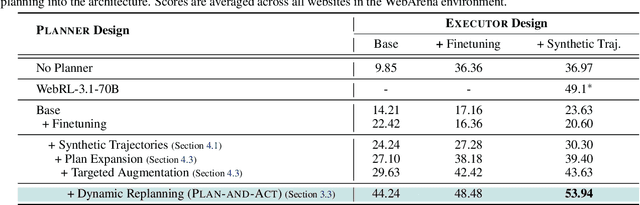
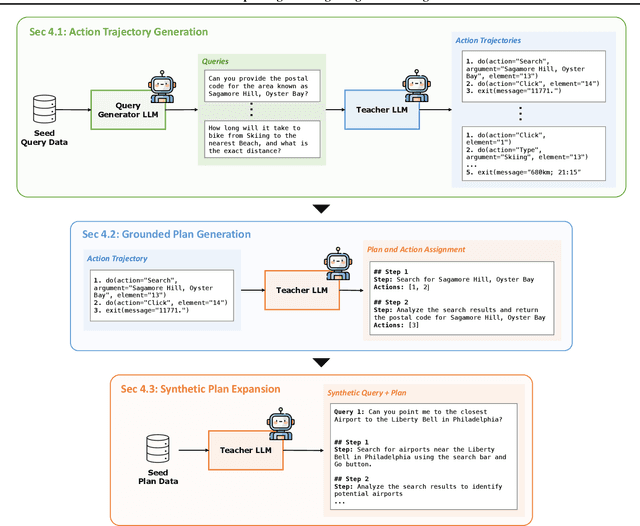
Large language models (LLMs) have shown remarkable advancements in enabling language agents to tackle simple tasks. However, applying them for complex, multi-step, long-horizon tasks remains a challenge. Recent work have found success by separating high-level planning from low-level execution, which enables the model to effectively balance high-level planning objectives and low-level execution details. However, generating accurate plans remains difficult since LLMs are not inherently trained for this task. To address this, we propose Plan-and-Act, a novel framework that incorporates explicit planning into LLM-based agents and introduces a scalable method to enhance plan generation through a novel synthetic data generation method. Plan-and-Act consists of a Planner model which generates structured, high-level plans to achieve user goals, and an Executor model that translates these plans into environment-specific actions. To train the Planner effectively, we introduce a synthetic data generation method that annotates ground-truth trajectories with feasible plans, augmented with diverse and extensive examples to enhance generalization. We evaluate Plan-and-Act using web navigation as a representative long-horizon planning environment, demonstrating a state-of the-art 54% success rate on the WebArena-Lite benchmark.
Stochastic Communication Avoidance for Recommendation Systems
Nov 03, 2024



One of the major bottlenecks for efficient deployment of neural network based recommendation systems is the memory footprint of their embedding tables. Although many neural network based recommendation systems could benefit from the faster on-chip memory access and increased computational power of hardware accelerators, the large embedding tables in these models often cannot fit on the constrained memory of accelerators. Despite the pervasiveness of these models, prior methods in memory optimization and parallelism fail to address the memory and communication costs of large embedding tables on accelerators. As a result, the majority of models are trained on CPUs, while current implementations of accelerators are hindered by issues such as bottlenecks in inter-device communication and main memory lookups. In this paper, we propose a theoretical framework that analyses the communication costs of arbitrary distributed systems that use lookup tables. We use this framework to propose algorithms that maximize throughput subject to memory, computation, and communication constraints. Furthermore, we demonstrate that our method achieves strong theoretical performance across dataset distributions and memory constraints, applicable to a wide range of use cases from mobile federated learning to warehouse-scale computation. We implement our framework and algorithms in PyTorch and achieve up to 6x increases in training throughput on GPU systems over baselines, on the Criteo Terabytes dataset.
Efficient and Scalable Estimation of Tool Representations in Vector Space
Sep 02, 2024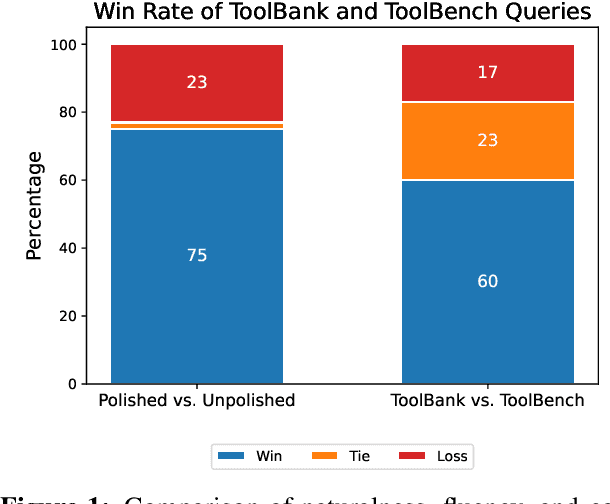
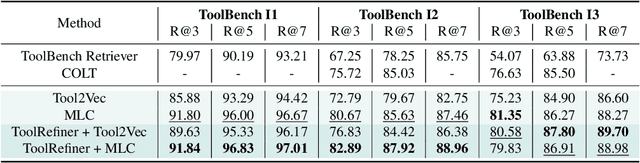
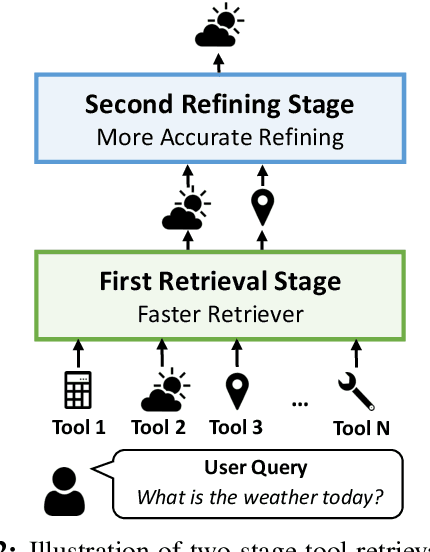
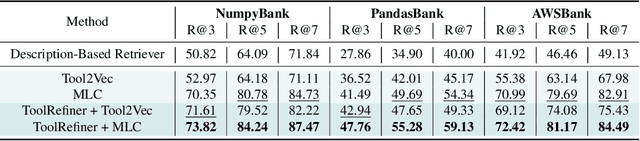
Recent advancements in function calling and tool use have significantly enhanced the capabilities of large language models (LLMs) by enabling them to interact with external information sources and execute complex tasks. However, the limited context window of LLMs presents challenges when a large number of tools are available, necessitating efficient methods to manage prompt length and maintain accuracy. Existing approaches, such as fine-tuning LLMs or leveraging their reasoning capabilities, either require frequent retraining or incur significant latency overhead. A more efficient solution involves training smaller models to retrieve the most relevant tools for a given query, although this requires high quality, domain-specific data. To address those challenges, we present a novel framework for generating synthetic data for tool retrieval applications and an efficient data-driven tool retrieval strategy using small encoder models. Empowered by LLMs, we create ToolBank, a new tool retrieval dataset that reflects real human user usages. For tool retrieval methodologies, we propose novel approaches: (1) Tool2Vec: usage-driven tool embedding generation for tool retrieval, (2) ToolRefiner: a staged retrieval method that iteratively improves the quality of retrieved tools, and (3) MLC: framing tool retrieval as a multi-label classification problem. With these new methods, we achieve improvements of up to 27.28 in Recall@K on the ToolBench dataset and 30.5 in Recall@K on ToolBank. Additionally, we present further experimental results to rigorously validate our methods. Our code is available at \url{https://github.com/SqueezeAILab/Tool2Vec}
TinyAgent: Function Calling at the Edge
Sep 01, 2024



Recent large language models (LLMs) have enabled the development of advanced agentic systems that can integrate various tools and APIs to fulfill user queries through function calling. However, the deployment of these LLMs on the edge has not been explored since they typically require cloud-based infrastructure due to their substantial model size and computational demands. To this end, we present TinyAgent, an end-to-end framework for training and deploying task-specific small language model agents capable of function calling for driving agentic systems at the edge. We first show how to enable accurate function calling for open-source models via the LLMCompiler framework. We then systematically curate a high-quality dataset for function calling, which we use to fine-tune two small language models, TinyAgent-1.1B and 7B. For efficient inference, we introduce a novel tool retrieval method to reduce the input prompt length and utilize quantization to further accelerate the inference speed. As a driving application, we demonstrate a local Siri-like system for Apple's MacBook that can execute user commands through text or voice input. Our results show that our models can achieve, and even surpass, the function-calling capabilities of larger models like GPT-4-Turbo, while being fully deployed at the edge. We open-source our dataset, models, and installable package and provide a demo video for our MacBook assistant agent.
Characterizing Prompt Compression Methods for Long Context Inference
Jul 11, 2024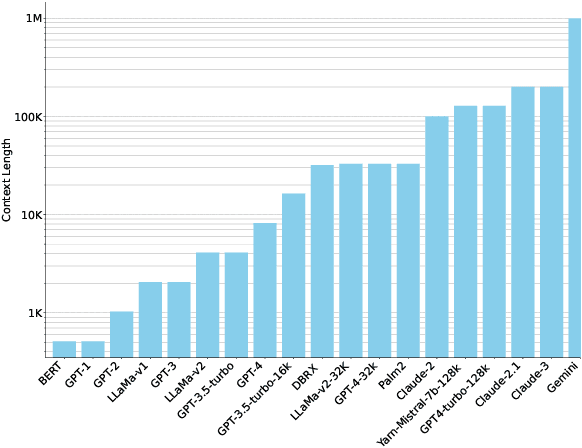
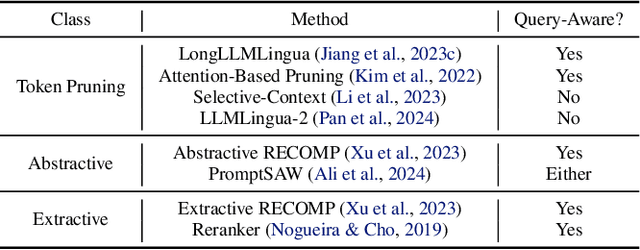
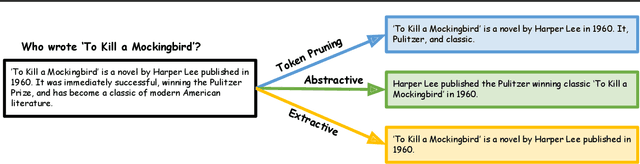

Long context inference presents challenges at the system level with increased compute and memory requirements, as well as from an accuracy perspective in being able to reason over long contexts. Recently, several methods have been proposed to compress the prompt to reduce the context length. However, there has been little work on comparing the different proposed methods across different tasks through a standardized analysis. This has led to conflicting results. To address this, here we perform a comprehensive characterization and evaluation of different prompt compression methods. In particular, we analyze extractive compression, summarization-based abstractive compression, and token pruning methods. Surprisingly, we find that extractive compression often outperforms all the other approaches, and enables up to 10x compression with minimal accuracy degradation. Interestingly, we also find that despite several recent claims, token pruning methods often lag behind extractive compression. We only found marginal improvements on summarization tasks.