 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeculative Interaction Agents: Building Real-Time Agents with Asynchronous I/O and Speculative Tool Calling
May 14, 2026There is a growing demand for agentic AI technologies for a range of downstream applications like customer service and personal assistants. For applications where the agent needs to interact with a person, real-time low-latency responsiveness is required; for example, with voice-controlled applications, under 1 second of latency is typically required for the interaction to feel seamless. However, if we want the LLM to reason and execute an agentic workflow with tool calling, this can add several seconds or more of latency, which is prohibitive for real-time latency-sensitive applications. In our work, we propose Speculative Interaction Agents to enable real-time interaction even for agents with complex multi-turn tool calling. We propose Asynchronous I/O, which decouples the core agent reason-and-act thread from waiting for additional information from either the user or environment, thereby allowing for overlapping agentic processing while waiting on external delays. We also propose Speculative Tool Calling as a method to manage task execution when the agent is still unsure if it has received the full information or if additional user information may later be provided. For strong cloud models, our method can be applied out-of-the-box to existing real-time cloud APIs, providing 1.3-1.7$\times$ speedups with minor accuracy loss. To enable real-time interaction with small edge-scale models, we also present a clock-based training methodology that adapts the model to handle streaming inputs and asynchronous responses, and demonstrate a synthetic data generation strategy for SFT. Altogether, this approach provides 1.6-2.2$\times$ speedups with the Qwen2.5-3B-Instruct and Llama-3.2-3B-Instruct models across multiple tool calling benchmarks.
LoSA: Locality Aware Sparse Attention for Block-Wise Diffusion Language Models
Apr 13, 2026Block-wise diffusion language models (DLMs) generate multiple tokens in any order, offering a promising alternative to the autoregressive decoding pipeline. However, they still remain bottlenecked by memory-bound attention in long-context scenarios. Naive sparse attention fails on DLMs due to a KV Inflation problem, where different queries select different prefix positions, making the union of accessed KV pages large. To address this, we observe that between consecutive denoising steps, only a small fraction of active tokens exhibit significant hidden-state changes, while the majority of stable tokens remain nearly constant. Based on this insight, we propose LOSA (Locality-aware Sparse Attention), which reuses cached prefix-attention results for stable tokens and applies sparse attention only to active tokens. This substantially shrinks the number of KV indices that must be loaded, yielding both higher speedup and higher accuracy. Across multiple block-wise DLMs and benchmarks, LOSA preserves near-dense accuracy while significantly improving efficiency, achieving up to +9 points in average accuracy at aggressive sparsity levels while maintaining 1.54x lower attention density. It also achieves up to 4.14x attention speedup on RTX A6000 GPUs, demonstrating the effectiveness of the proposed method.
Squeeze Evolve: Unified Multi-Model Orchestration for Verifier-Free Evolution
Apr 09, 2026We show that verifier-free evolution is bottlenecked by both diversity and efficiency: without external correction, repeated evolution accelerates collapse toward narrow modes, while the uniform use of a high-cost model wastes compute and quickly becomes economically impractical. We introduce Squeeze Evolve, a unified multi-model orchestration framework for verifier-free evolutionary inference. Our approach is guided by a simple principle: allocate model capability where it has the highest marginal utility. Stronger models are reserved for high-impact stages, while cheaper models handle the other stages at much lower costs. This principle addresses diversity and cost-efficiency jointly while remaining lightweight. Squeeze Evolve naturally supports open-source, closed-source, and mixed-model deployments. Across AIME 2025, HMMT 2025, LiveCodeBench V6, GPQA-Diamond, ARC-AGI-V2, and multimodal vision benchmarks, such as MMMU-Pro and BabyVision, Squeeze Evolve consistently improves the cost-capability frontier over single-model evolution and achieves new state-of-the-art results on several tasks. Empirically, Squeeze Evolve reduces API cost by up to $\sim$3$\times$ and increases fixed-budget serving throughput by up to $\sim$10$\times$. Moreover, on discovery tasks, Squeeze Evolve is the first verifier-free evolutionary method to match, and in some cases exceed, the performance of verifier-based evolutionary methods.
Residual Context Diffusion Language Models
Jan 30, 2026Diffusion Large Language Models (dLLMs) have emerged as a promising alternative to purely autoregressive language models because they can decode multiple tokens in parallel. However, state-of-the-art block-wise dLLMs rely on a "remasking" mechanism that decodes only the most confident tokens and discards the rest, effectively wasting computation. We demonstrate that recycling computation from the discarded tokens is beneficial, as these tokens retain contextual information useful for subsequent decoding iterations. In light of this, we propose Residual Context Diffusion (RCD), a module that converts these discarded token representations into contextual residuals and injects them back for the next denoising step. RCD uses a decoupled two-stage training pipeline to bypass the memory bottlenecks associated with backpropagation. We validate our method on both long CoT reasoning (SDAR) and short CoT instruction following (LLaDA) models. We demonstrate that a standard dLLM can be efficiently converted to the RCD paradigm with merely ~1 billion tokens. RCD consistently improves frontier dLLMs by 5-10 points in accuracy with minimal extra computation overhead across a wide range of benchmarks. Notably, on the most challenging AIME tasks, RCD nearly doubles baseline accuracy and attains up to 4-5x fewer denoising steps at equivalent accuracy levels.
ParallelBench: Understanding the Trade-offs of Parallel Decoding in Diffusion LLMs
Oct 06, 2025While most autoregressive LLMs are constrained to one-by-one decoding, diffusion LLMs (dLLMs) have attracted growing interest for their potential to dramatically accelerate inference through parallel decoding. Despite this promise, the conditional independence assumption in dLLMs causes parallel decoding to ignore token dependencies, inevitably degrading generation quality when these dependencies are strong. However, existing works largely overlook these inherent challenges, and evaluations on standard benchmarks (e.g., math and coding) are not sufficient to capture the quality degradation caused by parallel decoding. To address this gap, we first provide an information-theoretic analysis of parallel decoding. We then conduct case studies on analytically tractable synthetic list operations from both data distribution and decoding strategy perspectives, offering quantitative insights that highlight the fundamental limitations of parallel decoding. Building on these insights, we propose ParallelBench, the first benchmark specifically designed for dLLMs, featuring realistic tasks that are trivial for humans and autoregressive LLMs yet exceptionally challenging for dLLMs under parallel decoding. Using ParallelBench, we systematically analyze both dLLMs and autoregressive LLMs, revealing that: (i) dLLMs under parallel decoding can suffer dramatic quality degradation in real-world scenarios, and (ii) current parallel decoding strategies struggle to adapt their degree of parallelism based on task difficulty, thus failing to achieve meaningful speedup without compromising quality. Our findings underscore the pressing need for innovative decoding methods that can overcome the current speed-quality trade-off. We release our benchmark to help accelerate the development of truly efficient dLLMs.
XQuant: Breaking the Memory Wall for LLM Inference with KV Cache Rematerialization
Aug 14, 2025Although LLM inference has emerged as a critical workload for many downstream applications, efficiently inferring LLMs is challenging due to the substantial memory footprint and bandwidth requirements. In parallel, compute capabilities have steadily outpaced both memory capacity and bandwidth over the last few decades, a trend that remains evident in modern GPU hardware and exacerbates the challenge of LLM inference. As such, new algorithms are emerging that trade increased computation for reduced memory operations. To that end, we present XQuant, which takes advantage of this trend, enabling an order-of-magnitude reduction in memory consumption through low-bit quantization with substantial accuracy benefits relative to state-of-the-art KV cache quantization methods. We accomplish this by quantizing and caching the layer input activations X, instead of using standard KV caching, and then rematerializing the Keys and Values on-the-fly during inference. This results in an immediate 2$\times$ memory savings compared to KV caching. By applying XQuant, we achieve up to $\sim 7.7\times$ memory savings with $<0.1$ perplexity degradation compared to the FP16 baseline. Furthermore, our approach leverages the fact that X values are similar across layers. Building on this observation, we introduce XQuant-CL, which exploits the cross-layer similarity in the X embeddings for extreme compression. Across different models, XQuant-CL attains up to 10$\times$ memory savings relative to the FP16 baseline with only 0.01 perplexity degradation, and 12.5$\times$ memory savings with only $0.1$ perplexity degradation. XQuant exploits the rapidly increasing compute capabilities of hardware platforms to eliminate the memory bottleneck, while surpassing state-of-the-art KV cache quantization methods and achieving near-FP16 accuracy across a wide range of models.
Multipole Attention for Efficient Long Context Reasoning
Jun 16, 2025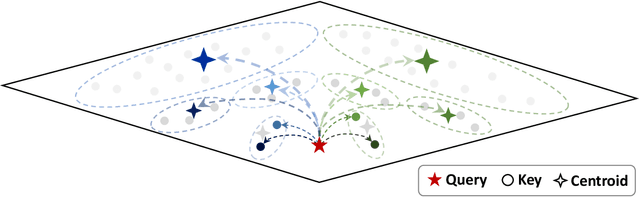

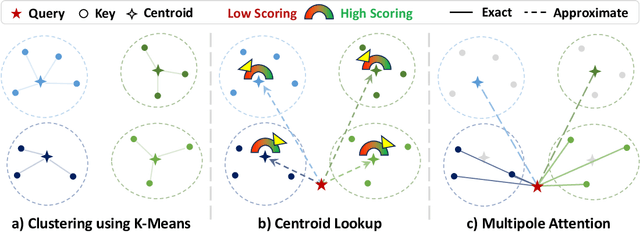
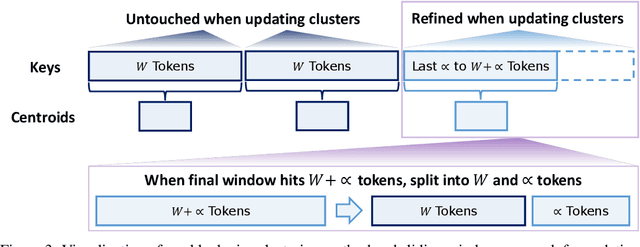
Large Reasoning Models (LRMs) have shown promising accuracy improvements on complex problem-solving tasks. While these models have attained high accuracy by leveraging additional computation at test time, they need to generate long chain-of-thought reasoning in order to think before answering, which requires generating thousands of tokens. While sparse attention methods can help reduce the KV cache pressure induced by this long autoregressive reasoning, these methods can introduce errors which disrupt the reasoning process. Additionally, prior methods often pre-process the input to make it easier to identify the important prompt tokens when computing attention during generation, and this pre-processing is challenging to perform online for newly generated reasoning tokens. Our work addresses these challenges by introducing Multipole Attention, which accelerates autoregressive reasoning by only computing exact attention for the most important tokens, while maintaining approximate representations for the remaining tokens. Our method first performs clustering to group together semantically similar key vectors, and then uses the cluster centroids both to identify important key vectors and to approximate the remaining key vectors in order to retain high accuracy. We design a fast cluster update process to quickly re-cluster the input and previously generated tokens, thereby allowing for accelerating attention to the previous output tokens. We evaluate our method using emerging LRMs such as Qwen-8B, demonstrating that our approach can maintain accuracy on complex reasoning tasks even with aggressive attention sparsity settings. We also provide kernel implementations to demonstrate the practical efficiency gains from our method, achieving up to 4.5$\times$ speedup for attention in long-context reasoning applications. Our code is available at https://github.com/SqueezeAILab/MultipoleAttention.
FGMP: Fine-Grained Mixed-Precision Weight and Activation Quantization for Hardware-Accelerated LLM Inference
Apr 19, 2025Quantization is a powerful tool to improve large language model (LLM) inference efficiency by utilizing more energy-efficient low-precision datapaths and reducing memory footprint. However, accurately quantizing LLM weights and activations to low precision is challenging without degrading model accuracy. We propose fine-grained mixed precision (FGMP) quantization, a post-training mixed-precision quantization hardware-software co-design methodology that maintains accuracy while quantizing the majority of weights and activations to reduced precision. Our work makes the following contributions: 1) We develop a policy that uses the perturbation in each value, weighted by the Fisher information, to select which weight and activation blocks to keep in higher precision. This approach preserves accuracy by identifying which weight and activation blocks need to be retained in higher precision to minimize the perturbation in the model loss. 2) We also propose a sensitivity-weighted clipping approach for fine-grained quantization which helps retain accuracy for blocks that are quantized to low precision. 3) We then propose hardware augmentations to leverage the efficiency benefits of FGMP quantization. Our hardware implementation encompasses i) datapath support for FGMP at block granularity, and ii) a mixed-precision activation quantization unit to assign activation blocks to high or low precision on the fly with minimal runtime and energy overhead. Our design, prototyped using NVFP4 (an FP4 format with microscaling) as the low-precision datatype and FP8 as the high-precision datatype, facilitates efficient FGMP quantization, attaining <1% perplexity degradation on Wikitext-103 for the Llama-2-7B model relative to an all-FP8 baseline design while consuming 14% less energy during inference and requiring 30% less weight memory.
ETS: Efficient Tree Search for Inference-Time Scaling
Feb 19, 2025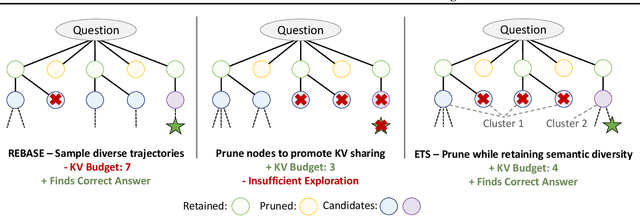
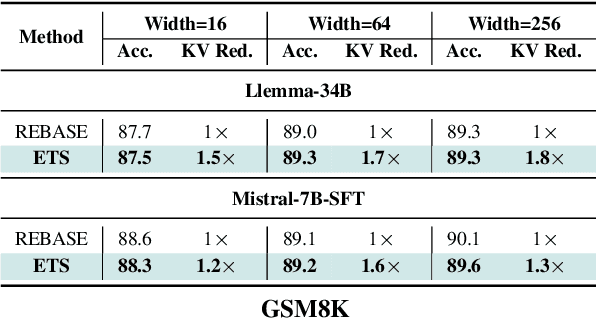
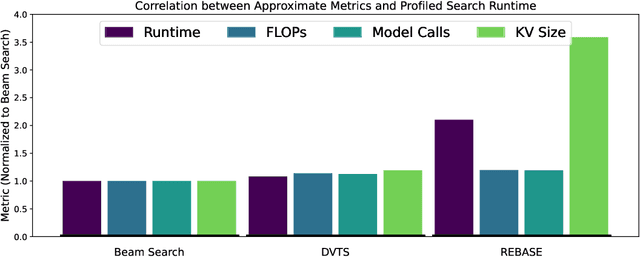
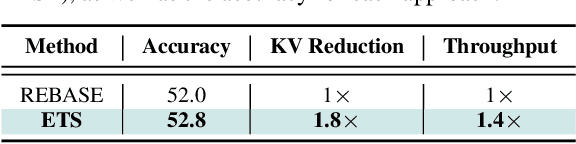
Test-time compute scaling has emerged as a new axis along which to improve model accuracy, where additional computation is used at inference time to allow the model to think longer for more challenging problems. One promising approach for test-time compute scaling is search against a process reward model, where a model generates multiple potential candidates at each step of the search, and these partial trajectories are then scored by a separate reward model in order to guide the search process. The diversity of trajectories in the tree search process affects the accuracy of the search, since increasing diversity promotes more exploration. However, this diversity comes at a cost, as divergent trajectories have less KV sharing, which means they consume more memory and slow down the search process. Previous search methods either do not perform sufficient exploration, or else explore diverse trajectories but have high latency. We address this challenge by proposing Efficient Tree Search (ETS), which promotes KV sharing by pruning redundant trajectories while maintaining necessary diverse trajectories. ETS incorporates a linear programming cost model to promote KV cache sharing by penalizing the number of nodes retained, while incorporating a semantic coverage term into the cost model to ensure that we retain trajectories which are semantically different. We demonstrate how ETS can achieve 1.8$\times$ reduction in average KV cache size during the search process, leading to 1.4$\times$ increased throughput relative to prior state-of-the-art methods, with minimal accuracy degradation and without requiring any custom kernel implementation. Code is available at: https://github.com/SqueezeAILab/ETS.
Squeezed Attention: Accelerating Long Context Length LLM Inference
Nov 14, 2024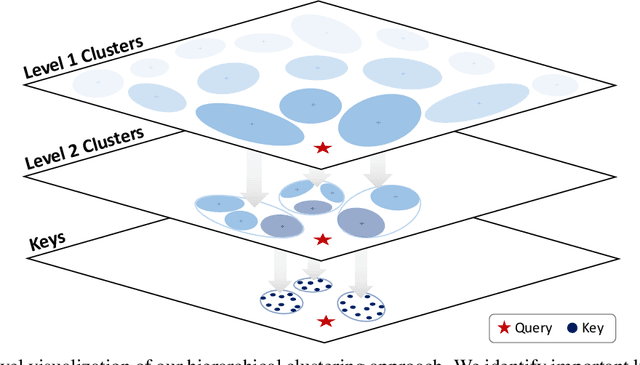
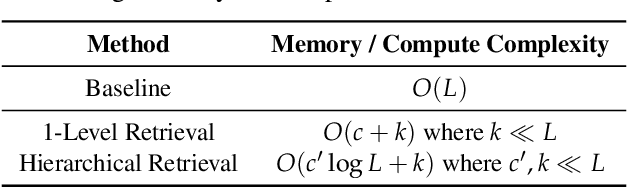
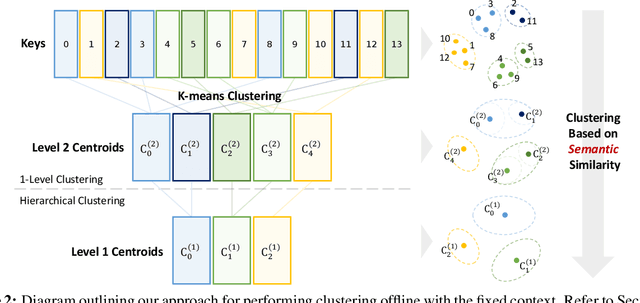
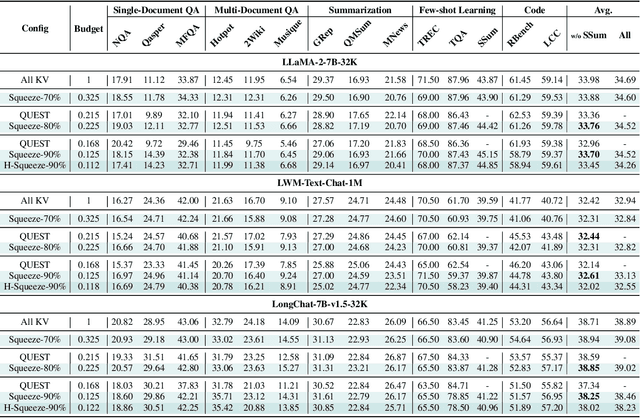
Emerging Large Language Model (LLM) applications require long input prompts to perform complex downstream tasks like document analysis and code generation. For these long context length applications, the length of the input prompt poses a significant challenge in terms of inference efficiency since the inference costs increase linearly with sequence length. However, for many of these applications, much of the context in the prompt is fixed across different user inputs, thereby providing the opportunity to perform offline optimizations to process user inputs quickly, as they are received. In this work, we propose Squeezed Attention as a mechanism to accelerate LLM applications where a large portion of the input prompt is fixed. We first leverage K-means clustering offline to group the keys for the fixed context based on semantic similarity and represent each cluster with a single centroid value. During inference, we compare query tokens from the user input with the centroids to predict which of the keys from the fixed context are semantically relevant and need to be loaded during inference. We then compute exact attention using only these important keys from the fixed context, thereby reducing bandwidth and computational costs. We also extend our method to use a hierarchical centroid lookup to identify important keys, which can reduce the complexity of attention from linear to logarithmic with respect to the context length. We implement optimized Triton kernels for centroid comparison and sparse FlashAttention with important keys, achieving more than 4x speedups during both the prefill and generation phases for long-context inference. Furthermore, we have extensively evaluated our method on various long-context benchmarks including LongBench, where it achieves a 3x reduction in KV cache budget without accuracy loss and up to an 8x reduction with <0.5 point accuracy gap for various models.