 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSqueezed Attention: Accelerating Long Context Length LLM Inference
Nov 14, 2024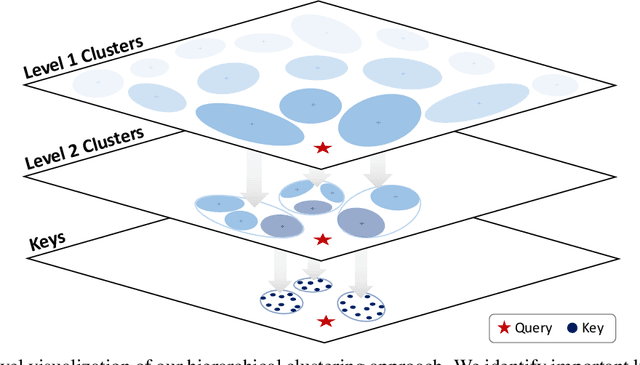
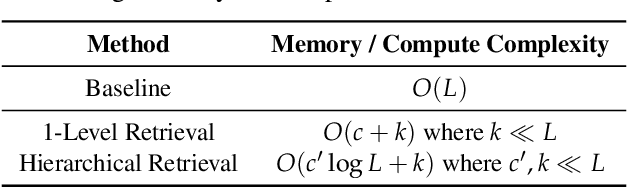
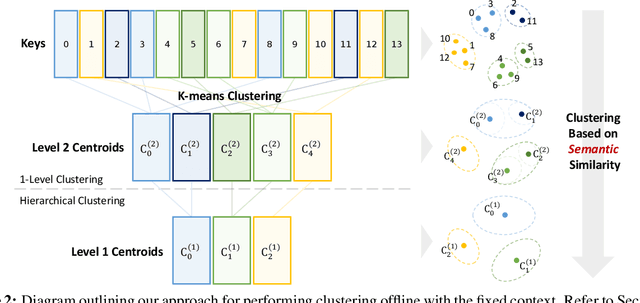
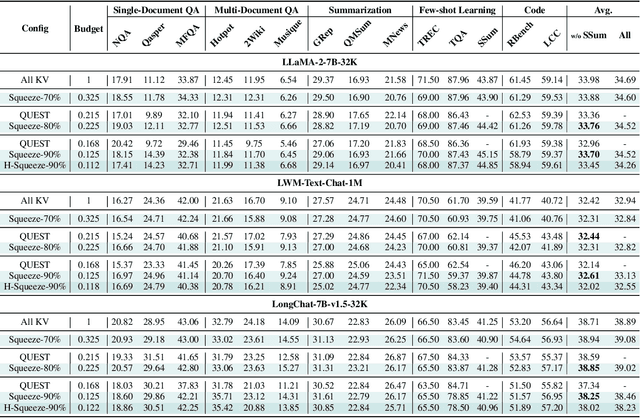
Emerging Large Language Model (LLM) applications require long input prompts to perform complex downstream tasks like document analysis and code generation. For these long context length applications, the length of the input prompt poses a significant challenge in terms of inference efficiency since the inference costs increase linearly with sequence length. However, for many of these applications, much of the context in the prompt is fixed across different user inputs, thereby providing the opportunity to perform offline optimizations to process user inputs quickly, as they are received. In this work, we propose Squeezed Attention as a mechanism to accelerate LLM applications where a large portion of the input prompt is fixed. We first leverage K-means clustering offline to group the keys for the fixed context based on semantic similarity and represent each cluster with a single centroid value. During inference, we compare query tokens from the user input with the centroids to predict which of the keys from the fixed context are semantically relevant and need to be loaded during inference. We then compute exact attention using only these important keys from the fixed context, thereby reducing bandwidth and computational costs. We also extend our method to use a hierarchical centroid lookup to identify important keys, which can reduce the complexity of attention from linear to logarithmic with respect to the context length. We implement optimized Triton kernels for centroid comparison and sparse FlashAttention with important keys, achieving more than 4x speedups during both the prefill and generation phases for long-context inference. Furthermore, we have extensively evaluated our method on various long-context benchmarks including LongBench, where it achieves a 3x reduction in KV cache budget without accuracy loss and up to an 8x reduction with <0.5 point accuracy gap for various models.
KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization
Feb 07, 2024LLMs are seeing growing use for applications such as document analysis and summarization which require large context windows, and with these large context windows KV cache activations surface as the dominant contributor to memory consumption during inference. Quantization is a promising approach for compressing KV cache activations; however, existing solutions fail to represent activations accurately in ultra-low precisions, such as sub-4-bit. In this work, we present KVQuant, which addresses this problem by incorporating novel methods for quantizing cached KV activations, including: (i) Per-Channel Key Quantization, where we adjust the dimension along which we quantize the Key activations to better match the distribution; (ii) Pre-RoPE Key Quantization, where we quantize Key activations before the rotary positional embedding to mitigate its impact on quantization; (iii) Non-Uniform KV Cache Quantization, where we derive per-layer sensitivity-weighted non-uniform datatypes that better represent the distributions; (iv) Per-Vector Dense-and-Sparse Quantization, where we isolate outliers separately for each vector to minimize skews in quantization ranges; and (v) Q-Norm, where we normalize quantization centroids in order to mitigate distribution shift, providing additional benefits for 2-bit quantization. By applying our method to the LLaMA, LLaMA-2, and Mistral models, we achieve $<0.1$ perplexity degradation with 3-bit quantization on both Wikitext-2 and C4, outperforming existing approaches. Our method enables serving the LLaMA-7B model with a context length of up to 1 million on a single A100-80GB GPU and up to 10 million on an 8-GPU system.
SPEED: Speculative Pipelined Execution for Efficient Decoding
Oct 18, 2023Generative Large Language Models (LLMs) based on the Transformer architecture have recently emerged as a dominant foundation model for a wide range of Natural Language Processing tasks. Nevertheless, their application in real-time scenarios has been highly restricted due to the significant inference latency associated with these models. This is particularly pronounced due to the autoregressive nature of generative LLM inference, where tokens are generated sequentially since each token depends on all previous output tokens. It is therefore challenging to achieve any token-level parallelism, making inference extremely memory-bound. In this work, we propose SPEED, which improves inference efficiency by speculatively executing multiple future tokens in parallel with the current token using predicted values based on early-layer hidden states. For Transformer decoders that employ parameter sharing, the memory operations for the tokens executing in parallel can be amortized, which allows us to accelerate generative LLM inference. We demonstrate the efficiency of our method in terms of latency reduction relative to model accuracy and demonstrate how speculation allows for training deeper decoders with parameter sharing with minimal runtime overhead.