 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinKV: Thought-Adaptive KV Cache Compression for Efficient Reasoning Models
Oct 01, 2025The long-output context generation of large reasoning models enables extended chain of thought (CoT) but also drives rapid growth of the key-value (KV) cache, quickly overwhelming GPU memory. To address this challenge, we propose ThinKV, a thought-adaptive KV cache compression framework. ThinKV is based on the observation that attention sparsity reveals distinct thought types with varying importance within the CoT. It applies a hybrid quantization-eviction strategy, assigning token precision by thought importance and progressively evicting tokens from less critical thoughts as reasoning trajectories evolve. Furthermore, to implement ThinKV, we design a kernel that extends PagedAttention to enable efficient reuse of evicted tokens' memory slots, eliminating compaction overheads. Extensive experiments on DeepSeek-R1-Distill, GPT-OSS, and NVIDIA AceReason across mathematics and coding benchmarks show that ThinKV achieves near-lossless accuracy with less than 5% of the original KV cache, while improving performance with up to 5.8x higher inference throughput over state-of-the-art baselines.
FGMP: Fine-Grained Mixed-Precision Weight and Activation Quantization for Hardware-Accelerated LLM Inference
Apr 19, 2025Quantization is a powerful tool to improve large language model (LLM) inference efficiency by utilizing more energy-efficient low-precision datapaths and reducing memory footprint. However, accurately quantizing LLM weights and activations to low precision is challenging without degrading model accuracy. We propose fine-grained mixed precision (FGMP) quantization, a post-training mixed-precision quantization hardware-software co-design methodology that maintains accuracy while quantizing the majority of weights and activations to reduced precision. Our work makes the following contributions: 1) We develop a policy that uses the perturbation in each value, weighted by the Fisher information, to select which weight and activation blocks to keep in higher precision. This approach preserves accuracy by identifying which weight and activation blocks need to be retained in higher precision to minimize the perturbation in the model loss. 2) We also propose a sensitivity-weighted clipping approach for fine-grained quantization which helps retain accuracy for blocks that are quantized to low precision. 3) We then propose hardware augmentations to leverage the efficiency benefits of FGMP quantization. Our hardware implementation encompasses i) datapath support for FGMP at block granularity, and ii) a mixed-precision activation quantization unit to assign activation blocks to high or low precision on the fly with minimal runtime and energy overhead. Our design, prototyped using NVFP4 (an FP4 format with microscaling) as the low-precision datatype and FP8 as the high-precision datatype, facilitates efficient FGMP quantization, attaining <1% perplexity degradation on Wikitext-103 for the Llama-2-7B model relative to an all-FP8 baseline design while consuming 14% less energy during inference and requiring 30% less weight memory.
SQ-DM: Accelerating Diffusion Models with Aggressive Quantization and Temporal Sparsity
Jan 26, 2025Diffusion models have gained significant popularity in image generation tasks. However, generating high-quality content remains notably slow because it requires running model inference over many time steps. To accelerate these models, we propose to aggressively quantize both weights and activations, while simultaneously promoting significant activation sparsity. We further observe that the stated sparsity pattern varies among different channels and evolves across time steps. To support this quantization and sparsity scheme, we present a novel diffusion model accelerator featuring a heterogeneous mixed-precision dense-sparse architecture, channel-last address mapping, and a time-step-aware sparsity detector for efficient handling of the sparsity pattern. Our 4-bit quantization technique demonstrates superior generation quality compared to existing 4-bit methods. Our custom accelerator achieves 6.91x speed-up and 51.5% energy reduction compared to traditional dense accelerators.
Enabling and Accelerating Dynamic Vision Transformer Inference for Real-Time Applications
Dec 06, 2022Many state-of-the-art deep learning models for computer vision tasks are based on the transformer architecture. Such models can be computationally expensive and are typically statically set to meet the deployment scenario. However, in real-time applications, the resources available for every inference can vary considerably and be smaller than what state-of-the-art models use. We can use dynamic models to adapt the model execution to meet real-time application resource constraints. While prior dynamic work has primarily minimized resource utilization for less complex input images while maintaining accuracy and focused on CNNs and early transformer models such as BERT, we adapt vision transformers to meet system dynamic resource constraints, independent of the input image. We find that unlike early transformer models, recent state-of-the-art vision transformers heavily rely on convolution layers. We show that pretrained models are fairly resilient to skipping computation in the convolution and self-attention layers, enabling us to create a low-overhead system for dynamic real-time inference without additional training. Finally, we create a optimized accelerator for these dynamic vision transformers in a 5nm technology. The PE array occupies 2.26mm$^2$ and is 17 times faster than a NVIDIA TITAN V GPU for state-of-the-art transformer-based models for semantic segmentation.
Optimal Clipping and Magnitude-aware Differentiation for Improved Quantization-aware Training
Jun 13, 2022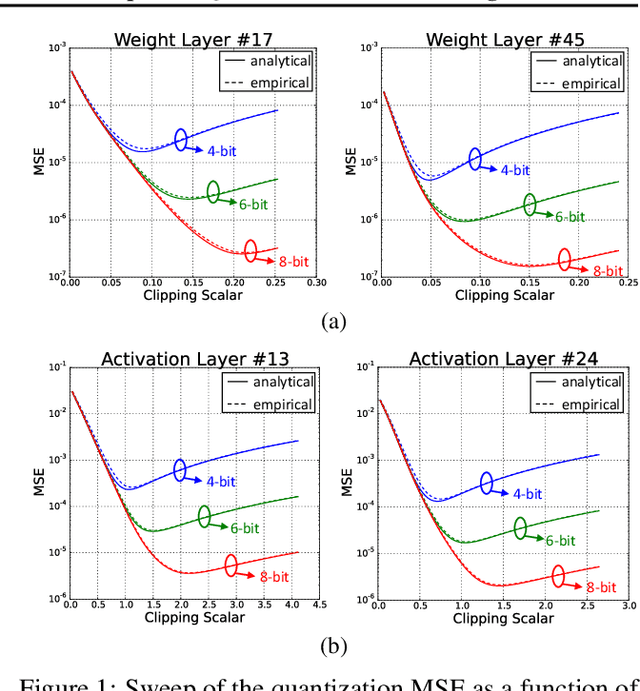

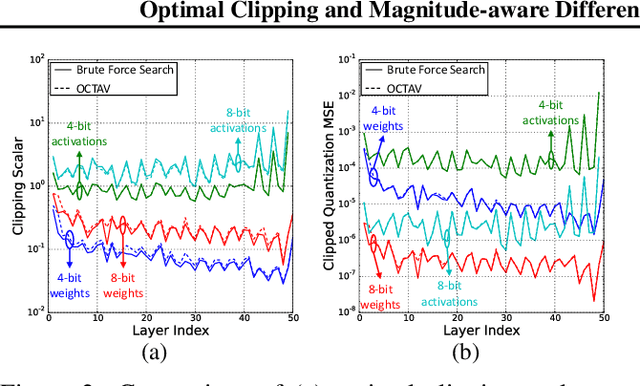
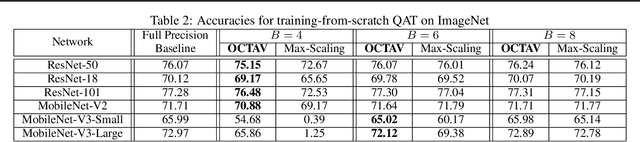
Data clipping is crucial in reducing noise in quantization operations and improving the achievable accuracy of quantization-aware training (QAT). Current practices rely on heuristics to set clipping threshold scalars and cannot be shown to be optimal. We propose Optimally Clipped Tensors And Vectors (OCTAV), a recursive algorithm to determine MSE-optimal clipping scalars. Derived from the fast Newton-Raphson method, OCTAV finds optimal clipping scalars on the fly, for every tensor, at every iteration of the QAT routine. Thus, the QAT algorithm is formulated with provably minimum quantization noise at each step. In addition, we reveal limitations in common gradient estimation techniques in QAT and propose magnitude-aware differentiation as a remedy to further improve accuracy. Experimentally, OCTAV-enabled QAT achieves state-of-the-art accuracy on multiple tasks. These include training-from-scratch and retraining ResNets and MobileNets on ImageNet, and Squad fine-tuning using BERT models, where OCTAV-enabled QAT consistently preserves accuracy at low precision (4-to-6-bits). Our results require no modifications to the baseline training recipe, except for the insertion of quantization operations where appropriate.
Low-Precision Training in Logarithmic Number System using Multiplicative Weight Update
Jun 26, 2021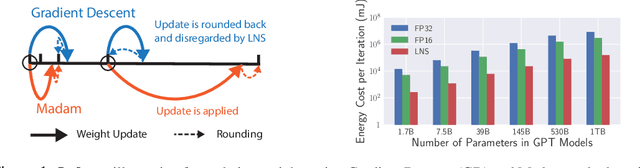
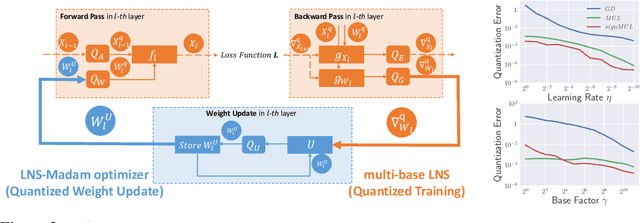
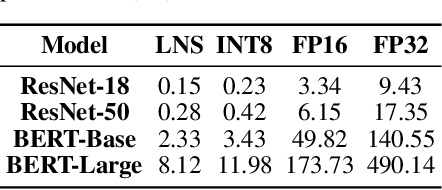
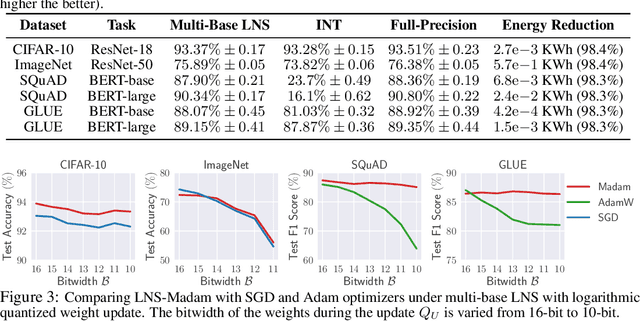
Training large-scale deep neural networks (DNNs) currently requires a significant amount of energy, leading to serious environmental impacts. One promising approach to reduce the energy costs is representing DNNs with low-precision numbers. While it is common to train DNNs with forward and backward propagation in low-precision, training directly over low-precision weights, without keeping a copy of weights in high-precision, still remains to be an unsolved problem. This is due to complex interactions between learning algorithms and low-precision number systems. To address this, we jointly design a low-precision training framework involving a logarithmic number system (LNS) and a multiplicative weight update training method, termed LNS-Madam. LNS has a high dynamic range even in a low-bitwidth setting, leading to high energy efficiency and making it relevant for on-board training in energy-constrained edge devices. We design LNS to have the flexibility of choosing different bases for weights and gradients, as they usually require different quantization gaps and dynamic ranges during training. By drawing the connection between LNS and multiplicative update, LNS-Madam ensures low quantization error during weight update, leading to a stable convergence even if the bitwidth is limited. Compared to using a fixed-point or floating-point number system and training with popular learning algorithms such as SGD and Adam, our joint design with LNS and LNS-Madam optimizer achieves better accuracy while requiring smaller bitwidth. Notably, with only 5-bit for gradients, the proposed training framework achieves accuracy comparable to full-precision state-of-the-art models such as ResNet-50 and BERT. After conducting energy estimations by analyzing the math datapath units during training, the results show that our design achieves over 60x energy reduction compared to FP32 on BERT models.
VS-Quant: Per-vector Scaled Quantization for Accurate Low-Precision Neural Network Inference
Feb 08, 2021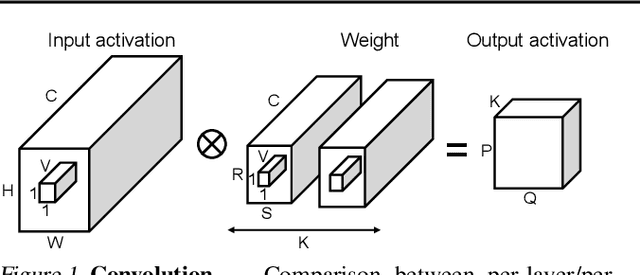
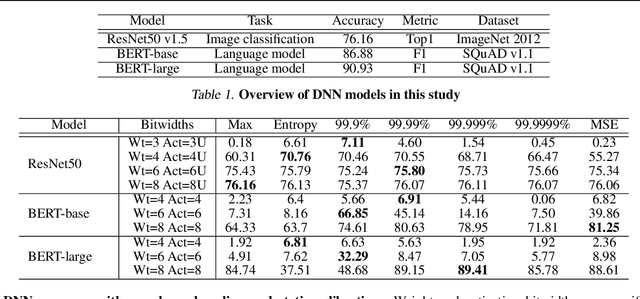
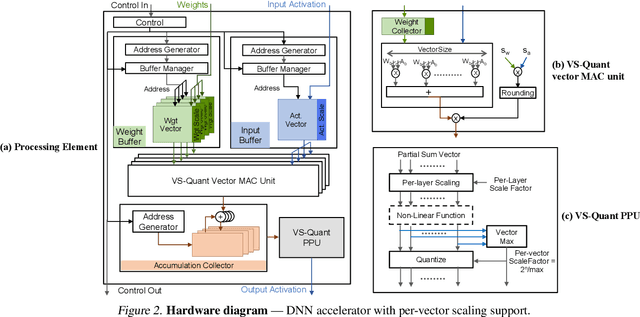
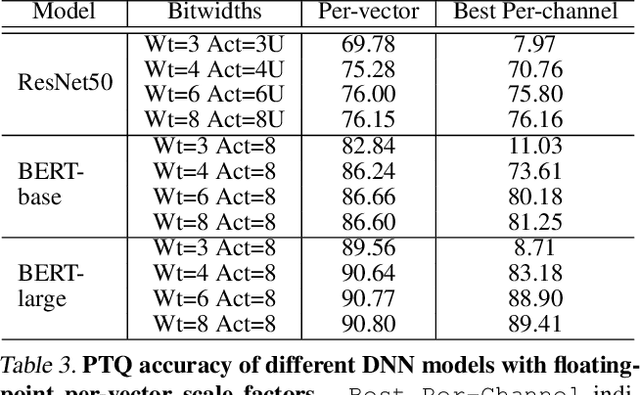
Quantization enables efficient acceleration of deep neural networks by reducing model memory footprint and exploiting low-cost integer math hardware units. Quantization maps floating-point weights and activations in a trained model to low-bitwidth integer values using scale factors. Excessive quantization, reducing precision too aggressively, results in accuracy degradation. When scale factors are shared at a coarse granularity across many dimensions of each tensor, effective precision of individual elements within the tensor are limited. To reduce quantization-related accuracy loss, we propose using a separate scale factor for each small vector of ($\approx$16-64) elements within a single dimension of a tensor. To achieve an efficient hardware implementation, the per-vector scale factors can be implemented with low-bitwidth integers when calibrated using a two-level quantization scheme. We find that per-vector scaling consistently achieves better inference accuracy at low precision compared to conventional scaling techniques for popular neural networks without requiring retraining. We also modify a deep learning accelerator hardware design to study the area and energy overheads of per-vector scaling support. Our evaluation demonstrates that per-vector scaled quantization with 4-bit weights and activations achieves 37% area saving and 24% energy saving while maintaining over 75% accuracy for ResNet50 on ImageNet. 4-bit weights and 8-bit activations achieve near-full-precision accuracy for both BERT-base and BERT-large on SQuAD while reducing area by 26% compared to an 8-bit baseline.
SCNN: An Accelerator for Compressed-sparse Convolutional Neural Networks
May 23, 2017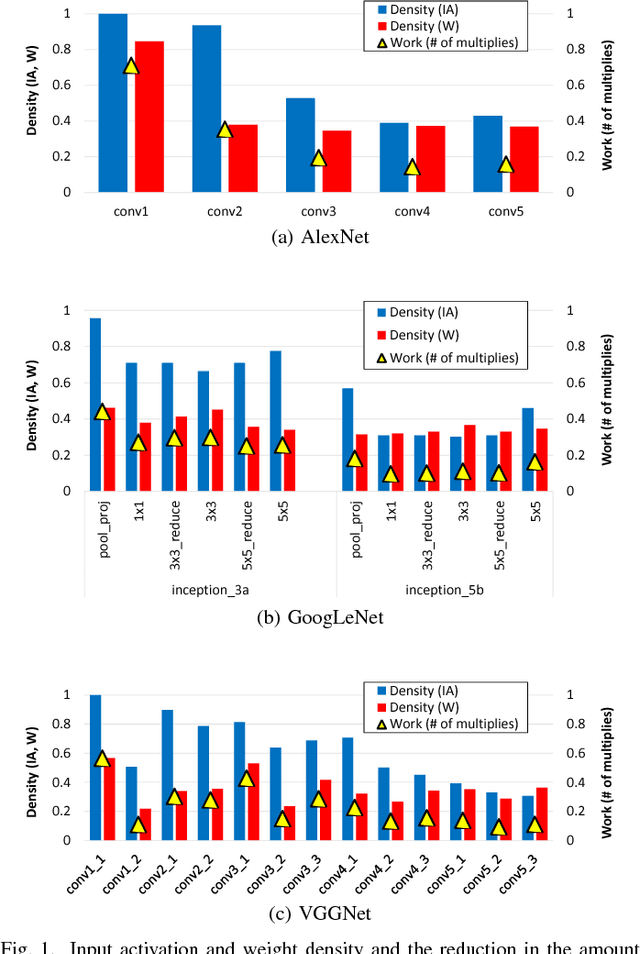
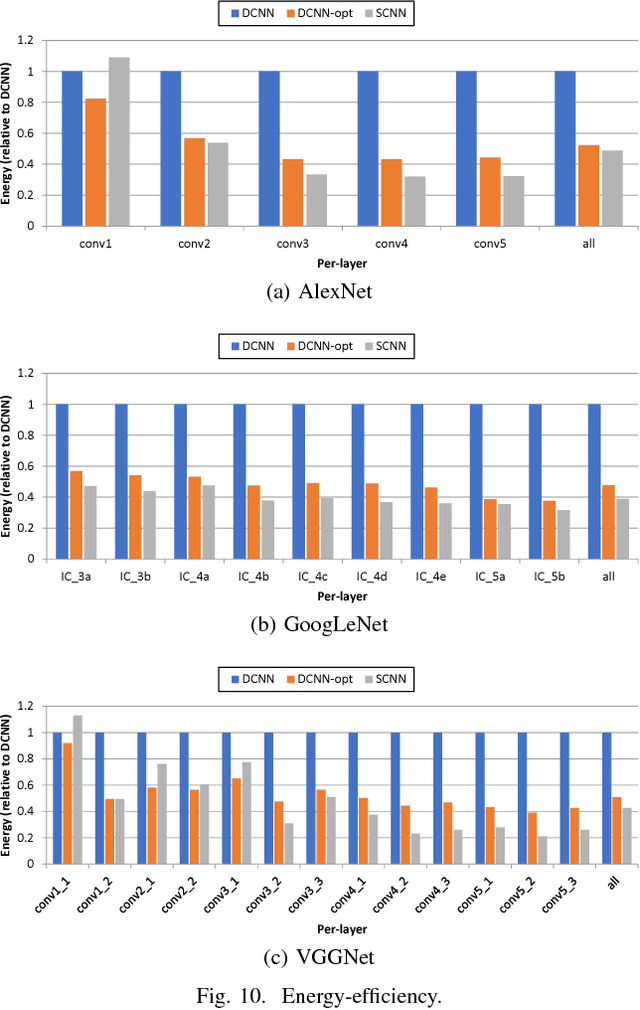
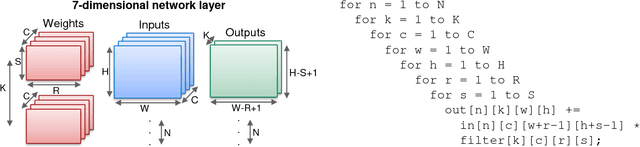

Convolutional Neural Networks (CNNs) have emerged as a fundamental technology for machine learning. High performance and extreme energy efficiency are critical for deployments of CNNs in a wide range of situations, especially mobile platforms such as autonomous vehicles, cameras, and electronic personal assistants. This paper introduces the Sparse CNN (SCNN) accelerator architecture, which improves performance and energy efficiency by exploiting the zero-valued weights that stem from network pruning during training and zero-valued activations that arise from the common ReLU operator applied during inference. Specifically, SCNN employs a novel dataflow that enables maintaining the sparse weights and activations in a compressed encoding, which eliminates unnecessary data transfers and reduces storage requirements. Furthermore, the SCNN dataflow facilitates efficient delivery of those weights and activations to the multiplier array, where they are extensively reused. In addition, the accumulation of multiplication products are performed in a novel accumulator array. Our results show that on contemporary neural networks, SCNN can improve both performance and energy by a factor of 2.7x and 2.3x, respectively, over a comparably provisioned dense CNN accelerator.