 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChipNeMo: Domain-Adapted LLMs for Chip Design
Nov 13, 2023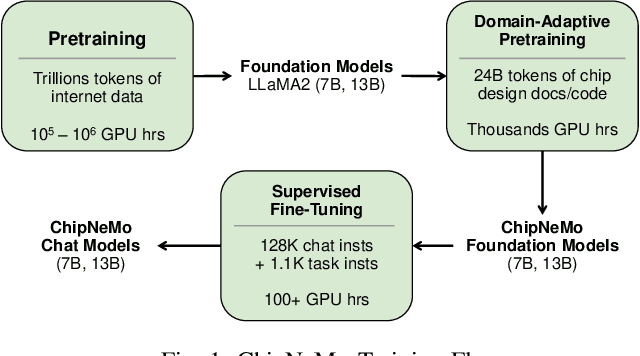
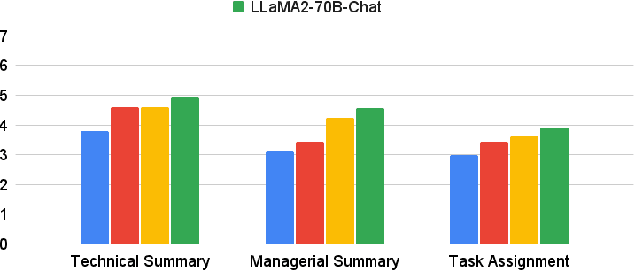
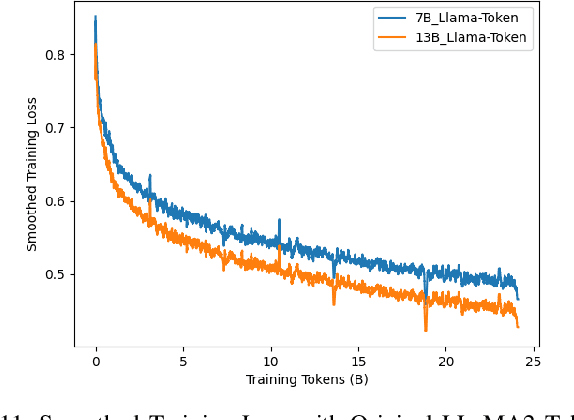
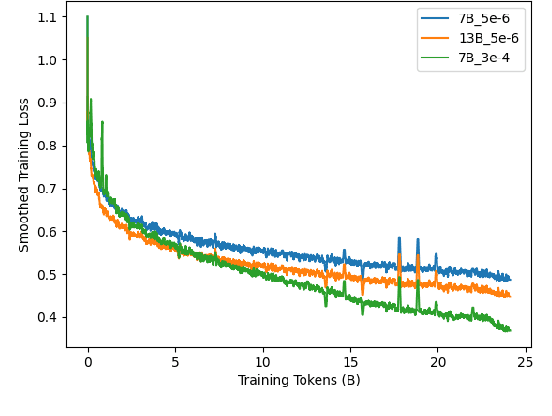
ChipNeMo aims to explore the applications of large language models (LLMs) for industrial chip design. Instead of directly deploying off-the-shelf commercial or open-source LLMs, we instead adopt the following domain adaptation techniques: custom tokenizers, domain-adaptive continued pretraining, supervised fine-tuning (SFT) with domain-specific instructions, and domain-adapted retrieval models. We evaluate these methods on three selected LLM applications for chip design: an engineering assistant chatbot, EDA script generation, and bug summarization and analysis. Our results show that these domain adaptation techniques enable significant LLM performance improvements over general-purpose base models across the three evaluated applications, enabling up to 5x model size reduction with similar or better performance on a range of design tasks. Our findings also indicate that there's still room for improvement between our current results and ideal outcomes. We believe that further investigation of domain-adapted LLM approaches will help close this gap in the future.
Low-Precision Training in Logarithmic Number System using Multiplicative Weight Update
Jun 26, 2021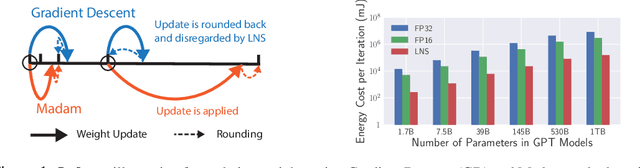
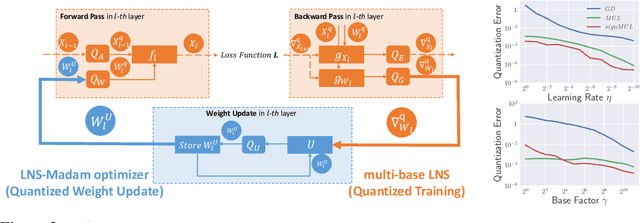
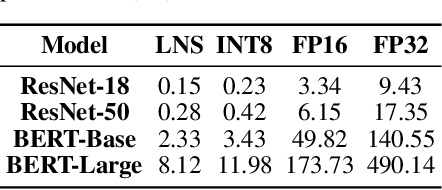
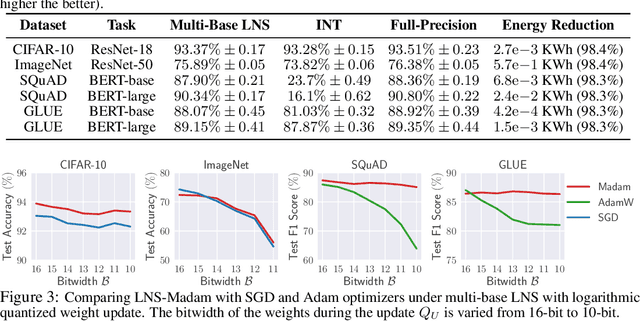
Training large-scale deep neural networks (DNNs) currently requires a significant amount of energy, leading to serious environmental impacts. One promising approach to reduce the energy costs is representing DNNs with low-precision numbers. While it is common to train DNNs with forward and backward propagation in low-precision, training directly over low-precision weights, without keeping a copy of weights in high-precision, still remains to be an unsolved problem. This is due to complex interactions between learning algorithms and low-precision number systems. To address this, we jointly design a low-precision training framework involving a logarithmic number system (LNS) and a multiplicative weight update training method, termed LNS-Madam. LNS has a high dynamic range even in a low-bitwidth setting, leading to high energy efficiency and making it relevant for on-board training in energy-constrained edge devices. We design LNS to have the flexibility of choosing different bases for weights and gradients, as they usually require different quantization gaps and dynamic ranges during training. By drawing the connection between LNS and multiplicative update, LNS-Madam ensures low quantization error during weight update, leading to a stable convergence even if the bitwidth is limited. Compared to using a fixed-point or floating-point number system and training with popular learning algorithms such as SGD and Adam, our joint design with LNS and LNS-Madam optimizer achieves better accuracy while requiring smaller bitwidth. Notably, with only 5-bit for gradients, the proposed training framework achieves accuracy comparable to full-precision state-of-the-art models such as ResNet-50 and BERT. After conducting energy estimations by analyzing the math datapath units during training, the results show that our design achieves over 60x energy reduction compared to FP32 on BERT models.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.