 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRPO with State Mutations: Improving LLM-Based Hardware Test Plan Generation
Jan 12, 2026RTL design often relies heavily on ad-hoc testbench creation early in the design cycle. While large language models (LLMs) show promise for RTL code generation, their ability to reason about hardware specifications and generate targeted test plans remains largely unexplored. We present the first systematic study of LLM reasoning capabilities for RTL verification stimuli generation, establishing a two-stage framework that decomposes test plan generation from testbench execution. Our benchmark reveals that state-of-the-art models, including DeepSeek-R1 and Claude-4.0-Sonnet, achieve only 15.7-21.7% success rates on generating stimuli that pass golden RTL designs. To improve LLM generated stimuli, we develop a comprehensive training methodology combining supervised fine-tuning with a novel reinforcement learning approach, GRPO with State Mutation (GRPO-SMu), which enhances exploration by varying input mutations. Our approach leverages a tree-based branching mutation strategy to construct training data comprising equivalent and mutated trees, moving beyond linear mutation approaches to provide rich learning signals. Training on this curated dataset, our 7B parameter model achieves a 33.3% golden test pass rate and a 13.9% mutation detection rate, representing a 17.6% absolute improvement over baseline and outperforming much larger general-purpose models. These results demonstrate that specialized training methodologies can significantly enhance LLM reasoning capabilities for hardware verification tasks, establishing a foundation for automated sub-unit testing in semiconductor design workflows.
Revisiting VerilogEval: Newer LLMs, In-Context Learning, and Specification-to-RTL Tasks
Aug 20, 2024The application of large-language models (LLMs) to digital hardware code generation is an emerging field. Most LLMs are primarily trained on natural language and software code. Hardware code, such as Verilog, represents only a small portion of the training data and few hardware benchmarks exist. To address this gap, the open-source VerilogEval benchmark was released in 2023, providing a consistent evaluation framework for LLMs on code completion tasks. It was tested on state-of-the-art models at the time including GPT-4. However, VerilogEval and other Verilog generation benchmarks lack failure analysis and, in present form, are not conducive to exploring prompting techniques. Also, since VerilogEval's release, both commercial and open-source models have seen continued development. In this work, we evaluate new commercial and open-source models of varying sizes against an improved VerilogEval benchmark suite. We enhance VerilogEval's infrastructure and dataset by automatically classifying failures, introduce new prompts for supporting in-context learning (ICL) examples, and extend the supported tasks to specification-to-RTL translation. We find a measurable improvement in commercial state-of-the-art models, with GPT-4 Turbo achieving a 59% pass rate on spec-to-RTL tasks. We also study the performance of open-source and domain-specific models that have emerged, and demonstrate that models can benefit substantially from ICL. We find that recently-released Llama 3.1 405B achieves a pass rate of 58%, effectively matching that of GPT-4 Turbo, and that the much smaller domain-specific RTL-Coder 6.7B models achieve an impressive 37% pass rate. However, prompt engineering is key to achieving good pass rates, and varies widely with model and task. A benchmark infrastructure that allows for prompt engineering and failure analysis is key to continued model development and deployment.
ChipNeMo: Domain-Adapted LLMs for Chip Design
Nov 13, 2023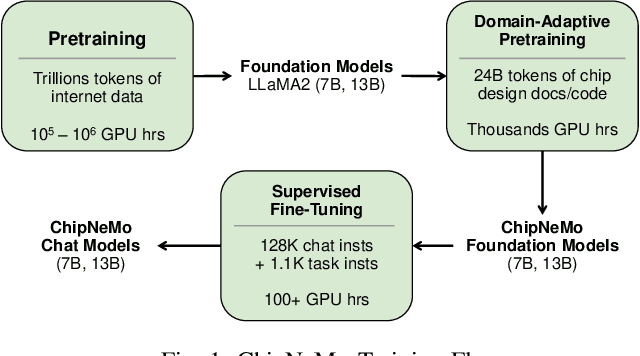
ChipNeMo aims to explore the applications of large language models (LLMs) for industrial chip design. Instead of directly deploying off-the-shelf commercial or open-source LLMs, we instead adopt the following domain adaptation techniques: custom tokenizers, domain-adaptive continued pretraining, supervised fine-tuning (SFT) with domain-specific instructions, and domain-adapted retrieval models. We evaluate these methods on three selected LLM applications for chip design: an engineering assistant chatbot, EDA script generation, and bug summarization and analysis. Our results show that these domain adaptation techniques enable significant LLM performance improvements over general-purpose base models across the three evaluated applications, enabling up to 5x model size reduction with similar or better performance on a range of design tasks. Our findings also indicate that there's still room for improvement between our current results and ideal outcomes. We believe that further investigation of domain-adapted LLM approaches will help close this gap in the future.
VerilogEval: Evaluating Large Language Models for Verilog Code Generation
Sep 14, 2023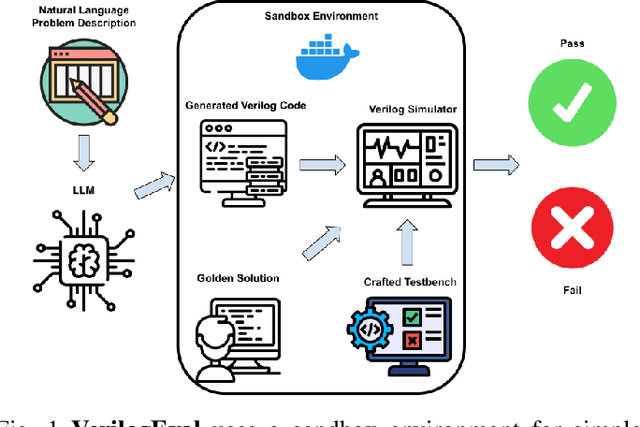



The increasing popularity of large language models (LLMs) has paved the way for their application in diverse domains. This paper proposes a benchmarking framework tailored specifically for evaluating LLM performance in the context of Verilog code generation for hardware design and verification. We present a comprehensive evaluation dataset consisting of 156 problems from the Verilog instructional website HDLBits. The evaluation set consists of a diverse set of Verilog code generation tasks, ranging from simple combinational circuits to complex finite state machines. The Verilog code completions can be automatically tested for functional correctness by comparing the transient simulation outputs of the generated design with a golden solution. We also demonstrate that the Verilog code generation capability of pretrained language models could be improved with supervised fine-tuning by bootstrapping with LLM generated synthetic problem-code pairs.