 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
JARVIS: A Multi-Agent Code Assistant for High-Quality EDA Script Generation
May 20, 2025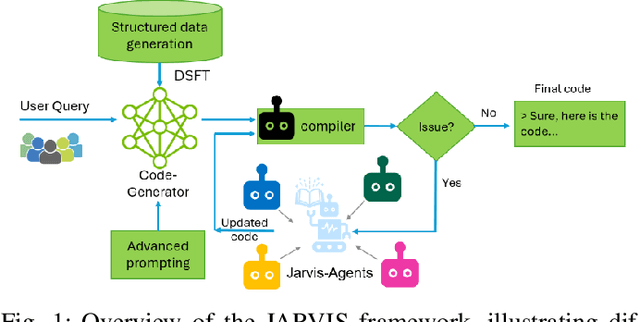
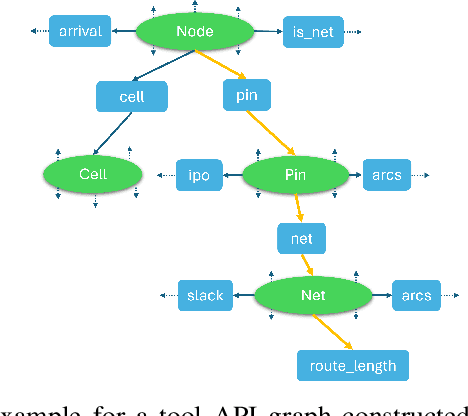
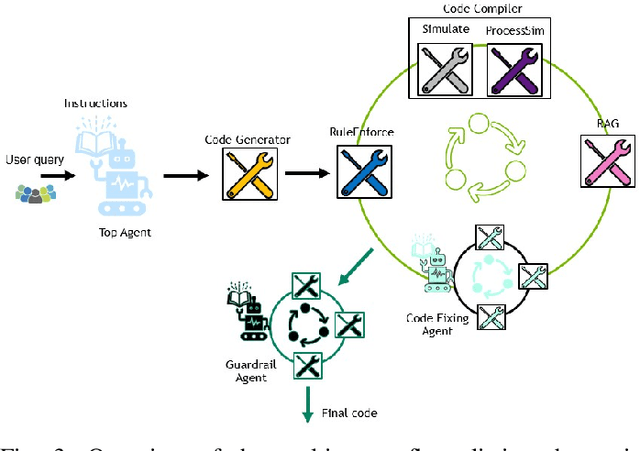
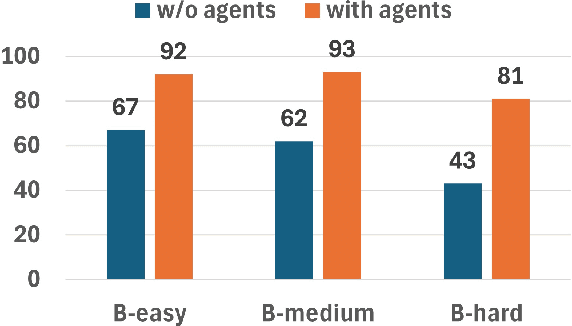
This paper presents JARVIS, a novel multi-agent framework that leverages Large Language Models (LLMs) and domain expertise to generate high-quality scripts for specialized Electronic Design Automation (EDA) tasks. By combining a domain-specific LLM trained with synthetically generated data, a custom compiler for structural verification, rule enforcement, code fixing capabilities, and advanced retrieval mechanisms, our approach achieves significant improvements over state-of-the-art domain-specific models. Our framework addresses the challenges of data scarcity and hallucination errors in LLMs, demonstrating the potential of LLMs in specialized engineering domains. We evaluate our framework on multiple benchmarks and show that it outperforms existing models in terms of accuracy and reliability. Our work sets a new precedent for the application of LLMs in EDA and paves the way for future innovations in this field.
Assessing Economic Viability: A Comparative Analysis of Total Cost of Ownership for Domain-Adapted Large Language Models versus State-of-the-art Counterparts in Chip Design Coding Assistance
Apr 12, 2024This paper presents a comparative analysis of total cost of ownership (TCO) and performance between domain-adapted large language models (LLM) and state-of-the-art (SoTA) LLMs , with a particular emphasis on tasks related to coding assistance for chip design. We examine the TCO and performance metrics of a domain-adaptive LLM, ChipNeMo, against two leading LLMs, Claude 3 Opus and ChatGPT-4 Turbo, to assess their efficacy in chip design coding generation. Through a detailed evaluation of the accuracy of the model, training methodologies, and operational expenditures, this study aims to provide stakeholders with critical information to select the most economically viable and performance-efficient solutions for their specific needs. Our results underscore the benefits of employing domain-adapted models, such as ChipNeMo, that demonstrate improved performance at significantly reduced costs compared to their general-purpose counterparts. In particular, we reveal the potential of domain-adapted LLMs to decrease TCO by approximately 90%-95%, with the cost advantages becoming increasingly evident as the deployment scale expands. With expansion of deployment, the cost benefits of ChipNeMo become more pronounced, making domain-adaptive LLMs an attractive option for organizations with substantial coding needs supported by LLMs
ChipNeMo: Domain-Adapted LLMs for Chip Design
Nov 13, 2023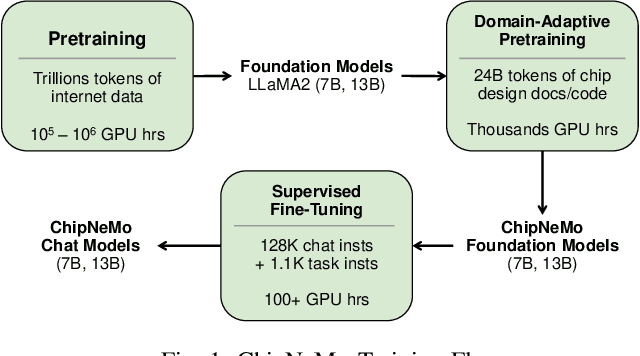
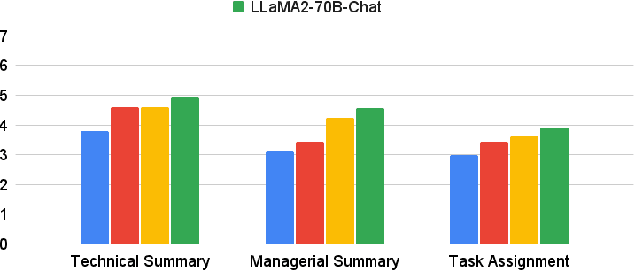
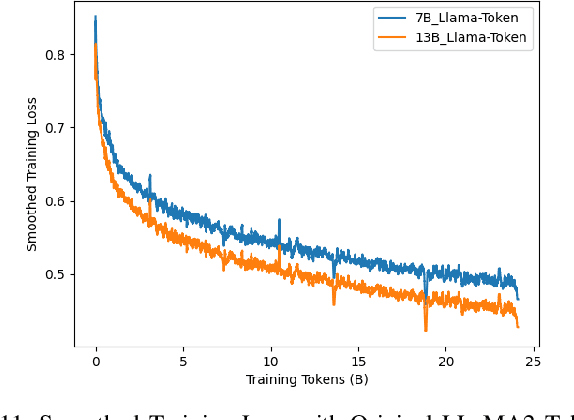
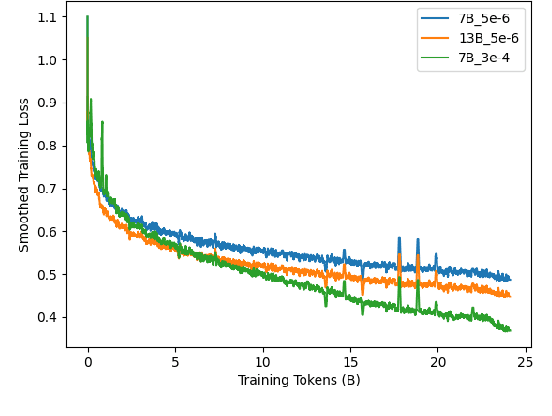
ChipNeMo aims to explore the applications of large language models (LLMs) for industrial chip design. Instead of directly deploying off-the-shelf commercial or open-source LLMs, we instead adopt the following domain adaptation techniques: custom tokenizers, domain-adaptive continued pretraining, supervised fine-tuning (SFT) with domain-specific instructions, and domain-adapted retrieval models. We evaluate these methods on three selected LLM applications for chip design: an engineering assistant chatbot, EDA script generation, and bug summarization and analysis. Our results show that these domain adaptation techniques enable significant LLM performance improvements over general-purpose base models across the three evaluated applications, enabling up to 5x model size reduction with similar or better performance on a range of design tasks. Our findings also indicate that there's still room for improvement between our current results and ideal outcomes. We believe that further investigation of domain-adapted LLM approaches will help close this gap in the future.