 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJARVIS: A Multi-Agent Code Assistant for High-Quality EDA Script Generation
May 20, 2025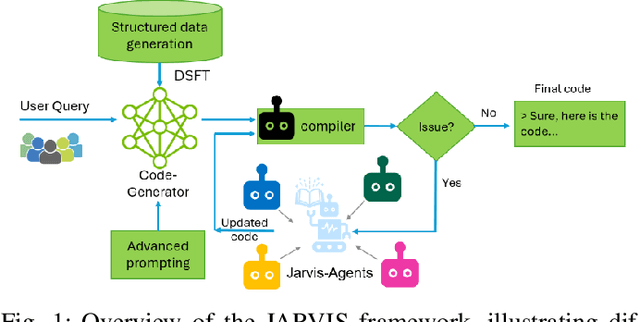
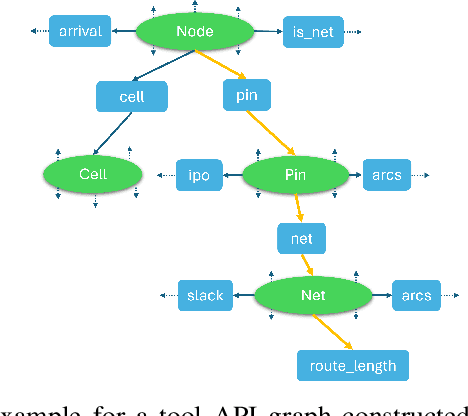
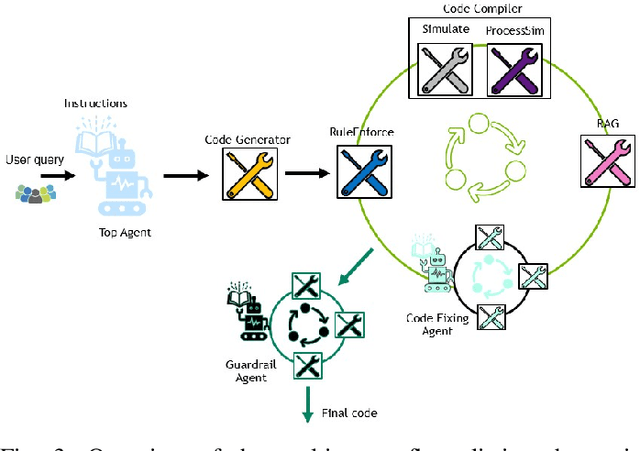
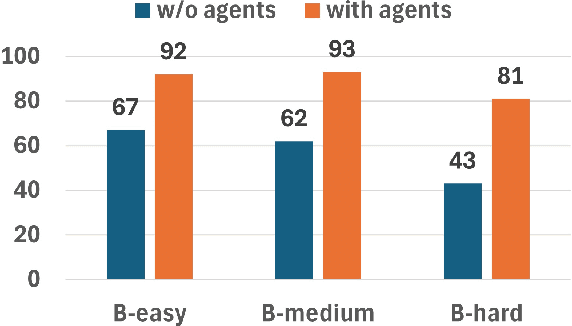
This paper presents JARVIS, a novel multi-agent framework that leverages Large Language Models (LLMs) and domain expertise to generate high-quality scripts for specialized Electronic Design Automation (EDA) tasks. By combining a domain-specific LLM trained with synthetically generated data, a custom compiler for structural verification, rule enforcement, code fixing capabilities, and advanced retrieval mechanisms, our approach achieves significant improvements over state-of-the-art domain-specific models. Our framework addresses the challenges of data scarcity and hallucination errors in LLMs, demonstrating the potential of LLMs in specialized engineering domains. We evaluate our framework on multiple benchmarks and show that it outperforms existing models in terms of accuracy and reliability. Our work sets a new precedent for the application of LLMs in EDA and paves the way for future innovations in this field.
Assessing Economic Viability: A Comparative Analysis of Total Cost of Ownership for Domain-Adapted Large Language Models versus State-of-the-art Counterparts in Chip Design Coding Assistance
Apr 12, 2024This paper presents a comparative analysis of total cost of ownership (TCO) and performance between domain-adapted large language models (LLM) and state-of-the-art (SoTA) LLMs , with a particular emphasis on tasks related to coding assistance for chip design. We examine the TCO and performance metrics of a domain-adaptive LLM, ChipNeMo, against two leading LLMs, Claude 3 Opus and ChatGPT-4 Turbo, to assess their efficacy in chip design coding generation. Through a detailed evaluation of the accuracy of the model, training methodologies, and operational expenditures, this study aims to provide stakeholders with critical information to select the most economically viable and performance-efficient solutions for their specific needs. Our results underscore the benefits of employing domain-adapted models, such as ChipNeMo, that demonstrate improved performance at significantly reduced costs compared to their general-purpose counterparts. In particular, we reveal the potential of domain-adapted LLMs to decrease TCO by approximately 90%-95%, with the cost advantages becoming increasingly evident as the deployment scale expands. With expansion of deployment, the cost benefits of ChipNeMo become more pronounced, making domain-adaptive LLMs an attractive option for organizations with substantial coding needs supported by LLMs
ChipNeMo: Domain-Adapted LLMs for Chip Design
Nov 13, 2023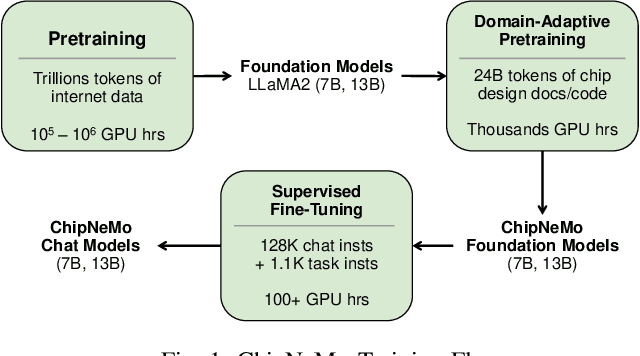
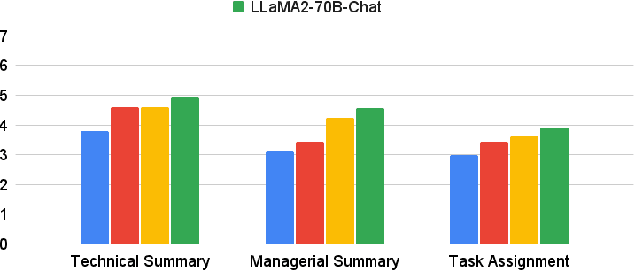
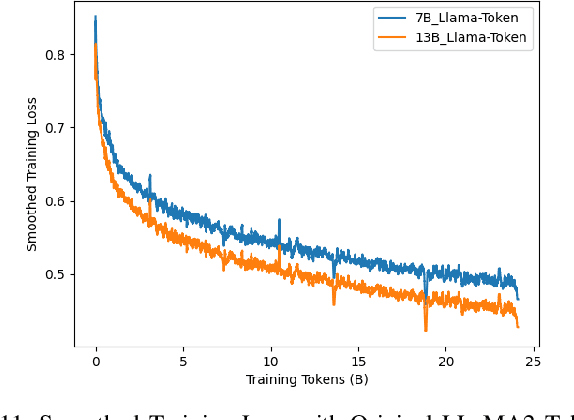
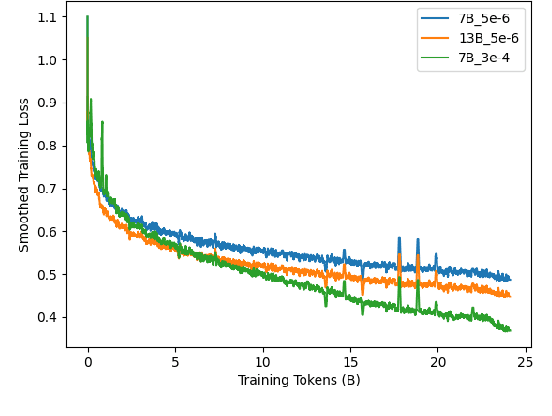
ChipNeMo aims to explore the applications of large language models (LLMs) for industrial chip design. Instead of directly deploying off-the-shelf commercial or open-source LLMs, we instead adopt the following domain adaptation techniques: custom tokenizers, domain-adaptive continued pretraining, supervised fine-tuning (SFT) with domain-specific instructions, and domain-adapted retrieval models. We evaluate these methods on three selected LLM applications for chip design: an engineering assistant chatbot, EDA script generation, and bug summarization and analysis. Our results show that these domain adaptation techniques enable significant LLM performance improvements over general-purpose base models across the three evaluated applications, enabling up to 5x model size reduction with similar or better performance on a range of design tasks. Our findings also indicate that there's still room for improvement between our current results and ideal outcomes. We believe that further investigation of domain-adapted LLM approaches will help close this gap in the future.
GNNIE: GNN Inference Engine with Load-balancing and Graph-Specific Caching
May 21, 2021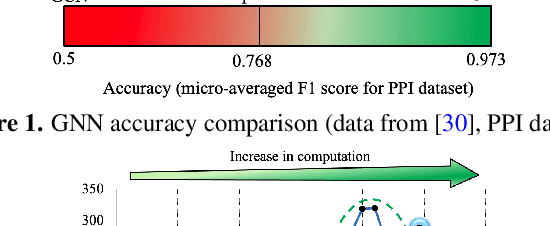

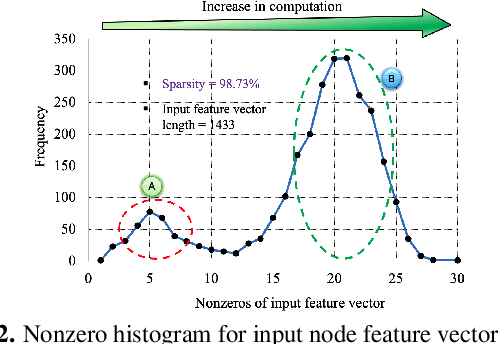
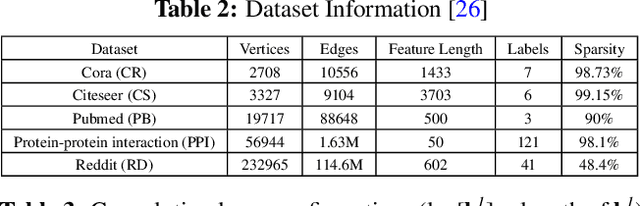
Analysis engines based on Graph Neural Networks (GNNs) are vital for many real-world problems that model relationships using large graphs. Challenges for a GNN hardware platform include the ability to (a) host a variety of GNNs, (b) handle high sparsity in input node feature vectors and the graph adjacency matrix and the accompanying random memory access patterns, and (c) maintain load-balanced computation in the face of uneven workloads induced by high sparsity and power-law vertex degree distributions in real datasets. The proposes GNNIE, an accelerator designed to run a broad range of GNNs. It tackles workload imbalance by (i) splitting node feature operands into blocks, (ii) reordering and redistributing computations, and (iii) using a flexible MAC architecture with low communication overheads among the processing elements. In addition, it adopts a graph partitioning scheme and a graph-specific caching policy that efficiently uses off-chip memory bandwidth that is well suited to the characteristics of real-world graphs. Random memory access effects are mitigated by partitioning and degree-aware caching to enable the reuse of high-degree vertices. GNNIE achieves average speedups of over 8890x over a CPU and 295x over a GPU over multiple datasets on graph attention networks (GATs), graph convolutional networks (GCNs), GraphSAGE, GINConv, and DiffPool, Compared to prior approaches, GNNIE achieves an average speedup of 9.74x over HyGCN for GCN, GraphSAGE, and GINConv; HyGCN cannot implement GATs. GNNIE achieves an average speedup of 2.28x over AWB-GCN (which runs only GCNs), despite using 3.4x fewer processing units.
A general approach for identifying hierarchical symmetry constraints for analog circuit layout
Sep 30, 2020
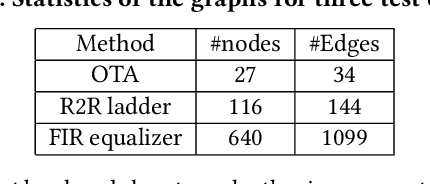

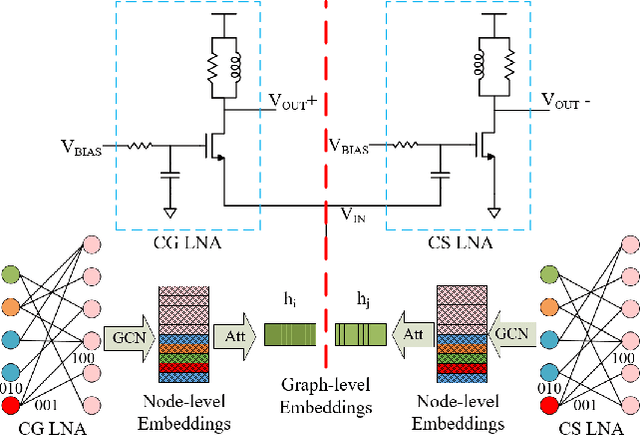
Analog layout synthesis requires some elements in the circuit netlist to be matched and placed symmetrically. However, the set of symmetries is very circuit-specific and a versatile algorithm, applicable to a broad variety of circuits, has been elusive. This paper presents a general methodology for the automated generation of symmetry constraints, and applies these constraints to guide automated layout synthesis. While prior approaches were restricted to identifying simple symmetries, the proposed method operates hierarchically and uses graph-based algorithms to extract multiple axes of symmetry within a circuit. An important ingredient of the algorithm is its ability to identify arrays of repeated structures. In some circuits, the repeated structures are not perfect replicas and can only be found through approximate graph matching. A fast graph neural network based methodology is developed for this purpose, based on evaluating the graph edit distance. The utility of this algorithm is demonstrated on a variety of circuits, including operational amplifiers, data converters, equalizers, and low-noise amplifiers.