 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing the Auditors: Does Community-based Moderation Get It Right?
Mar 17, 2026Online social platforms increasingly rely on crowd-sourced systems to label misleading content at scale, but these systems must both aggregate users' evaluations and decide whose evaluations to trust. To address the latter, many platforms audit users by rewarding agreement with the final aggregate outcome, a design we term consensus-based auditing. We analyze the consequences of this design in X's Community Notes, which in September 2022 adopted consensus-based auditing that ties users' eligibility for participation to agreement with the eventual platform outcome. We find evidence of strategic conformity: minority contributors' evaluations drift toward the majority and their participation share falls on controversial topics, where independent signals matter most. We formalize this mechanism in a behavioral model in which contributors trade off private beliefs against anticipated penalties for disagreement. Motivated by these findings, we propose a two-stage auditing and aggregation algorithm that weights contributors by the stability of their past residuals rather than by agreement with the majority. The method first accounts for differences across content and contributors, and then measures how predictable each contributor's evaluations are relative to the latent-factor model. Contributors whose evaluations are consistently informative receive greater influence in aggregation, even when they disagree with the prevailing consensus. In the Community Notes data, this approach improves out-of-sample predictive performance while avoiding penalization of disagreement.
Manifold-Constrained Nucleus-Level Denoising Diffusion Model for Structure-Based Drug Design
Sep 16, 2024Artificial intelligence models have shown great potential in structure-based drug design, generating ligands with high binding affinities. However, existing models have often overlooked a crucial physical constraint: atoms must maintain a minimum pairwise distance to avoid separation violation, a phenomenon governed by the balance of attractive and repulsive forces. To mitigate such separation violations, we propose NucleusDiff. It models the interactions between atomic nuclei and their surrounding electron clouds by enforcing the distance constraint between the nuclei and manifolds. We quantitatively evaluate NucleusDiff using the CrossDocked2020 dataset and a COVID-19 therapeutic target, demonstrating that NucleusDiff reduces violation rate by up to 100.00% and enhances binding affinity by up to 22.16%, surpassing state-of-the-art models for structure-based drug design. We also provide qualitative analysis through manifold sampling, visually confirming the effectiveness of NucleusDiff in reducing separation violations and improving binding affinities.
A Multi-Grained Symmetric Differential Equation Model for Learning Protein-Ligand Binding Dynamics
Feb 01, 2024In drug discovery, molecular dynamics (MD) simulation for protein-ligand binding provides a powerful tool for predicting binding affinities, estimating transport properties, and exploring pocket sites. There has been a long history of improving the efficiency of MD simulations through better numerical methods and, more recently, by utilizing machine learning (ML) methods. Yet, challenges remain, such as accurate modeling of extended-timescale simulations. To address this issue, we propose NeuralMD, the first ML surrogate that can facilitate numerical MD and provide accurate simulations in protein-ligand binding. We propose a principled approach that incorporates a novel physics-informed multi-grained group symmetric framework. Specifically, we propose (1) a BindingNet model that satisfies group symmetry using vector frames and captures the multi-level protein-ligand interactions, and (2) an augmented neural differential equation solver that learns the trajectory under Newtonian mechanics. For the experiment, we design ten single-trajectory and three multi-trajectory binding simulation tasks. We show the efficiency and effectiveness of NeuralMD, with a 2000$\times$ speedup over standard numerical MD simulation and outperforming all other ML approaches by up to 80% under the stability metric. We further qualitatively show that NeuralMD reaches more stable binding predictions compared to other machine learning methods.
Symmetry-Informed Geometric Representation for Molecules, Proteins, and Crystalline Materials
Jun 15, 2023



Artificial intelligence for scientific discovery has recently generated significant interest within the machine learning and scientific communities, particularly in the domains of chemistry, biology, and material discovery. For these scientific problems, molecules serve as the fundamental building blocks, and machine learning has emerged as a highly effective and powerful tool for modeling their geometric structures. Nevertheless, due to the rapidly evolving process of the field and the knowledge gap between science (e.g., physics, chemistry, & biology) and machine learning communities, a benchmarking study on geometrical representation for such data has not been conducted. To address such an issue, in this paper, we first provide a unified view of the current symmetry-informed geometric methods, classifying them into three main categories: invariance, equivariance with spherical frame basis, and equivariance with vector frame basis. Then we propose a platform, coined Geom3D, which enables benchmarking the effectiveness of geometric strategies. Geom3D contains 16 advanced symmetry-informed geometric representation models and 14 geometric pretraining methods over 46 diverse datasets, including small molecules, proteins, and crystalline materials. We hope that Geom3D can, on the one hand, eliminate barriers for machine learning researchers interested in exploring scientific problems; and, on the other hand, provide valuable guidance for researchers in computational chemistry, structural biology, and materials science, aiding in the informed selection of representation techniques for specific applications.
Disincentivizing Polarization in Social Networks
May 23, 2023



On social networks, algorithmic personalization drives users into filter bubbles where they rarely see content that deviates from their interests. We present a model for content curation and personalization that avoids filter bubbles, along with algorithmic guarantees and nearly matching lower bounds. In our model, the platform interacts with $n$ users over $T$ timesteps, choosing content for each user from $k$ categories. The platform receives stochastic rewards as in a multi-arm bandit. To avoid filter bubbles, we draw on the intuition that if some users are shown some category of content, then all users should see at least a small amount of that content. We first analyze a naive formalization of this intuition and show it has unintended consequences: it leads to ``tyranny of the majority'' with the burden of diversification borne disproportionately by those with minority interests. This leads us to our model which distributes this burden more equitably. We require that the probability any user is shown a particular type of content is at least $\gamma$ times the average probability all users are shown that type of content. Full personalization corresponds to $\gamma = 0$ and complete homogenization corresponds to $\gamma = 1$; hence, $\gamma$ encodes a hard cap on the level of personalization. We also analyze additional formulations where the platform can exceed its cap but pays a penalty proportional to its constraint violation. We provide algorithmic guarantees for optimizing recommendations subject to these constraints. These include nearly matching upper and lower bounds for the entire range of $\gamma \in [0,1]$ showing that the reward of a multi-agent variant of UCB is nearly optimal. Using real-world preference data, we empirically verify that under our model, users share the burden of diversification with only minor utility loss under our constraints.
Tackling Climate Change with Machine Learning
Jun 10, 2019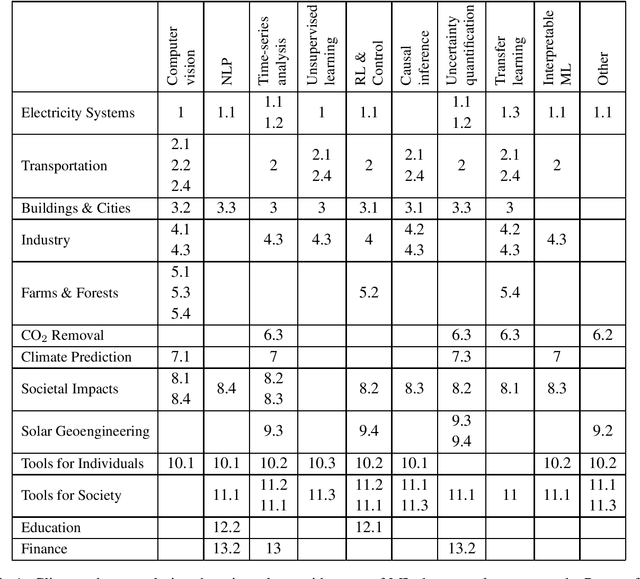
Climate change is one of the greatest challenges facing humanity, and we, as machine learning experts, may wonder how we can help. Here we describe how machine learning can be a powerful tool in reducing greenhouse gas emissions and helping society adapt to a changing climate. From smart grids to disaster management, we identify high impact problems where existing gaps can be filled by machine learning, in collaboration with other fields. Our recommendations encompass exciting research questions as well as promising business opportunities. We call on the machine learning community to join the global effort against climate change.
Visualizing the Consequences of Climate Change Using Cycle-Consistent Adversarial Networks
May 02, 2019

We present a project that aims to generate images that depict accurate, vivid, and personalized outcomes of climate change using Cycle-Consistent Adversarial Networks (CycleGANs). By training our CycleGAN model on street-view images of houses before and after extreme weather events (e.g. floods, forest fires, etc.), we learn a mapping that can then be applied to images of locations that have not yet experienced these events. This visual transformation is paired with climate model predictions to assess likelihood and type of climate-related events in the long term (50 years) in order to bring the future closer in the viewers mind. The eventual goal of our project is to enable individuals to make more informed choices about their climate future by creating a more visceral understanding of the effects of climate change, while maintaining scientific credibility by drawing on climate model projections.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
What's in a Name? Reducing Bias in Bios without Access to Protected Attributes
Apr 10, 2019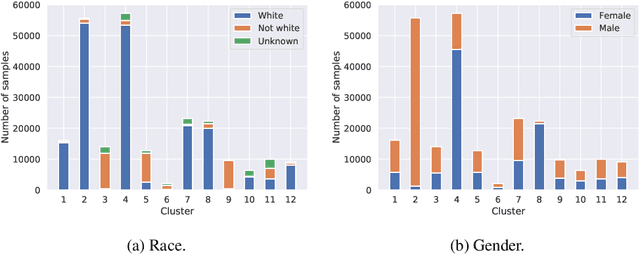
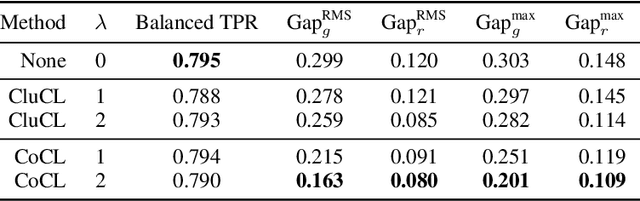
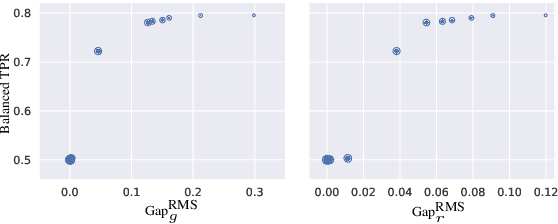
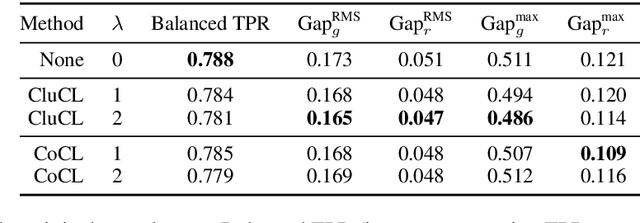
There is a growing body of work that proposes methods for mitigating bias in machine learning systems. These methods typically rely on access to protected attributes such as race, gender, or age. However, this raises two significant challenges: (1) protected attributes may not be available or it may not be legal to use them, and (2) it is often desirable to simultaneously consider multiple protected attributes, as well as their intersections. In the context of mitigating bias in occupation classification, we propose a method for discouraging correlation between the predicted probability of an individual's true occupation and a word embedding of their name. This method leverages the societal biases that are encoded in word embeddings, eliminating the need for access to protected attributes. Crucially, it only requires access to individuals' names at training time and not at deployment time. We evaluate two variations of our proposed method using a large-scale dataset of online biographies. We find that both variations simultaneously reduce race and gender biases, with almost no reduction in the classifier's overall true positive rate.
Bias in Bios: A Case Study of Semantic Representation Bias in a High-Stakes Setting
Jan 27, 2019
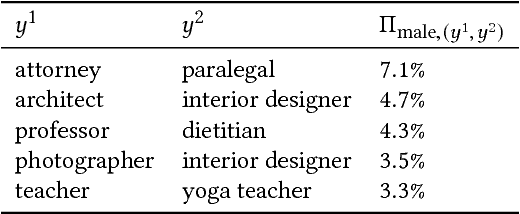
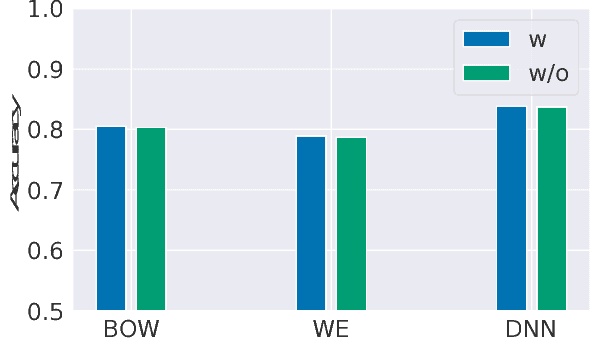

We present a large-scale study of gender bias in occupation classification, a task where the use of machine learning may lead to negative outcomes on peoples' lives. We analyze the potential allocation harms that can result from semantic representation bias. To do so, we study the impact on occupation classification of including explicit gender indicators---such as first names and pronouns---in different semantic representations of online biographies. Additionally, we quantify the bias that remains when these indicators are "scrubbed," and describe proxy behavior that occurs in the absence of explicit gender indicators. As we demonstrate, differences in true positive rates between genders are correlated with existing gender imbalances in occupations, which may compound these imbalances.