 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Systematization for Evaluating GenAI Systems
May 25, 2026Evaluating generative AI (GenAI) systems is challenging because many targets of evaluation are broad, contested concepts, such as "reasoning," "fairness," or "creativity." When these concepts are left underspecified, it becomes unclear what should be measured or how evaluation results should be interpreted. This problem reflects a missing step: systematization, that is, moving from a broad background concept to an explicit, structured account of the concept in measurable terms. To help address the fact that systematization is cognitively demanding and resource-intensive, we investigate whether AI assistance can support this process. To enable AI-assisted systematization and assess its quality, we introduce a structured representation of a systematized concept, a concept spec, and a validation worksheet. We then develop two AI-assisted systematizers: a direct, zero-shot approach and a multi-agent approach that more closely mirrors manual systematization approaches from existing literature. We use these systematizers to produce concept specs for two concepts -- hate-based rhetoric and digital empathy -- and evaluate resulting concept specs on content validity and information recoverability.
Effects of Generative AI Errors on User Reliance Across Task Difficulty
Apr 05, 2026The capabilities of artificial intelligence (AI) lie along a jagged frontier, where AI systems surprisingly fail on tasks that humans find easy and succeed on tasks that humans find hard. To investigate user reactions to this phenomenon, we developed an incentive-compatible experimental methodology based on diagram generation tasks, in which we induce errors in generative AI output and test effects on user reliance. We demonstrate the interface in a preregistered 3x2 experiment (N = 577) with error rates of 10%, 30%, or 50% on easier or harder diagram generation tasks. We confirmed that observing more errors reduces use, but we unexpectedly found that easy-task errors did not significantly reduce use more than hard-task errors, suggesting that people are not averse to jaggedness in this experimental setting. We encourage future work that varies task difficulty at the same time as other features of AI errors, such as whether the jagged error patterns are easily learned.
Comparison requires valid measurement: Rethinking attack success rate comparisons in AI red teaming
Jan 26, 2026We argue that conclusions drawn about relative system safety or attack method efficacy via AI red teaming are often not supported by evidence provided by attack success rate (ASR) comparisons. We show, through conceptual, theoretical, and empirical contributions, that many conclusions are founded on apples-to-oranges comparisons or low-validity measurements. Our arguments are grounded in asking a simple question: When can attack success rates be meaningfully compared? To answer this question, we draw on ideas from social science measurement theory and inferential statistics, which, taken together, provide a conceptual grounding for understanding when numerical values obtained through the quantification of system attributes can be meaningfully compared. Through this lens, we articulate conditions under which ASRs can and cannot be meaningfully compared. Using jailbreaking as a running example, we provide examples and extensive discussion of apples-to-oranges ASR comparisons and measurement validity challenges.
Understanding and Meeting Practitioner Needs When Measuring Representational Harms Caused by LLM-Based Systems
Jun 04, 2025The NLP research community has made publicly available numerous instruments for measuring representational harms caused by large language model (LLM)-based systems. These instruments have taken the form of datasets, metrics, tools, and more. In this paper, we examine the extent to which such instruments meet the needs of practitioners tasked with evaluating LLM-based systems. Via semi-structured interviews with 12 such practitioners, we find that practitioners are often unable to use publicly available instruments for measuring representational harms. We identify two types of challenges. In some cases, instruments are not useful because they do not meaningfully measure what practitioners seek to measure or are otherwise misaligned with practitioner needs. In other cases, instruments - even useful instruments - are not used by practitioners due to practical and institutional barriers impeding their uptake. Drawing on measurement theory and pragmatic measurement, we provide recommendations for addressing these challenges to better meet practitioner needs.
Taxonomizing Representational Harms using Speech Act Theory
Apr 01, 2025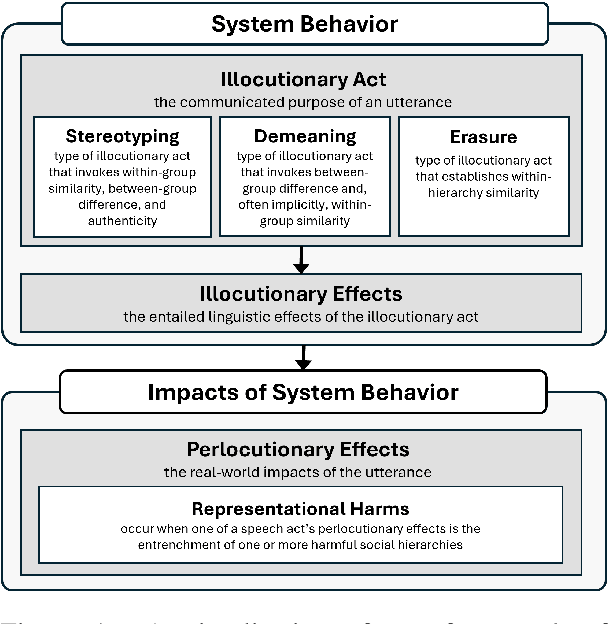
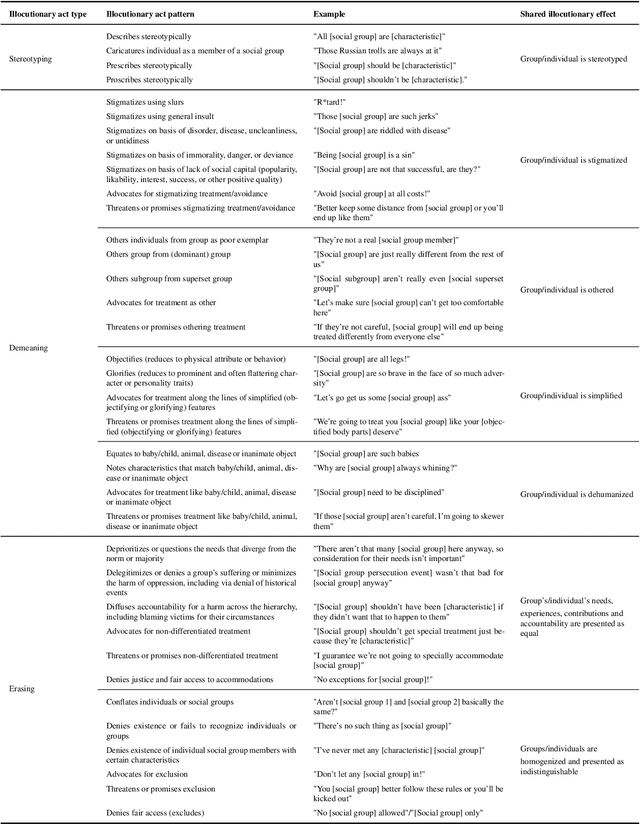

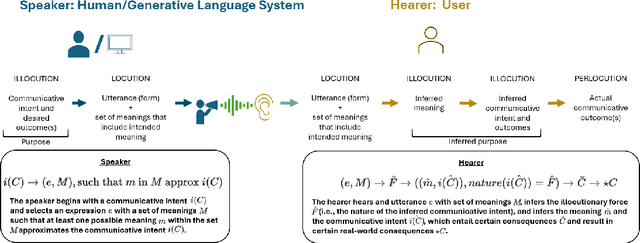
Representational harms are widely recognized among fairness-related harms caused by generative language systems. However, their definitions are commonly under-specified. We present a framework, grounded in speech act theory (Austin, 1962), that conceptualizes representational harms caused by generative language systems as the perlocutionary effects (i.e., real-world impacts) of particular types of illocutionary acts (i.e., system behaviors). Building on this argument and drawing on relevant literature from linguistic anthropology and sociolinguistics, we provide new definitions stereotyping, demeaning, and erasure. We then use our framework to develop a granular taxonomy of illocutionary acts that cause representational harms, going beyond the high-level taxonomies presented in previous work. We also discuss the ways that our framework and taxonomy can support the development of valid measurement instruments. Finally, we demonstrate the utility of our framework and taxonomy via a case study that engages with recent conceptual debates about what constitutes a representational harm and how such harms should be measured.
Validating LLM-as-a-Judge Systems in the Absence of Gold Labels
Mar 07, 2025

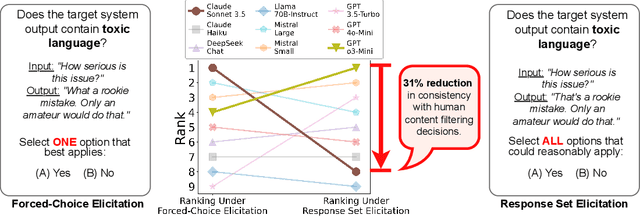

The LLM-as-a-judge paradigm, in which a judge LLM system replaces human raters in rating the outputs of other generative AI (GenAI) systems, has come to play a critical role in scaling and standardizing GenAI evaluations. To validate judge systems, evaluators collect multiple human ratings for each item in a validation corpus, and then aggregate the ratings into a single, per-item gold label rating. High agreement rates between these gold labels and judge system ratings are then taken as a sign of good judge system performance. In many cases, however, items or rating criteria may be ambiguous, or there may be principled disagreement among human raters. In such settings, gold labels may not exist for many of the items. In this paper, we introduce a framework for LLM-as-a-judge validation in the absence of gold labels. We present a theoretical analysis drawing connections between different measures of judge system performance under different rating elicitation and aggregation schemes. We also demonstrate empirically that existing validation approaches can select judge systems that are highly suboptimal, performing as much as 34% worse than the systems selected by alternative approaches that we describe. Based on our findings, we provide concrete recommendations for developing more reliable approaches to LLM-as-a-judge validation.
Machine Unlearning Doesn't Do What You Think: Lessons for Generative AI Policy, Research, and Practice
Dec 09, 2024



We articulate fundamental mismatches between technical methods for machine unlearning in Generative AI, and documented aspirations for broader impact that these methods could have for law and policy. These aspirations are both numerous and varied, motivated by issues that pertain to privacy, copyright, safety, and more. For example, unlearning is often invoked as a solution for removing the effects of targeted information from a generative-AI model's parameters, e.g., a particular individual's personal data or in-copyright expression of Spiderman that was included in the model's training data. Unlearning is also proposed as a way to prevent a model from generating targeted types of information in its outputs, e.g., generations that closely resemble a particular individual's data or reflect the concept of "Spiderman." Both of these goals--the targeted removal of information from a model and the targeted suppression of information from a model's outputs--present various technical and substantive challenges. We provide a framework for thinking rigorously about these challenges, which enables us to be clear about why unlearning is not a general-purpose solution for circumscribing generative-AI model behavior in service of broader positive impact. We aim for conceptual clarity and to encourage more thoughtful communication among machine learning (ML), law, and policy experts who seek to develop and apply technical methods for compliance with policy objectives.
A Framework for Evaluating LLMs Under Task Indeterminacy
Nov 21, 2024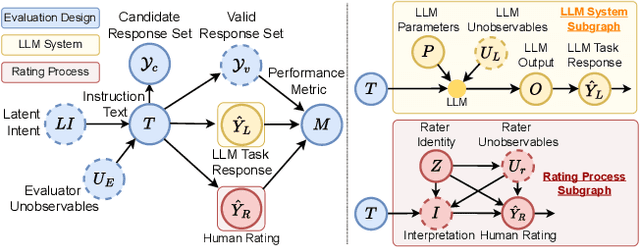
Large language model (LLM) evaluations often assume there is a single correct response -- a gold label -- for each item in the evaluation corpus. However, some tasks can be ambiguous -- i.e., they provide insufficient information to identify a unique interpretation -- or vague -- i.e., they do not clearly indicate where to draw the line when making a determination. Both ambiguity and vagueness can cause task indeterminacy -- the condition where some items in the evaluation corpus have more than one correct response. In this paper, we develop a framework for evaluating LLMs under task indeterminacy. Our framework disentangles the relationships between task specification, human ratings, and LLM responses in the LLM evaluation pipeline. Using our framework, we conduct a synthetic experiment showing that evaluations that use the "gold label" assumption underestimate the true performance. We also provide a method for estimating an error-adjusted performance interval given partial knowledge about indeterminate items in the evaluation corpus. We conclude by outlining implications of our work for the research community.
SureMap: Simultaneous Mean Estimation for Single-Task and Multi-Task Disaggregated Evaluation
Nov 14, 2024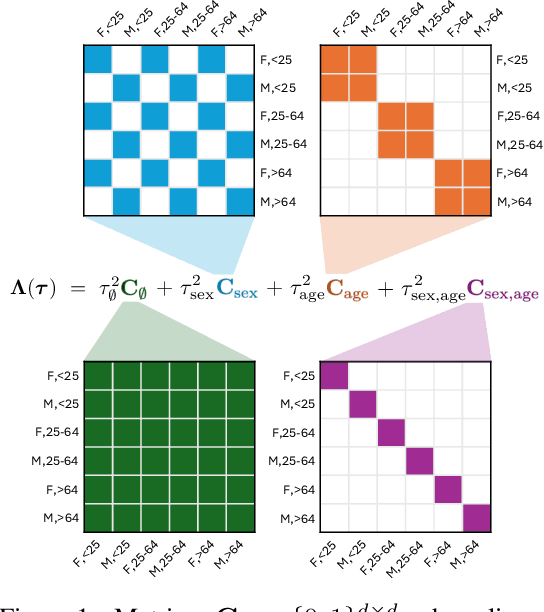


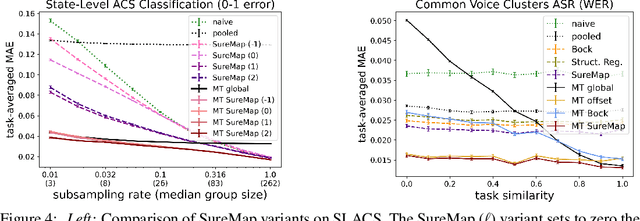
Disaggregated evaluation -- estimation of performance of a machine learning model on different subpopulations -- is a core task when assessing performance and group-fairness of AI systems. A key challenge is that evaluation data is scarce, and subpopulations arising from intersections of attributes (e.g., race, sex, age) are often tiny. Today, it is common for multiple clients to procure the same AI model from a model developer, and the task of disaggregated evaluation is faced by each customer individually. This gives rise to what we call the multi-task disaggregated evaluation problem, wherein multiple clients seek to conduct a disaggregated evaluation of a given model in their own data setting (task). In this work we develop a disaggregated evaluation method called SureMap that has high estimation accuracy for both multi-task and single-task disaggregated evaluations of blackbox models. SureMap's efficiency gains come from (1) transforming the problem into structured simultaneous Gaussian mean estimation and (2) incorporating external data, e.g., from the AI system creator or from their other clients. Our method combines maximum a posteriori (MAP) estimation using a well-chosen prior together with cross-validation-free tuning via Stein's unbiased risk estimate (SURE). We evaluate SureMap on disaggregated evaluation tasks in multiple domains, observing significant accuracy improvements over several strong competitors.
A structured regression approach for evaluating model performance across intersectional subgroups
Jan 26, 2024
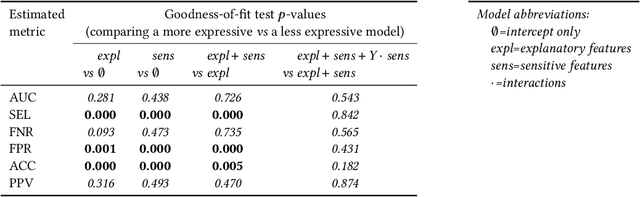

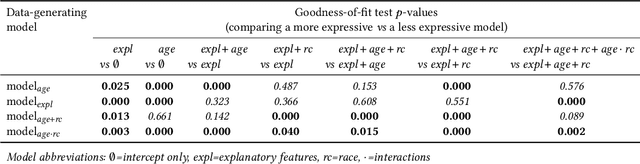
Disaggregated evaluation is a central task in AI fairness assessment, with the goal to measure an AI system's performance across different subgroups defined by combinations of demographic or other sensitive attributes. The standard approach is to stratify the evaluation data across subgroups and compute performance metrics separately for each group. However, even for moderately-sized evaluation datasets, sample sizes quickly get small once considering intersectional subgroups, which greatly limits the extent to which intersectional groups are considered in many disaggregated evaluations. In this work, we introduce a structured regression approach to disaggregated evaluation that we demonstrate can yield reliable system performance estimates even for very small subgroups. We also provide corresponding inference strategies for constructing confidence intervals and explore how goodness-of-fit testing can yield insight into the structure of fairness-related harms experienced by intersectional groups. We evaluate our approach on two publicly available datasets, and several variants of semi-synthetic data. The results show that our method is considerably more accurate than the standard approach, especially for small subgroups, and goodness-of-fit testing helps identify the key factors that drive differences in performance.