 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrade-offs in Ensembling, Merging and Routing Among Parameter-Efficient Experts
Mar 03, 2026While large language models (LLMs) fine-tuned with lightweight adapters achieve strong performance across diverse tasks, their performance on individual tasks depends on the fine-tuning strategy. Fusing independently trained models with different strengths has shown promise for multi-task learning through three main strategies: ensembling, which combines outputs from independent models; merging, which fuses model weights via parameter averaging; and routing, which integrates models in an input-dependent fashion. However, many design decisions in these approaches remain understudied, and the relative benefits of more sophisticated ensembling, merging and routing techniques are not fully understood. We empirically evaluate their trade-offs, addressing two key questions: What are the advantages of going beyond uniform ensembling or merging? And does the flexibility of routing justify its complexity? Our findings indicate that non-uniform ensembling and merging improve performance, but routing offers even greater gains. To mitigate the computational cost of routing, we analyze expert selection techniques, showing that clustering and greedy subset selection can maintain reasonable performance with minimal overhead. These insights advance our understanding of model fusion for multi-task learning.
On the Hardness of Bandit Learning
Jun 17, 2025
We study the task of bandit learning, also known as best-arm identification, under the assumption that the true reward function f belongs to a known, but arbitrary, function class F. We seek a general theory of bandit learnability, akin to the PAC framework for classification. Our investigation is guided by the following two questions: (1) which classes F are learnable, and (2) how they are learnable. For example, in the case of binary PAC classification, learnability is fully determined by a combinatorial dimension - the VC dimension- and can be attained via a simple algorithmic principle, namely, empirical risk minimization (ERM). In contrast to classical learning-theoretic results, our findings reveal limitations of learning in structured bandits, offering insights into the boundaries of bandit learnability. First, for the question of "which", we show that the paradigm of identifying the learnable classes via a dimension-like quantity fails for bandit learning. We give a simple proof demonstrating that no combinatorial dimension can characterize bandit learnability, even in finite classes, following a standard definition of dimension introduced by Ben-David et al. (2019). For the question of "how", we prove a computational hardness result: we construct a reward function class for which at most two queries are needed to find the optimal action, yet no algorithm can do so in polynomial time unless RP=NP. We also prove that this class admits efficient algorithms for standard algorithmic operations often considered in learning theory, such as an ERM. This implies that computational hardness is in this case inherent to the task of bandit learning. Beyond these results, we investigate additional themes such as learning under noise, trade-offs between noise models, and the relationship between query complexity and regret minimization.
A structured regression approach for evaluating model performance across intersectional subgroups
Jan 26, 2024
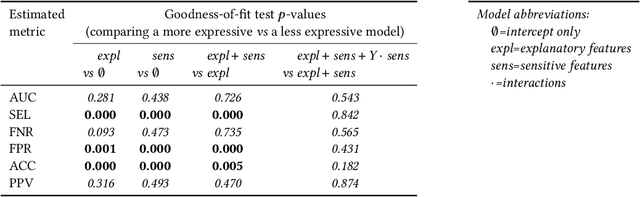

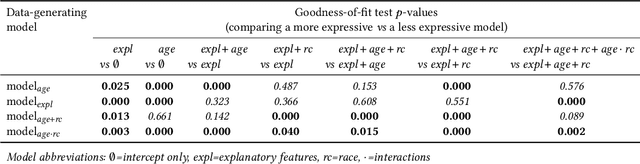
Disaggregated evaluation is a central task in AI fairness assessment, with the goal to measure an AI system's performance across different subgroups defined by combinations of demographic or other sensitive attributes. The standard approach is to stratify the evaluation data across subgroups and compute performance metrics separately for each group. However, even for moderately-sized evaluation datasets, sample sizes quickly get small once considering intersectional subgroups, which greatly limits the extent to which intersectional groups are considered in many disaggregated evaluations. In this work, we introduce a structured regression approach to disaggregated evaluation that we demonstrate can yield reliable system performance estimates even for very small subgroups. We also provide corresponding inference strategies for constructing confidence intervals and explore how goodness-of-fit testing can yield insight into the structure of fairness-related harms experienced by intersectional groups. We evaluate our approach on two publicly available datasets, and several variants of semi-synthetic data. The results show that our method is considerably more accurate than the standard approach, especially for small subgroups, and goodness-of-fit testing helps identify the key factors that drive differences in performance.
A Unified Model and Dimension for Interactive Estimation
Jun 09, 2023
We study an abstract framework for interactive learning called interactive estimation in which the goal is to estimate a target from its "similarity'' to points queried by the learner. We introduce a combinatorial measure called dissimilarity dimension which largely captures learnability in our model. We present a simple, general, and broadly-applicable algorithm, for which we obtain both regret and PAC generalization bounds that are polynomial in the new dimension. We show that our framework subsumes and thereby unifies two classic learning models: statistical-query learning and structured bandits. We also delineate how the dissimilarity dimension is related to well-known parameters for both frameworks, in some cases yielding significantly improved analyses.
Personalization Improves Privacy-Accuracy Tradeoffs in Federated Optimization
Feb 10, 2022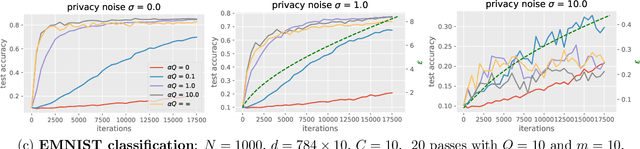
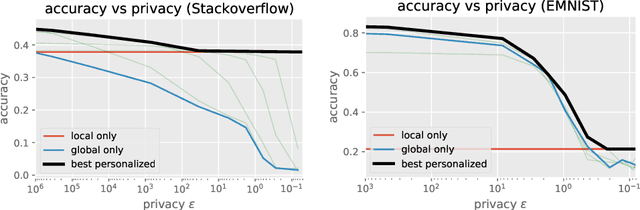
Large-scale machine learning systems often involve data distributed across a collection of users. Federated optimization algorithms leverage this structure by communicating model updates to a central server, rather than entire datasets. In this paper, we study stochastic optimization algorithms for a personalized federated learning setting involving local and global models subject to user-level (joint) differential privacy. While learning a private global model induces a cost of privacy, local learning is perfectly private. We show that coordinating local learning with private centralized learning yields a generically useful and improved tradeoff between accuracy and privacy. We illustrate our theoretical results with experiments on synthetic and real-world datasets.
Constrained episodic reinforcement learning in concave-convex and knapsack settings
Jun 09, 2020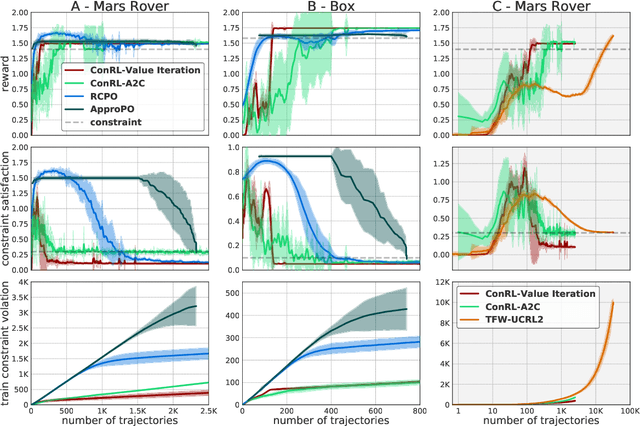

We propose an algorithm for tabular episodic reinforcement learning with constraints. We provide a modular analysis with strong theoretical guarantees for settings with concave rewards and convex constraints, and for settings with hard constraints (knapsacks). Most of the previous work in constrained reinforcement learning is limited to linear constraints, and the remaining work focuses on either the feasibility question or settings with a single episode. Our experiments demonstrate that the proposed algorithm significantly outperforms these approaches in existing constrained episodic environments.
Reinforcement Learning with Convex Constraints
Jun 21, 2019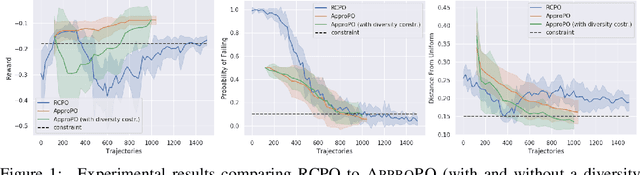
In standard reinforcement learning (RL), a learning agent seeks to optimize the overall reward. However, many key aspects of a desired behavior are more naturally expressed as constraints. For instance, the designer may want to limit the use of unsafe actions, increase the diversity of trajectories to enable exploration, or approximate expert trajectories when rewards are sparse. In this paper, we propose an algorithmic scheme that can handle a wide class of constraints in RL tasks: specifically, any constraints that require expected values of some vector measurements (such as the use of an action) to lie in a convex set. This captures previously studied constraints (such as safety and proximity to an expert), but also enables new classes of constraints (such as diversity). Our approach comes with rigorous theoretical guarantees and only relies on the ability to approximately solve standard RL tasks. As a result, it can be easily adapted to work with any model-free or model-based RL. In our experiments, we show that it matches previous algorithms that enforce safety via constraints, but can also enforce new properties that these algorithms do not incorporate, such as diversity.
Optimal and Adaptive Off-policy Evaluation in Contextual Bandits
Nov 11, 2017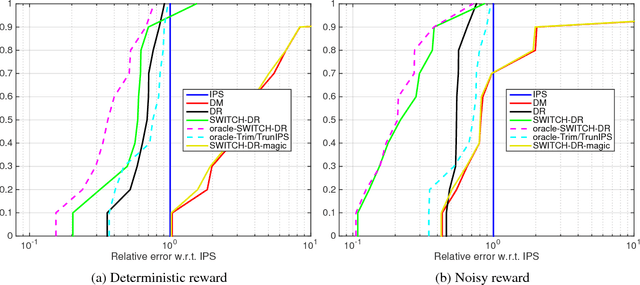
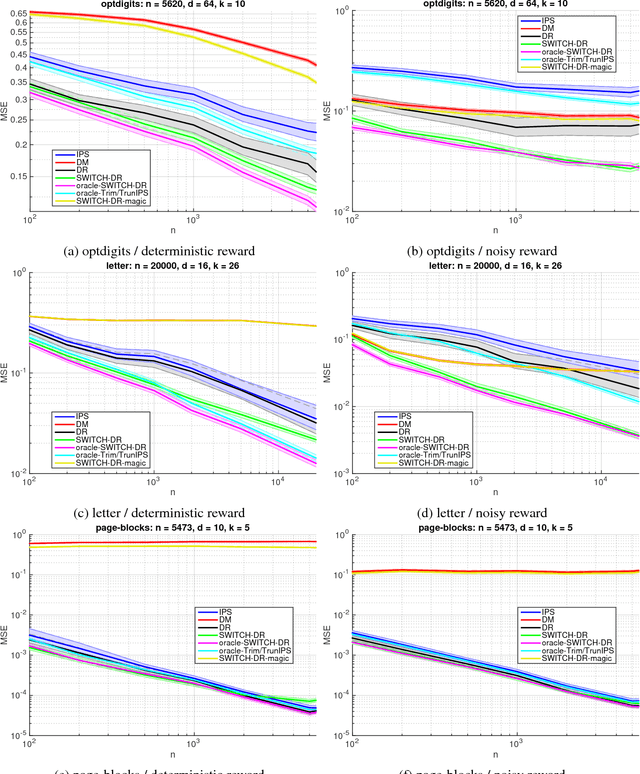
We study the off-policy evaluation problem---estimating the value of a target policy using data collected by another policy---under the contextual bandit model. We consider the general (agnostic) setting without access to a consistent model of rewards and establish a minimax lower bound on the mean squared error (MSE). The bound is matched up to constants by the inverse propensity scoring (IPS) and doubly robust (DR) estimators. This highlights the difficulty of the agnostic contextual setting, in contrast with multi-armed bandits and contextual bandits with access to a consistent reward model, where IPS is suboptimal. We then propose the SWITCH estimator, which can use an existing reward model (not necessarily consistent) to achieve a better bias-variance tradeoff than IPS and DR. We prove an upper bound on its MSE and demonstrate its benefits empirically on a diverse collection of data sets, often outperforming prior work by orders of magnitude.
Contextual Semibandits via Supervised Learning Oracles
Nov 04, 2016
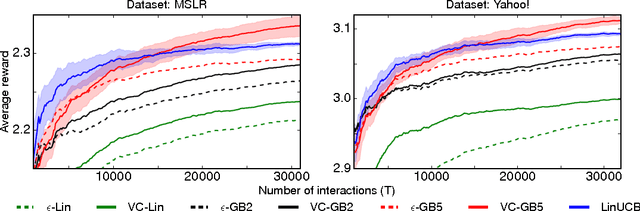
We study an online decision making problem where on each round a learner chooses a list of items based on some side information, receives a scalar feedback value for each individual item, and a reward that is linearly related to this feedback. These problems, known as contextual semibandits, arise in crowdsourcing, recommendation, and many other domains. This paper reduces contextual semibandits to supervised learning, allowing us to leverage powerful supervised learning methods in this partial-feedback setting. Our first reduction applies when the mapping from feedback to reward is known and leads to a computationally efficient algorithm with near-optimal regret. We show that this algorithm outperforms state-of-the-art approaches on real-world learning-to-rank datasets, demonstrating the advantage of oracle-based algorithms. Our second reduction applies to the previously unstudied setting when the linear mapping from feedback to reward is unknown. Our regret guarantees are superior to prior techniques that ignore the feedback.
Para-active learning
Oct 30, 2013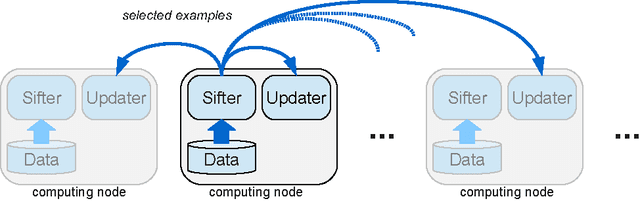

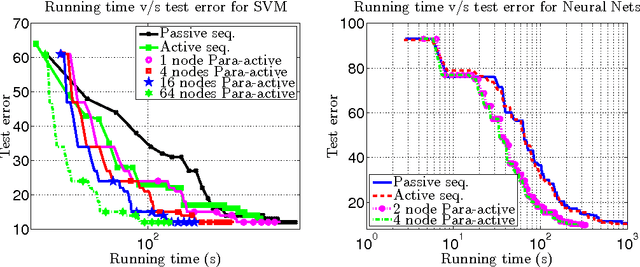
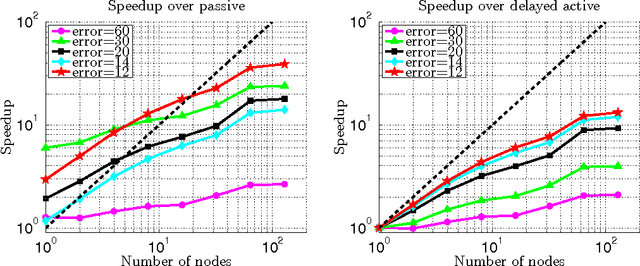
Training examples are not all equally informative. Active learning strategies leverage this observation in order to massively reduce the number of examples that need to be labeled. We leverage the same observation to build a generic strategy for parallelizing learning algorithms. This strategy is effective because the search for informative examples is highly parallelizable and because we show that its performance does not deteriorate when the sifting process relies on a slightly outdated model. Parallel active learning is particularly attractive to train nonlinear models with non-linear representations because there are few practical parallel learning algorithms for such models. We report preliminary experiments using both kernel SVMs and SGD-trained neural networks.