 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Overcoming Miscalibrated Conversational Priors in LLM-based Chatbots
Jun 01, 2024

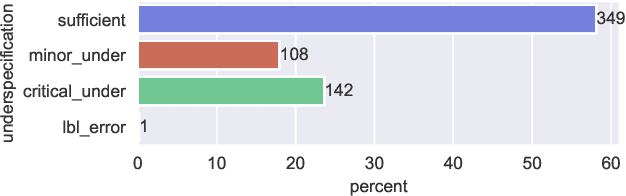

We explore the use of Large Language Model (LLM-based) chatbots to power recommender systems. We observe that the chatbots respond poorly when they encounter under-specified requests (e.g., they make incorrect assumptions, hedge with a long response, or refuse to answer). We conjecture that such miscalibrated response tendencies (i.e., conversational priors) can be attributed to LLM fine-tuning using annotators -- single-turn annotations may not capture multi-turn conversation utility, and the annotators' preferences may not even be representative of users interacting with a recommender system. We first analyze public LLM chat logs to conclude that query under-specification is common. Next, we study synthetic recommendation problems with configurable latent item utilities and frame them as Partially Observed Decision Processes (PODP). We find that pre-trained LLMs can be sub-optimal for PODPs and derive better policies that clarify under-specified queries when appropriate. Then, we re-calibrate LLMs by prompting them with learned control messages to approximate the improved policy. Finally, we show empirically that our lightweight learning approach effectively uses logged conversation data to re-calibrate the response strategies of LLM-based chatbots for recommendation tasks.
A structured regression approach for evaluating model performance across intersectional subgroups
Jan 26, 2024
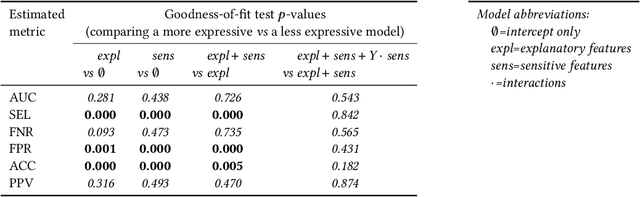

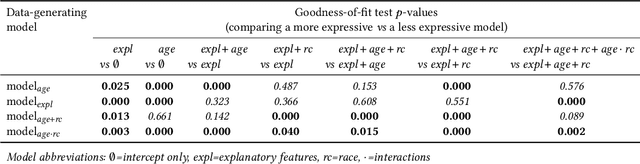
Disaggregated evaluation is a central task in AI fairness assessment, with the goal to measure an AI system's performance across different subgroups defined by combinations of demographic or other sensitive attributes. The standard approach is to stratify the evaluation data across subgroups and compute performance metrics separately for each group. However, even for moderately-sized evaluation datasets, sample sizes quickly get small once considering intersectional subgroups, which greatly limits the extent to which intersectional groups are considered in many disaggregated evaluations. In this work, we introduce a structured regression approach to disaggregated evaluation that we demonstrate can yield reliable system performance estimates even for very small subgroups. We also provide corresponding inference strategies for constructing confidence intervals and explore how goodness-of-fit testing can yield insight into the structure of fairness-related harms experienced by intersectional groups. We evaluate our approach on two publicly available datasets, and several variants of semi-synthetic data. The results show that our method is considerably more accurate than the standard approach, especially for small subgroups, and goodness-of-fit testing helps identify the key factors that drive differences in performance.
Data Contamination Through the Lens of Time
Oct 16, 2023Recent claims about the impressive abilities of large language models (LLMs) are often supported by evaluating publicly available benchmarks. Since LLMs train on wide swaths of the internet, this practice raises concerns of data contamination, i.e., evaluating on examples that are explicitly or implicitly included in the training data. Data contamination remains notoriously challenging to measure and mitigate, even with partial attempts like controlled experimentation of training data, canary strings, or embedding similarities. In this work, we conduct the first thorough longitudinal analysis of data contamination in LLMs by using the natural experiment of training cutoffs in GPT models to look at benchmarks released over time. Specifically, we consider two code/mathematical problem-solving datasets, Codeforces and Project Euler, and find statistically significant trends among LLM pass rate vs. GitHub popularity and release date that provide strong evidence of contamination. By open-sourcing our dataset, raw results, and evaluation framework, our work paves the way for rigorous analyses of data contamination in modern models. We conclude with a discussion of best practices and future steps for publicly releasing benchmarks in the age of LLMs that train on webscale data.
Networked Restless Bandits with Positive Externalities
Dec 09, 2022



Restless multi-armed bandits are often used to model budget-constrained resource allocation tasks where receipt of the resource is associated with an increased probability of a favorable state transition. Prior work assumes that individual arms only benefit if they receive the resource directly. However, many allocation tasks occur within communities and can be characterized by positive externalities that allow arms to derive partial benefit when their neighbor(s) receive the resource. We thus introduce networked restless bandits, a novel multi-armed bandit setting in which arms are both restless and embedded within a directed graph. We then present Greta, a graph-aware, Whittle index-based heuristic algorithm that can be used to efficiently construct a constrained reward-maximizing action vector at each timestep. Our empirical results demonstrate that Greta outperforms comparison policies across a range of hyperparameter values and graph topologies.
Planning to Fairly Allocate: Probabilistic Fairness in the Restless Bandit Setting
Jun 14, 2021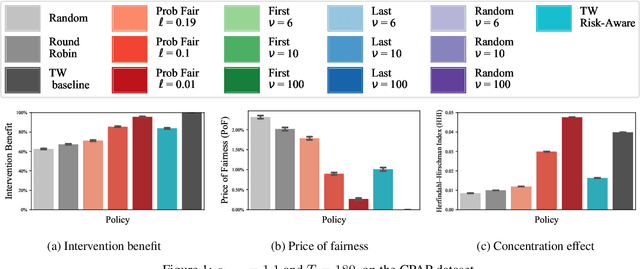
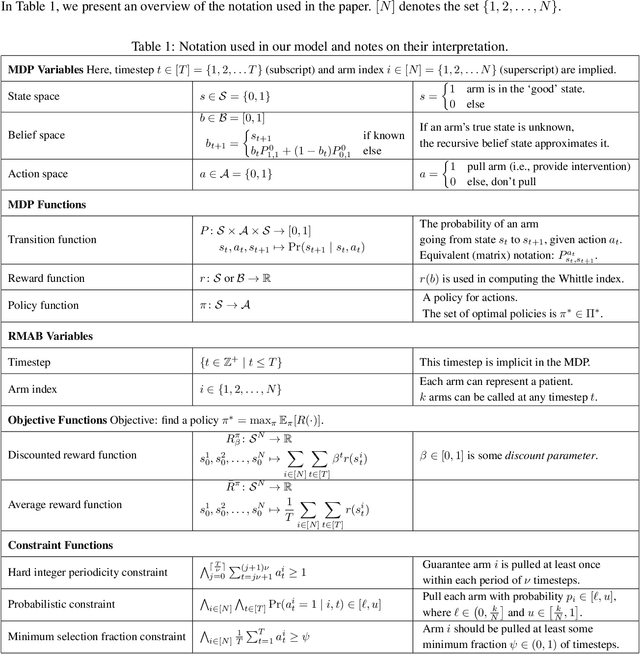
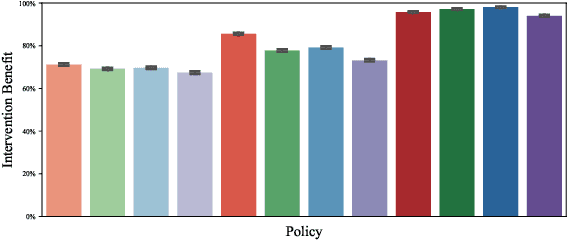
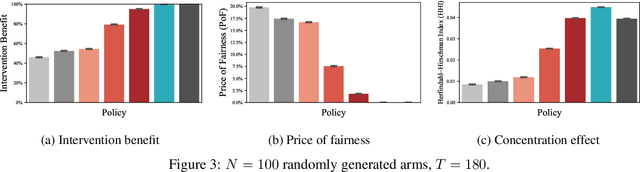
Restless and collapsing bandits are commonly used to model constrained resource allocation in settings featuring arms with action-dependent transition probabilities, such as allocating health interventions among patients [Whittle, 1988; Mate et al., 2020]. However, state-of-the-art Whittle-index-based approaches to this planning problem either do not consider fairness among arms, or incentivize fairness without guaranteeing it [Mate et al., 2021]. Additionally, their optimality guarantees only apply when arms are indexable and threshold-optimal. We demonstrate that the incorporation of hard fairness constraints necessitates the coupling of arms, which undermines the tractability, and by extension, indexability of the problem. We then introduce ProbFair, a probabilistically fair stationary policy that maximizes total expected reward and satisfies the budget constraint, while ensuring a strictly positive lower bound on the probability of being pulled at each timestep. We evaluate our algorithm on a real-world application, where interventions support continuous positive airway pressure (CPAP) therapy adherence among obstructive sleep apnea (OSA) patients, as well as simulations on a broader class of synthetic transition matrices.
MedNLI Is Not Immune: Natural Language Inference Artifacts in the Clinical Domain
Jun 02, 2021



Crowdworker-constructed natural language inference (NLI) datasets have been found to contain statistical artifacts associated with the annotation process that allow hypothesis-only classifiers to achieve better-than-random performance (Poliak et al., 2018; Gururanganet et al., 2018; Tsuchiya, 2018). We investigate whether MedNLI, a physician-annotated dataset with premises extracted from clinical notes, contains such artifacts (Romanov and Shivade, 2018). We find that entailed hypotheses contain generic versions of specific concepts in the premise, as well as modifiers related to responsiveness, duration, and probability. Neutral hypotheses feature conditions and behaviors that co-occur with, or cause, the condition(s) in the premise. Contradiction hypotheses feature explicit negation of the premise and implicit negation via assertion of good health. Adversarial filtering demonstrates that performance degrades when evaluated on the difficult subset. We provide partition information and recommendations for alternative dataset construction strategies for knowledge-intensive domains.