 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Analysis of Multi-Agent Reinforcement Learning Policies for Crop Planning Decision Support
Dec 03, 2024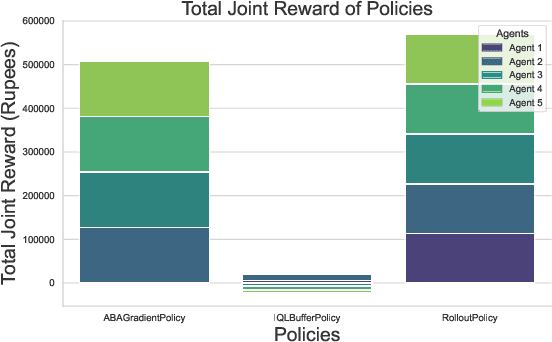
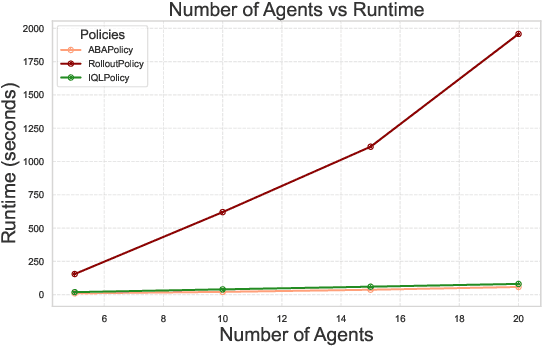
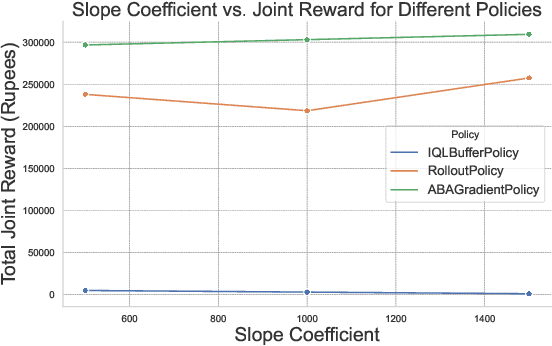
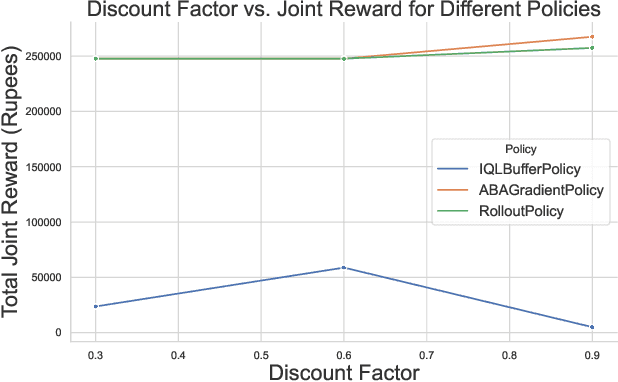
In India, the majority of farmers are classified as small or marginal, making their livelihoods particularly vulnerable to economic losses due to market saturation and climate risks. Effective crop planning can significantly impact their expected income, yet existing decision support systems (DSS) often provide generic recommendations that fail to account for real-time market dynamics and the interactions among multiple farmers. In this paper, we evaluate the viability of three multi-agent reinforcement learning (MARL) approaches for optimizing total farmer income and promoting fairness in crop planning: Independent Q-Learning (IQL), where each farmer acts independently without coordination, Agent-by-Agent (ABA), which sequentially optimizes each farmer's policy in relation to the others, and the Multi-agent Rollout Policy, which jointly optimizes all farmers' actions for global reward maximization. Our results demonstrate that while IQL offers computational efficiency with linear runtime, it struggles with coordination among agents, leading to lower total rewards and an unequal distribution of income. Conversely, the Multi-agent Rollout policy achieves the highest total rewards and promotes equitable income distribution among farmers but requires significantly more computational resources, making it less practical for large numbers of agents. ABA strikes a balance between runtime efficiency and reward optimization, offering reasonable total rewards with acceptable fairness and scalability. These findings highlight the importance of selecting appropriate MARL approaches in DSS to provide personalized and equitable crop planning recommendations, advancing the development of more adaptive and farmer-centric agricultural decision-making systems.
An Online Optimization-Based Decision Support Tool for Small Farmers in India: Learning in Non-stationary Environments
Nov 28, 2023
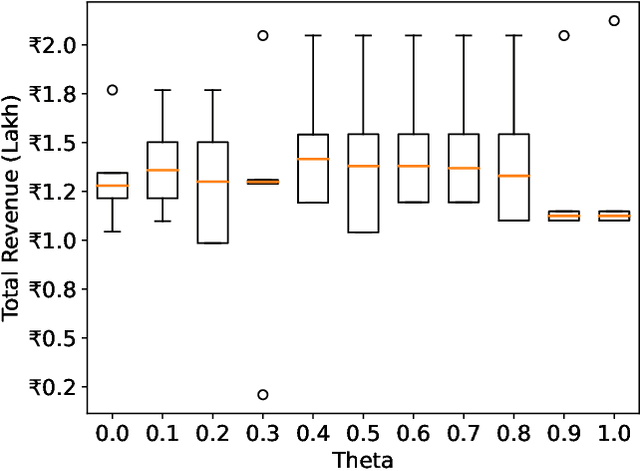
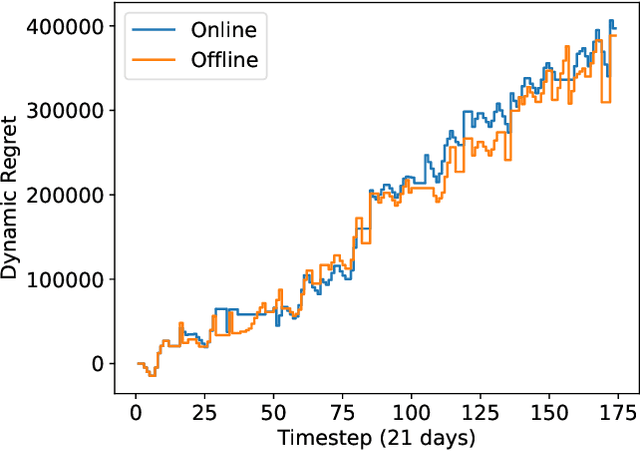

Crop management decision support systems are specialized tools for farmers that reduce the riskiness of revenue streams, especially valuable for use under the current climate changes that impact agricultural productivity. Unfortunately, small farmers in India, who could greatly benefit from these tools, do not have access to them. In this paper, we model an individual greenhouse as a Markov Decision Process (MDP) and adapt Li and Li (2019)'s Follow the Weighted Leader (FWL) online learning algorithm to offer crop planning advice. We successfully produce utility-preserving cropping pattern suggestions in simulations. When we compare against an offline planning algorithm, we achieve the same cumulative revenue with greatly reduced runtime.
Planning to Fairly Allocate: Probabilistic Fairness in the Restless Bandit Setting
Jun 14, 2021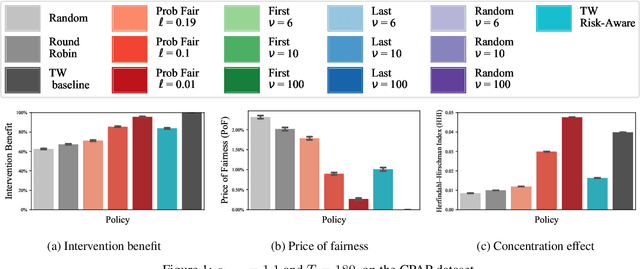
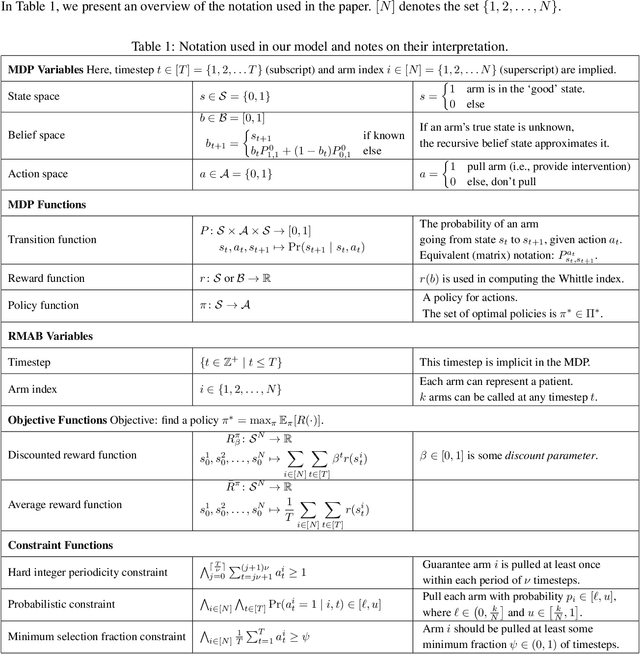
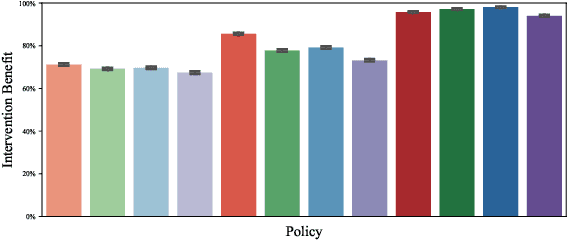
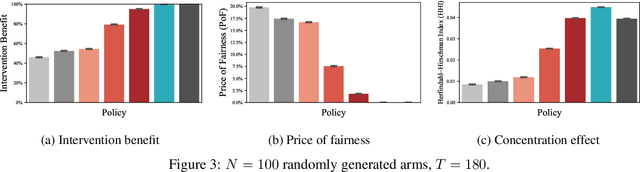
Restless and collapsing bandits are commonly used to model constrained resource allocation in settings featuring arms with action-dependent transition probabilities, such as allocating health interventions among patients [Whittle, 1988; Mate et al., 2020]. However, state-of-the-art Whittle-index-based approaches to this planning problem either do not consider fairness among arms, or incentivize fairness without guaranteeing it [Mate et al., 2021]. Additionally, their optimality guarantees only apply when arms are indexable and threshold-optimal. We demonstrate that the incorporation of hard fairness constraints necessitates the coupling of arms, which undermines the tractability, and by extension, indexability of the problem. We then introduce ProbFair, a probabilistically fair stationary policy that maximizes total expected reward and satisfies the budget constraint, while ensuring a strictly positive lower bound on the probability of being pulled at each timestep. We evaluate our algorithm on a real-world application, where interventions support continuous positive airway pressure (CPAP) therapy adherence among obstructive sleep apnea (OSA) patients, as well as simulations on a broader class of synthetic transition matrices.