 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable ML Feature Engineering via Planning in Constrained-Topology of LLM Agents
Jan 15, 2026Recent advances in code generation models have unlocked unprecedented opportunities for automating feature engineering, yet their adoption in real-world ML teams remains constrained by critical challenges: (i) the scarcity of datasets capturing the iterative and complex coding processes of production-level feature engineering, (ii) limited integration and personalization of widely used coding agents, such as CoPilot and Devin, with a team's unique tools, codebases, workflows, and practices, and (iii) suboptimal human-AI collaboration due to poorly timed or insufficient feedback. We address these challenges with a planner-guided, constrained-topology multi-agent framework that generates code for repositories in a multi-step fashion. The LLM-powered planner leverages a team's environment, represented as a graph, to orchestrate calls to available agents, generate context-aware prompts, and use downstream failures to retroactively correct upstream artifacts. It can request human intervention at critical steps, ensuring generated code is reliable, maintainable, and aligned with team expectations. On a novel in-house dataset, our approach achieves 38% and 150% improvement in the evaluation metric over manually crafted and unplanned workflows respectively. In practice, when building features for recommendation models serving over 120 million users, our approach has delivered real-world impact by reducing feature engineering cycles from three weeks to a single day.
Data Contamination Through the Lens of Time
Oct 16, 2023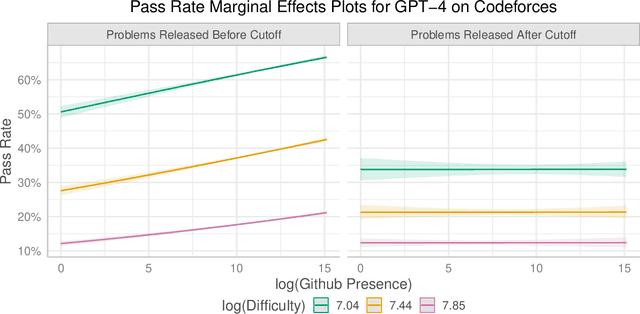
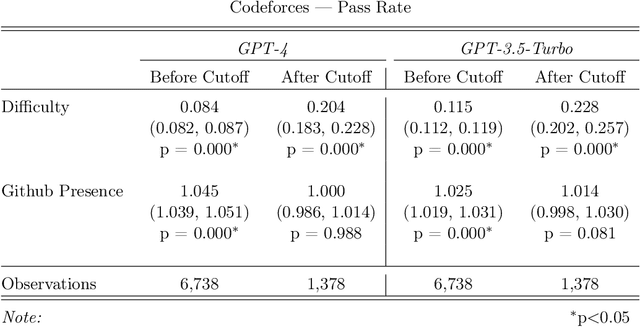
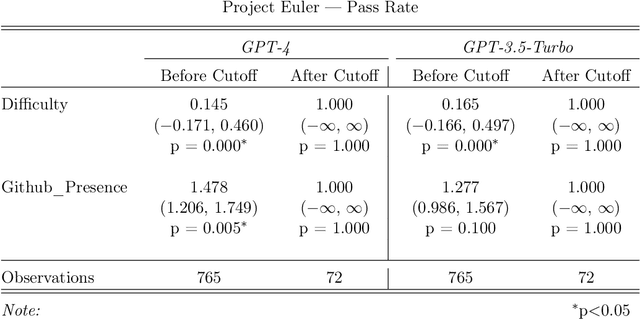
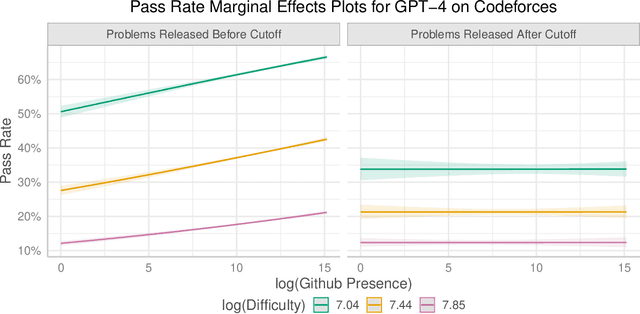
Recent claims about the impressive abilities of large language models (LLMs) are often supported by evaluating publicly available benchmarks. Since LLMs train on wide swaths of the internet, this practice raises concerns of data contamination, i.e., evaluating on examples that are explicitly or implicitly included in the training data. Data contamination remains notoriously challenging to measure and mitigate, even with partial attempts like controlled experimentation of training data, canary strings, or embedding similarities. In this work, we conduct the first thorough longitudinal analysis of data contamination in LLMs by using the natural experiment of training cutoffs in GPT models to look at benchmarks released over time. Specifically, we consider two code/mathematical problem-solving datasets, Codeforces and Project Euler, and find statistically significant trends among LLM pass rate vs. GitHub popularity and release date that provide strong evidence of contamination. By open-sourcing our dataset, raw results, and evaluation framework, our work paves the way for rigorous analyses of data contamination in modern models. We conclude with a discussion of best practices and future steps for publicly releasing benchmarks in the age of LLMs that train on webscale data.
Active Learning for Fine-Grained Sketch-Based Image Retrieval
Sep 15, 2023The ability to retrieve a photo by mere free-hand sketching highlights the immense potential of Fine-grained sketch-based image retrieval (FG-SBIR). However, its rapid practical adoption, as well as scalability, is limited by the expense of acquiring faithful sketches for easily available photo counterparts. A solution to this problem is Active Learning, which could minimise the need for labeled sketches while maximising performance. Despite extensive studies in the field, there exists no work that utilises it for reducing sketching effort in FG-SBIR tasks. To this end, we propose a novel active learning sampling technique that drastically minimises the need for drawing photo sketches. Our proposed approach tackles the trade-off between uncertainty and diversity by utilising the relationship between the existing photo-sketch pair to a photo that does not have its sketch and augmenting this relation with its intermediate representations. Since our approach relies only on the underlying data distribution, it is agnostic of the modelling approach and hence is applicable to other cross-modal instance-level retrieval tasks as well. With experimentation over two publicly available fine-grained SBIR datasets ChairV2 and ShoeV2, we validate our approach and reveal its superiority over adapted baselines.
Language Models Get a Gender Makeover: Mitigating Gender Bias with Few-Shot Data Interventions
Jun 07, 2023



Societal biases present in pre-trained large language models are a critical issue as these models have been shown to propagate biases in countless downstream applications, rendering them unfair towards specific groups of people. Since large-scale retraining of these models from scratch is both time and compute-expensive, a variety of approaches have been previously proposed that de-bias a pre-trained model. While the majority of current state-of-the-art debiasing methods focus on changes to the training regime, in this paper, we propose data intervention strategies as a powerful yet simple technique to reduce gender bias in pre-trained models. Specifically, we empirically show that by fine-tuning a pre-trained model on only 10 de-biased (intervened) training examples, the tendency to favor any gender is significantly reduced. Since our proposed method only needs a few training examples, our few-shot debiasing approach is highly feasible and practical. Through extensive experimentation, we show that our debiasing technique performs better than competitive state-of-the-art baselines with minimal loss in language modeling ability.