 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn The Robustness of Foundational 3D Medical Image Segmentation Models Against Imprecise Visual Prompts
Jan 23, 2026While 3D foundational models have shown promise for promptable segmentation of medical volumes, their robustness to imprecise prompts remains under-explored. In this work, we aim to address this gap by systematically studying the effect of various controlled perturbations of dense visual prompts, that closely mimic real-world imprecision. By conducting experiments with two recent foundational models on a multi-organ abdominal segmentation task, we reveal several facets of promptable medical segmentation, especially pertaining to reliance on visual shape and spatial cues, and the extent of resilience of models towards certain perturbations. Codes are available at: https://github.com/ucsdbiag/Prompt-Robustness-MedSegFMs
NoTeS-Bank: Benchmarking Neural Transcription and Search for Scientific Notes Understanding
Apr 12, 2025Understanding and reasoning over academic handwritten notes remains a challenge in document AI, particularly for mathematical equations, diagrams, and scientific notations. Existing visual question answering (VQA) benchmarks focus on printed or structured handwritten text, limiting generalization to real-world note-taking. To address this, we introduce NoTeS-Bank, an evaluation benchmark for Neural Transcription and Search in note-based question answering. NoTeS-Bank comprises complex notes across multiple domains, requiring models to process unstructured and multimodal content. The benchmark defines two tasks: (1) Evidence-Based VQA, where models retrieve localized answers with bounding-box evidence, and (2) Open-Domain VQA, where models classify the domain before retrieving relevant documents and answers. Unlike classical Document VQA datasets relying on optical character recognition (OCR) and structured data, NoTeS-BANK demands vision-language fusion, retrieval, and multimodal reasoning. We benchmark state-of-the-art Vision-Language Models (VLMs) and retrieval frameworks, exposing structured transcription and reasoning limitations. NoTeS-Bank provides a rigorous evaluation with NDCG@5, MRR, Recall@K, IoU, and ANLS, establishing a new standard for visual document understanding and reasoning.
Zero-shot Domain Generalization of Foundational Models for 3D Medical Image Segmentation: An Experimental Study
Mar 28, 2025Domain shift, caused by variations in imaging modalities and acquisition protocols, limits model generalization in medical image segmentation. While foundation models (FMs) trained on diverse large-scale data hold promise for zero-shot generalization, their application to volumetric medical data remains underexplored. In this study, we examine their ability towards domain generalization (DG), by conducting a comprehensive experimental study encompassing 6 medical segmentation FMs and 12 public datasets spanning multiple modalities and anatomies. Our findings reveal the potential of promptable FMs in bridging the domain gap via smart prompting techniques. Additionally, by probing into multiple facets of zero-shot DG, we offer valuable insights into the viability of FMs for DG and identify promising avenues for future research.
UniCoRN: Latent Diffusion-based Unified Controllable Image Restoration Network across Multiple Degradations
Mar 21, 2025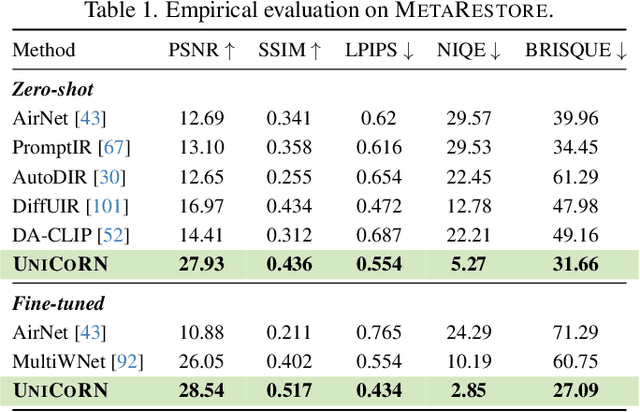


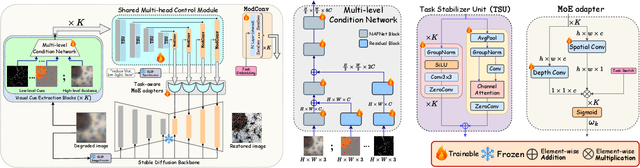
Image restoration is essential for enhancing degraded images across computer vision tasks. However, most existing methods address only a single type of degradation (e.g., blur, noise, or haze) at a time, limiting their real-world applicability where multiple degradations often occur simultaneously. In this paper, we propose UniCoRN, a unified image restoration approach capable of handling multiple degradation types simultaneously using a multi-head diffusion model. Specifically, we uncover the potential of low-level visual cues extracted from images in guiding a controllable diffusion model for real-world image restoration and we design a multi-head control network adaptable via a mixture-of-experts strategy. We train our model without any prior assumption of specific degradations, through a smartly designed curriculum learning recipe. Additionally, we also introduce MetaRestore, a metalens imaging benchmark containing images with multiple degradations and artifacts. Extensive evaluations on several challenging datasets, including our benchmark, demonstrate that our method achieves significant performance gains and can robustly restore images with severe degradations. Project page: https://codejaeger.github.io/unicorn-gh
Downstream Analysis of Foundational Medical Vision Models for Disease Progression
Mar 21, 2025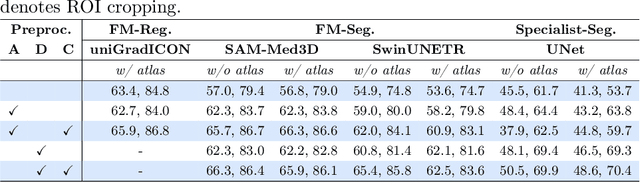

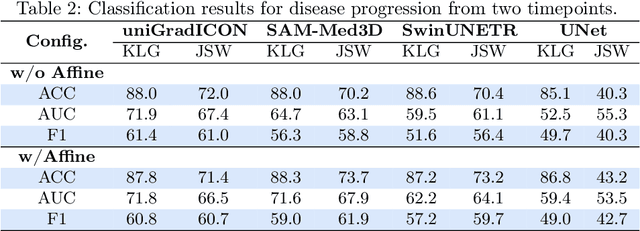
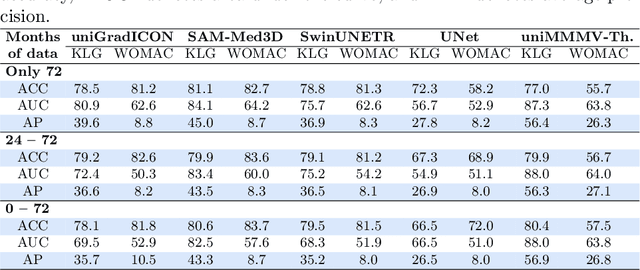
Medical vision foundational models are used for a wide variety of tasks, including medical image segmentation and registration. This work evaluates the ability of these models to predict disease progression using a simple linear probe. We hypothesize that intermediate layer features of segmentation models capture structural information, while those of registration models encode knowledge of change over time. Beyond demonstrating that these features are useful for disease progression prediction, we also show that registration model features do not require spatially aligned input images. However, for segmentation models, spatial alignment is essential for optimal performance. Our findings highlight the importance of spatial alignment and the utility of foundation model features for image registration.
Towards Generative Class Prompt Learning for Few-shot Visual Recognition
Sep 03, 2024



Although foundational vision-language models (VLMs) have proven to be very successful for various semantic discrimination tasks, they still struggle to perform faithfully for fine-grained categorization. Moreover, foundational models trained on one domain do not generalize well on a different domain without fine-tuning. We attribute these to the limitations of the VLM's semantic representations and attempt to improve their fine-grained visual awareness using generative modeling. Specifically, we propose two novel methods: Generative Class Prompt Learning (GCPL) and Contrastive Multi-class Prompt Learning (CoMPLe). Utilizing text-to-image diffusion models, GCPL significantly improves the visio-linguistic synergy in class embeddings by conditioning on few-shot exemplars with learnable class prompts. CoMPLe builds on this foundation by introducing a contrastive learning component that encourages inter-class separation during the generative optimization process. Our empirical results demonstrate that such a generative class prompt learning approach substantially outperform existing methods, offering a better alternative to few shot image recognition challenges. The source code will be made available at: https://github.com/soumitri2001/GCPL.
Active Learning for Fine-Grained Sketch-Based Image Retrieval
Sep 15, 2023The ability to retrieve a photo by mere free-hand sketching highlights the immense potential of Fine-grained sketch-based image retrieval (FG-SBIR). However, its rapid practical adoption, as well as scalability, is limited by the expense of acquiring faithful sketches for easily available photo counterparts. A solution to this problem is Active Learning, which could minimise the need for labeled sketches while maximising performance. Despite extensive studies in the field, there exists no work that utilises it for reducing sketching effort in FG-SBIR tasks. To this end, we propose a novel active learning sampling technique that drastically minimises the need for drawing photo sketches. Our proposed approach tackles the trade-off between uncertainty and diversity by utilising the relationship between the existing photo-sketch pair to a photo that does not have its sketch and augmenting this relation with its intermediate representations. Since our approach relies only on the underlying data distribution, it is agnostic of the modelling approach and hence is applicable to other cross-modal instance-level retrieval tasks as well. With experimentation over two publicly available fine-grained SBIR datasets ChairV2 and ShoeV2, we validate our approach and reveal its superiority over adapted baselines.
DySTreSS: Dynamically Scaled Temperature in Self-Supervised Contrastive Learning
Aug 02, 2023In contemporary self-supervised contrastive algorithms like SimCLR, MoCo, etc., the task of balancing attraction between two semantically similar samples and repulsion between two samples from different classes is primarily affected by the presence of hard negative samples. While the InfoNCE loss has been shown to impose penalties based on hardness, the temperature hyper-parameter is the key to regulating the penalties and the trade-off between uniformity and tolerance. In this work, we focus our attention to improve the performance of InfoNCE loss in SSL by studying the effect of temperature hyper-parameter values. We propose a cosine similarity-dependent temperature scaling function to effectively optimize the distribution of the samples in the feature space. We further analyze the uniformity and tolerance metrics to investigate the optimal regions in the cosine similarity space for better optimization. Additionally, we offer a comprehensive examination of the behavior of local and global structures in the feature space throughout the pre-training phase, as the temperature varies. Experimental evidence shows that the proposed framework outperforms or is at par with the contrastive loss-based SSL algorithms. We believe our work (DySTreSS) on temperature scaling in SSL provides a foundation for future research in contrastive learning.
BeAts: Bengali Speech Acts Recognition using Multimodal Attention Fusion
Jun 05, 2023Spoken languages often utilise intonation, rhythm, intensity, and structure, to communicate intention, which can be interpreted differently depending on the rhythm of speech of their utterance. These speech acts provide the foundation of communication and are unique in expression to the language. Recent advancements in attention-based models, demonstrating their ability to learn powerful representations from multilingual datasets, have performed well in speech tasks and are ideal to model specific tasks in low resource languages. Here, we develop a novel multimodal approach combining two models, wav2vec2.0 for audio and MarianMT for text translation, by using multimodal attention fusion to predict speech acts in our prepared Bengali speech corpus. We also show that our model BeAts ($\underline{\textbf{Be}}$ngali speech acts recognition using Multimodal $\underline{\textbf{At}}$tention Fu$\underline{\textbf{s}}$ion) significantly outperforms both the unimodal baseline using only speech data and a simpler bimodal fusion using both speech and text data. Project page: https://soumitri2001.github.io/BeAts
Exploiting Unlabelled Photos for Stronger Fine-Grained SBIR
Mar 24, 2023This paper advances the fine-grained sketch-based image retrieval (FG-SBIR) literature by putting forward a strong baseline that overshoots prior state-of-the-arts by ~11%. This is not via complicated design though, but by addressing two critical issues facing the community (i) the gold standard triplet loss does not enforce holistic latent space geometry, and (ii) there are never enough sketches to train a high accuracy model. For the former, we propose a simple modification to the standard triplet loss, that explicitly enforces separation amongst photos/sketch instances. For the latter, we put forward a novel knowledge distillation module can leverage photo data for model training. Both modules are then plugged into a novel plug-n-playable training paradigm that allows for more stable training. More specifically, for (i) we employ an intra-modal triplet loss amongst sketches to bring sketches of the same instance closer from others, and one more amongst photos to push away different photo instances while bringing closer a structurally augmented version of the same photo (offering a gain of ~4-6%). To tackle (ii), we first pre-train a teacher on the large set of unlabelled photos over the aforementioned intra-modal photo triplet loss. Then we distill the contextual similarity present amongst the instances in the teacher's embedding space to that in the student's embedding space, by matching the distribution over inter-feature distances of respective samples in both embedding spaces (delivering a further gain of ~4-5%). Apart from outperforming prior arts significantly, our model also yields satisfactory results on generalising to new classes. Project page: https://aneeshan95.github.io/Sketch_PVT/