 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Evaluation of Non-Contrastive Self-Supervised Learning for Federated Medical Image Analysis
Mar 09, 2023



Privacy and annotation bottlenecks are two major issues that profoundly affect the practicality of machine learning-based medical image analysis. Although significant progress has been made in these areas, these issues are not yet fully resolved. In this paper, we seek to tackle these concerns head-on and systematically explore the applicability of non-contrastive self-supervised learning (SSL) algorithms under federated learning (FL) simulations for medical image analysis. We conduct thorough experimentation of recently proposed state-of-the-art non-contrastive frameworks under standard FL setups. With the SoTA Contrastive Learning algorithm, SimCLR as our comparative baseline, we benchmark the performances of our 4 chosen non-contrastive algorithms under non-i.i.d. data conditions and with a varying number of clients. We present a holistic evaluation of these techniques on 6 standardized medical imaging datasets. We further analyse different trends inferred from the findings of our research, with the aim to find directions for further research based on ours. To the best of our knowledge, ours is the first to perform such a thorough analysis of federated self-supervised learning for medical imaging. All of our source code will be made public upon acceptance of the paper.
Exploring Self-Supervised Representation Learning For Low-Resource Medical Image Analysis
Mar 03, 2023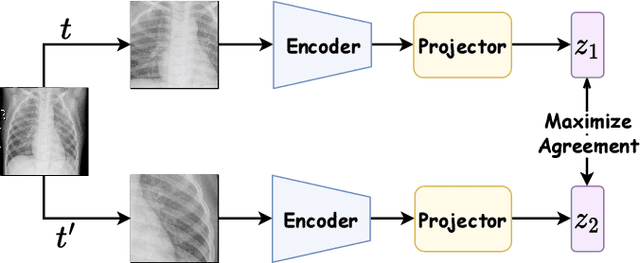
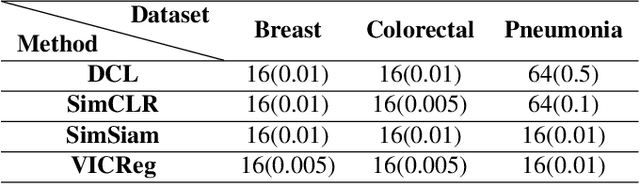
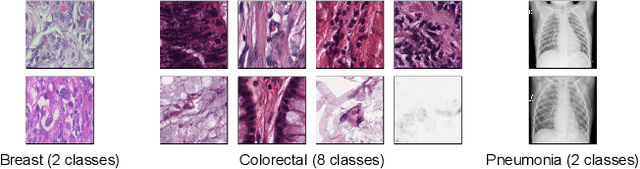
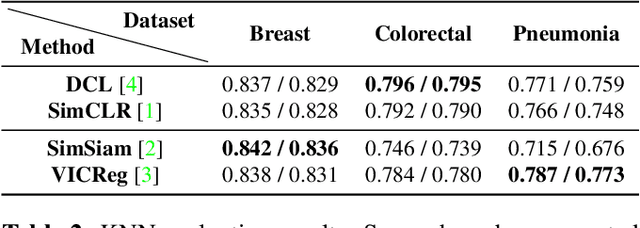
The success of self-supervised learning (SSL) has mostly been attributed to the availability of unlabeled yet large-scale datasets. However, in a specialized domain such as medical imaging which is a lot different from natural images, the assumption of data availability is unrealistic and impractical, as the data itself is scanty and found in small databases, collected for specific prognosis tasks. To this end, we seek to investigate the applicability of self-supervised learning algorithms on small-scale medical imaging datasets. In particular, we evaluate $4$ state-of-the-art SSL methods on three publicly accessible \emph{small} medical imaging datasets. Our investigation reveals that in-domain low-resource SSL pre-training can yield competitive performance to transfer learning from large-scale datasets (such as ImageNet). Furthermore, we extensively analyse our empirical findings to provide valuable insights that can motivate for further research towards circumventing the need for pre-training on a large image corpus. To the best of our knowledge, this is the first attempt to holistically explore self-supervision on low-resource medical datasets.