 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Self-Supervised Representation Learning For Low-Resource Medical Image Analysis
Paper and Code
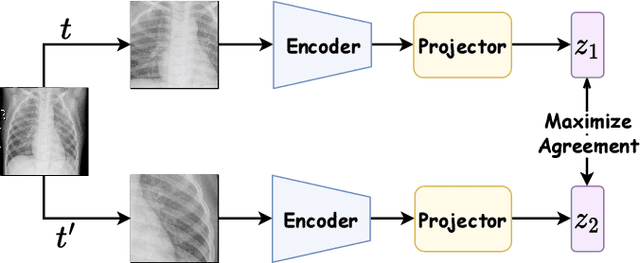
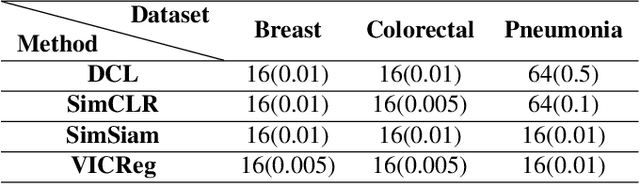
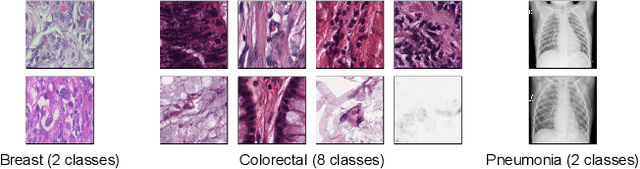
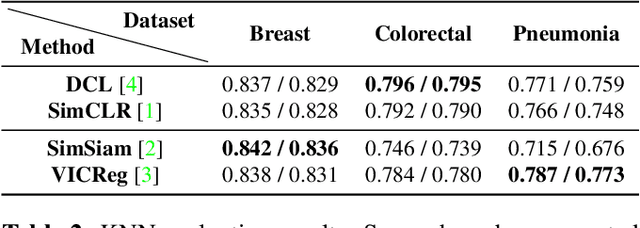
The success of self-supervised learning (SSL) has mostly been attributed to the availability of unlabeled yet large-scale datasets. However, in a specialized domain such as medical imaging which is a lot different from natural images, the assumption of data availability is unrealistic and impractical, as the data itself is scanty and found in small databases, collected for specific prognosis tasks. To this end, we seek to investigate the applicability of self-supervised learning algorithms on small-scale medical imaging datasets. In particular, we evaluate $4$ state-of-the-art SSL methods on three publicly accessible \emph{small} medical imaging datasets. Our investigation reveals that in-domain low-resource SSL pre-training can yield competitive performance to transfer learning from large-scale datasets (such as ImageNet). Furthermore, we extensively analyse our empirical findings to provide valuable insights that can motivate for further research towards circumventing the need for pre-training on a large image corpus. To the best of our knowledge, this is the first attempt to holistically explore self-supervision on low-resource medical datasets.