 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Applicator Gap with Data-Doping:Dual-Domain Learning for Precise Bladder Segmentation in CT-Guided Brachytherapy
Jan 28, 2026Performance degradation due to covariate shift remains a major challenge for deep learning models in medical image segmentation. An open question is whether samples from a shifted distribution can effectively support learning when combined with limited target domain data. We investigate this problem in the context of bladder segmentation in CT guided gynecological brachytherapy, a critical task for accurate dose optimization and organ at risk sparing. While CT scans without brachytherapy applicators (no applicator: NA) are widely available, scans with applicators inserted (with applicator: WA) are scarce and exhibit substantial anatomical deformation and imaging artifacts, making automated segmentation particularly difficult. We propose a dual domain learning strategy that integrates NA and WA CT data to improve robustness and generalizability under covariate shift. Using a curated assorted dataset, we show that NA data alone fail to capture the anatomical and artifact related characteristics of WA images. However, introducing a modest proportion of WA data into a predominantly NA training set leads to significant performance improvements. Through systematic experiments across axial, coronal, and sagittal planes using multiple deep learning architectures, we demonstrate that doping only 10 to 30 percent WA data achieves segmentation performance comparable to models trained exclusively on WA data. The proposed approach attains Dice similarity coefficients of up to 0.94 and Intersection over Union scores of up to 0.92, indicating effective domain adaptation and improved clinical reliability. This study highlights the value of integrating anatomically similar but distribution shifted datasets to overcome data scarcity and enhance deep learning based segmentation for brachytherapy treatment planning.
Federated Self-Supervised Learning for One-Shot Cross-Modal and Cross-Imaging Technique Segmentation
Mar 30, 2025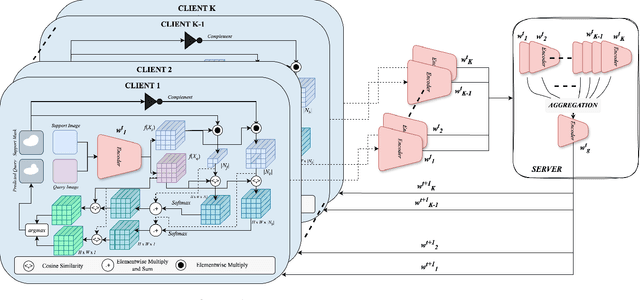



Decentralized federated learning enables learning of data representations from multiple sources without compromising the privacy of the clients. In applications like medical image segmentation, where obtaining a large annotated dataset from a single source is a distressing problem, federated self-supervised learning can provide some solace. In this work, we push the limits further by exploring a federated self-supervised one-shot segmentation task representing a more data-scarce scenario. We adopt a pre-existing self-supervised few-shot segmentation framework CoWPro and adapt it to the federated learning scenario. To the best of our knowledge, this work is the first to attempt a self-supervised few-shot segmentation task in the federated learning domain. Moreover, we consider the clients to be constituted of data from different modalities and imaging techniques like MR or CT, which makes the problem even harder. Additionally, we reinforce and improve the baseline CoWPro method using a fused dice loss which shows considerable improvement in performance over the baseline CoWPro. Finally, we evaluate this novel framework on a completely unseen held-out part of the local client dataset. We observe that the proposed framework can achieve performance at par or better than the FedAvg version of the CoWPro framework on the held-out validation dataset.
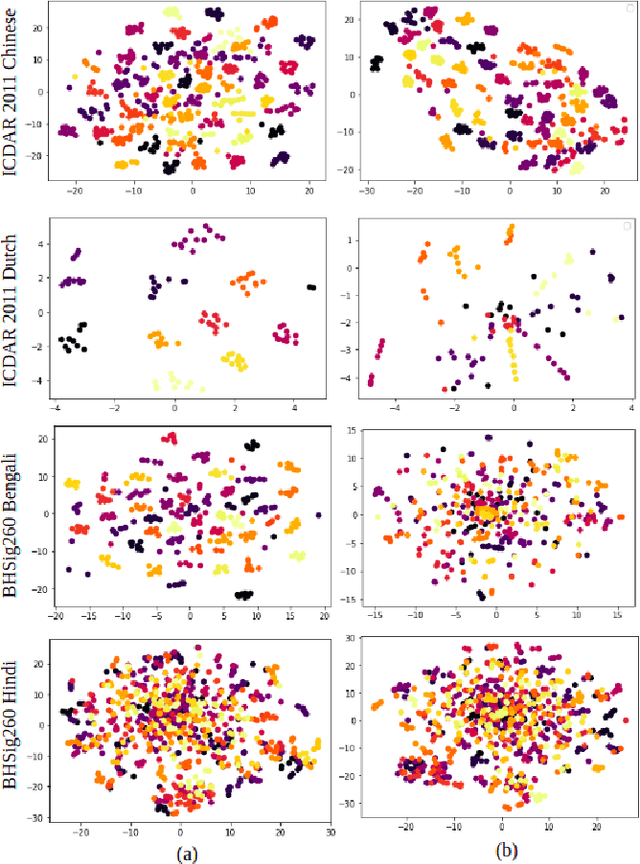
Decorrelation-based Self-Supervised Visual Representation Learning for Writer Identification
Oct 02, 2024



Self-supervised learning has developed rapidly over the last decade and has been applied in many areas of computer vision. Decorrelation-based self-supervised pretraining has shown great promise among non-contrastive algorithms, yielding performance at par with supervised and contrastive self-supervised baselines. In this work, we explore the decorrelation-based paradigm of self-supervised learning and apply the same to learning disentangled stroke features for writer identification. Here we propose a modified formulation of the decorrelation-based framework named SWIS which was proposed for signature verification by standardizing the features along each dimension on top of the existing framework. We show that the proposed framework outperforms the contemporary self-supervised learning framework on the writer identification benchmark and also outperforms several supervised methods as well. To the best of our knowledge, this work is the first of its kind to apply self-supervised learning for learning representations for writer verification tasks.
Correlation Weighted Prototype-based Self-Supervised One-Shot Segmentation of Medical Images
Aug 12, 2024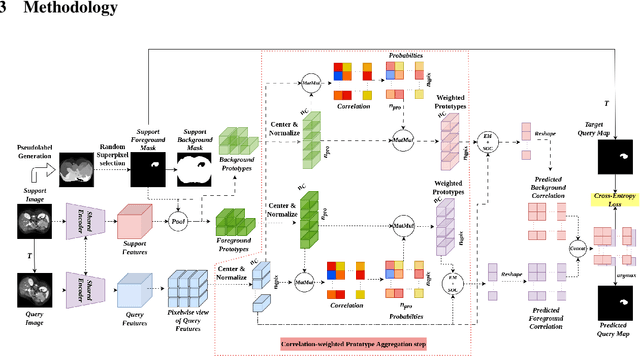

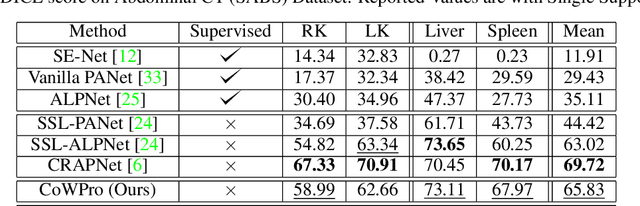
Medical image segmentation is one of the domains where sufficient annotated data is not available. This necessitates the application of low-data frameworks like few-shot learning. Contemporary prototype-based frameworks often do not account for the variation in features within the support and query images, giving rise to a large variance in prototype alignment. In this work, we adopt a prototype-based self-supervised one-way one-shot learning framework using pseudo-labels generated from superpixels to learn the semantic segmentation task itself. We use a correlation-based probability score to generate a dynamic prototype for each query pixel from the bag of prototypes obtained from the support feature map. This weighting scheme helps to give a higher weightage to contextually related prototypes. We also propose a quadrant masking strategy in the downstream segmentation task by utilizing prior domain information to discard unwanted false positives. We present extensive experimentations and evaluations on abdominal CT and MR datasets to show that the proposed simple but potent framework performs at par with the state-of-the-art methods.
DySTreSS: Dynamically Scaled Temperature in Self-Supervised Contrastive Learning
Aug 02, 2023In contemporary self-supervised contrastive algorithms like SimCLR, MoCo, etc., the task of balancing attraction between two semantically similar samples and repulsion between two samples from different classes is primarily affected by the presence of hard negative samples. While the InfoNCE loss has been shown to impose penalties based on hardness, the temperature hyper-parameter is the key to regulating the penalties and the trade-off between uniformity and tolerance. In this work, we focus our attention to improve the performance of InfoNCE loss in SSL by studying the effect of temperature hyper-parameter values. We propose a cosine similarity-dependent temperature scaling function to effectively optimize the distribution of the samples in the feature space. We further analyze the uniformity and tolerance metrics to investigate the optimal regions in the cosine similarity space for better optimization. Additionally, we offer a comprehensive examination of the behavior of local and global structures in the feature space throughout the pre-training phase, as the temperature varies. Experimental evidence shows that the proposed framework outperforms or is at par with the contrastive loss-based SSL algorithms. We believe our work (DySTreSS) on temperature scaling in SSL provides a foundation for future research in contrastive learning.
SelfDocSeg: A Self-Supervised vision-based Approach towards Document Segmentation
May 02, 2023Document layout analysis is a known problem to the documents research community and has been vastly explored yielding a multitude of solutions ranging from text mining, and recognition to graph-based representation, visual feature extraction, etc. However, most of the existing works have ignored the crucial fact regarding the scarcity of labeled data. With growing internet connectivity to personal life, an enormous amount of documents had been available in the public domain and thus making data annotation a tedious task. We address this challenge using self-supervision and unlike, the few existing self-supervised document segmentation approaches which use text mining and textual labels, we use a complete vision-based approach in pre-training without any ground-truth label or its derivative. Instead, we generate pseudo-layouts from the document images to pre-train an image encoder to learn the document object representation and localization in a self-supervised framework before fine-tuning it with an object detection model. We show that our pipeline sets a new benchmark in this context and performs at par with the existing methods and the supervised counterparts, if not outperforms. The code is made publicly available at: https://github.com/MaitySubhajit/SelfDocSeg
BYOLMed3D: Self-Supervised Representation Learning of Medical Videos using Gradient Accumulation Assisted 3D BYOL Framework
Jul 31, 2022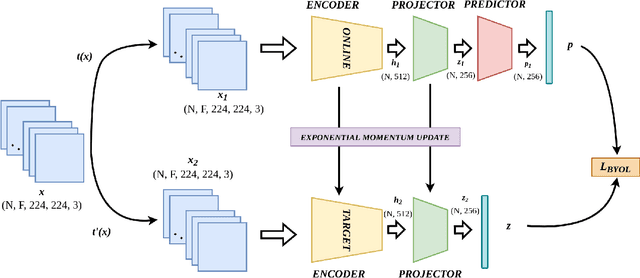

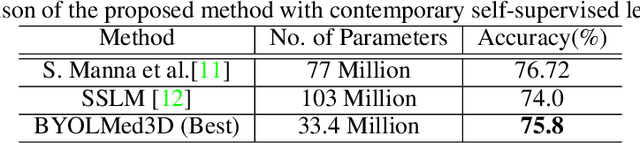

Applications on Medical Image Analysis suffer from acute shortage of large volume of data properly annotated by medical experts. Supervised Learning algorithms require a large volumes of balanced data to learn robust representations. Often supervised learning algorithms require various techniques to deal with imbalanced data. Self-supervised learning algorithms on the other hand are robust to imbalance in the data and are capable of learning robust representations. In this work, we train a 3D BYOL self-supervised model using gradient accumulation technique to deal with the large number of samples in a batch generally required in a self-supervised algorithm. To the best of our knowledge, this work is one of the first of its kind in this domain. We compare the results obtained through our experiments in the downstream task of ACL Tear Injury detection with the contemporary self-supervised pre-training methods and also with ResNet3D-18 initialized with the Kinetics-400 pre-trained weights. From the downstream task experiments, it is evident that the proposed framework outperforms the existing baselines.
SWIS: Self-Supervised Representation Learning For Writer Independent Offline Signature Verification
Feb 26, 2022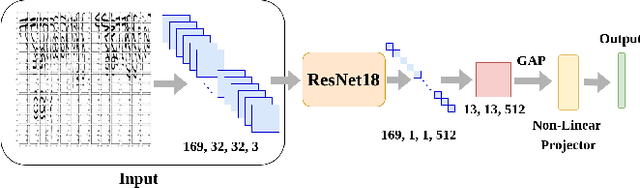


Writer independent offline signature verification is one of the most challenging tasks in pattern recognition as there is often a scarcity of training data. To handle such data scarcity problem, in this paper, we propose a novel self-supervised learning (SSL) framework for writer independent offline signature verification. To our knowledge, this is the first attempt to utilize self-supervised setting for the signature verification task. The objective of self-supervised representation learning from the signature images is achieved by minimizing the cross-covariance between two random variables belonging to different feature directions and ensuring a positive cross-covariance between the random variables denoting the same feature direction. This ensures that the features are decorrelated linearly and the redundant information is discarded. Through experimental results on different data sets, we obtained encouraging results.
SURDS: Self-Supervised Attention-guided Reconstruction and Dual Triplet Loss for Writer Independent Offline Signature Verification
Jan 25, 2022

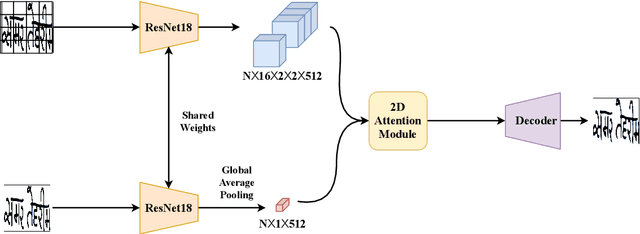

Offline Signature Verification (OSV) is a fundamental biometric task across various forensic, commercial and legal applications. The underlying task at hand is to carefully model fine-grained features of the signatures to distinguish between genuine and forged ones, which differ only in minute deformities. This makes OSV more challenging compared to other verification problems. In this work, we propose a two-stage deep learning framework that leverages self-supervised representation learning as well as metric learning for writer-independent OSV. First, we train an image reconstruction network using an encoder-decoder architecture that is augmented by a 2D spatial attention mechanism using signature image patches. Next, the trained encoder backbone is fine-tuned with a projector head using a supervised metric learning framework, whose objective is to optimize a novel dual triplet loss by sampling negative samples from both within the same writer class as well as from other writers. The intuition behind this is to ensure that a signature sample lies closer to its positive counterpart compared to negative samples from both intra-writer and cross-writer sets. This results in robust discriminative learning of the embedding space. To the best of our knowledge, this is the first work of using self-supervised learning frameworks for OSV. The proposed two-stage framework has been evaluated on two publicly available offline signature datasets and compared with various state-of-the-art methods. It is noted that the proposed method provided promising results outperforming several existing pieces of work.
MIO : Mutual Information Optimization using Self-Supervised Binary Contrastive Learning
Nov 24, 2021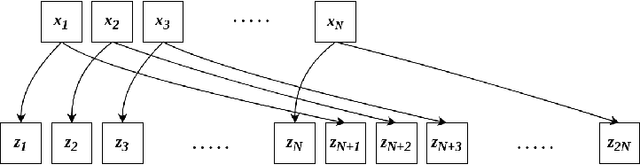
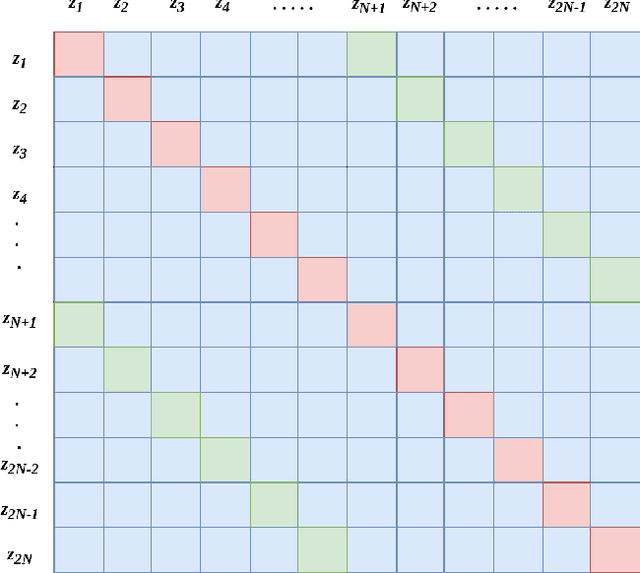
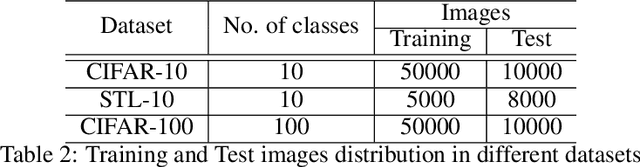
Self-supervised contrastive learning is one of the domains which has progressed rapidly over the last few years. Most of the state-of-the-art self-supervised algorithms use a large number of negative samples, momentum updates, specific architectural modifications, or extensive training to learn good representations. Such arrangements make the overall training process complex and challenging to realize analytically. In this paper, we propose a mutual information optimization based loss function for contrastive learning where we model contrastive learning into a binary classification problem to predict if a pair is positive or not. This formulation not only helps us to track the problem mathematically but also helps us to outperform existing algorithms. Unlike the existing methods that only maximize the mutual information in a positive pair, the proposed loss function optimizes the mutual information in both positive and negative pairs. We also present a mathematical expression for the parameter gradients flowing into the projector and the displacement of the feature vectors in the feature space. This helps us to get a mathematical insight into the working principle of contrastive learning. An additive $L_2$ regularizer is also used to prevent diverging of the feature vectors and to improve performance. The proposed method outperforms the state-of-the-art algorithms on benchmark datasets like STL-10, CIFAR-10, CIFAR-100. After only 250 epochs of pre-training, the proposed model achieves the best accuracy of 85.44\%, 60.75\%, 56.81\% on CIFAR-10, STL-10, CIFAR-100 datasets, respectively.