 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSLM: Self-Supervised Learning for Medical Diagnosis from MR Video
Paper and Code

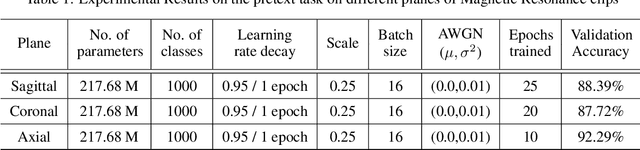
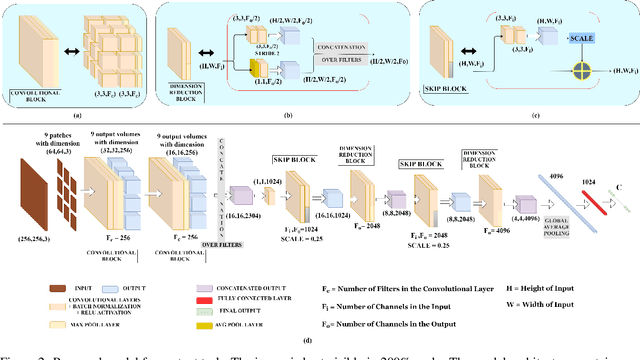
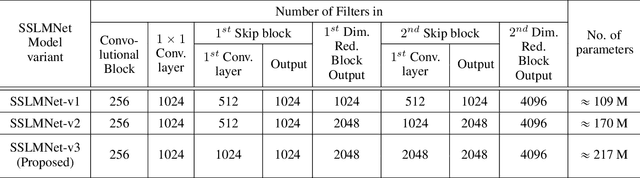
In medical image analysis, the cost of acquiring high-quality data and their annotation by experts is a barrier in many medical applications. Most of the techniques used are based on supervised learning framework and need a large amount of annotated data to achieve satisfactory performance. As an alternative, in this paper, we propose a self-supervised learning approach to learn the spatial anatomical representations from the frames of magnetic resonance (MR) video clips for the diagnosis of knee medical conditions. The pretext model learns meaningful spatial context-invariant representations. The downstream task in our paper is a class imbalanced multi-label classification. Different experiments show that the features learnt by the pretext model provide explainable performance in the downstream task. Moreover, the efficiency and reliability of the proposed pretext model in learning representations of minority classes without applying any strategy towards imbalance in the dataset can be seen from the results. To the best of our knowledge, this work is the first work of its kind in showing the effectiveness and reliability of self-supervised learning algorithms in class imbalanced multi-label classification tasks on MR video. The code for evaluation of the proposed work is available at https://github.com/sadimanna/sslm