 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRG-Font: Dynamic Reference-Guided Few-shot Font Generation via Contrastive Style-Content Disentanglement
Apr 15, 2026Few-shot Font Generation aims to generate stylistically consistent glyphs from a few reference glyphs. However, capturing complex font styles from a few exemplars remains challenging, and the existing methods often struggle to retain discernible local characteristics in generated samples. This paper introduces DRG-Font, a contrastive font generation strategy that learns complex glyph attributes by decomposing style and content embedding spaces. For optimal style supervision, the proposed architecture incorporates a Reference Selection (RS) Module to dynamically select the best style reference from an available pool of candidates. The network learns to decompose glyph attributes into style and shape priors through a Multi-scale Style Head Block (MSHB) and a Multi-scale Content Head Block (MCHB). For style adaptation, a Multi-Fusion Upsampling Block (MFUB) produces the target glyph by combining the reference style prior and target content prior. The proposed method demonstrates significant improvements over state-of-the-art approaches across multiple visual and analytical benchmarks.
SAGE-GAN: Towards Realistic and Robust Segmentation of Spatially Ordered Nanoparticles via Attention-Guided GANs
Apr 04, 2026Precise analysis of nanoparticles for characterization in electron microscopy images is essential for advancing nanomaterial development. Yet it remains challenging due to the time-consuming nature of manual methods and the shortcomings of traditional automated segmentation techniques, especially when dealing with complex shapes and imaging artifacts. While conventional methods yield promising results, they depend on a large volume of labeled training data, which is both difficult to acquire and highly time-consuming to generate. In order to overcome these challenges, we have developed a two-step solution: Firstly, our system learns to segment the key features of nanoparticles from a dataset of real images using a self-attention driven U-Net architecture that focuses on important physical and morphological details while ignoring background features and noise. Secondly, this trained Attention U-Net is embedded in a cycle-consistent generative adversarial network (CycleGAN) framework, inspired by the cGAN-Seg model introduced by Abzargar et al. This integration allows for the creation of highly realistic synthetic electron microscopy image-mask pairs that naturally reflect the structural patterns learned by the Attention U-Net. Consequently, the model can accurately detect features in a diverse array of real-world nanoparticle images and autonomously augment the training dataset without requiring human input. Cycle consistency enforces a direct correspondence between synthetic images and ground-truth masks, ensuring realistic features, which is crucial for accurate segmentation training.
LifWavNet: Lifting Wavelet-based Network for Non-contact ECG Reconstruction from Radar
Oct 31, 2025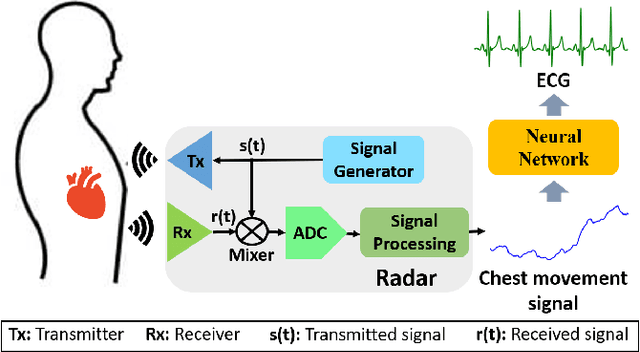
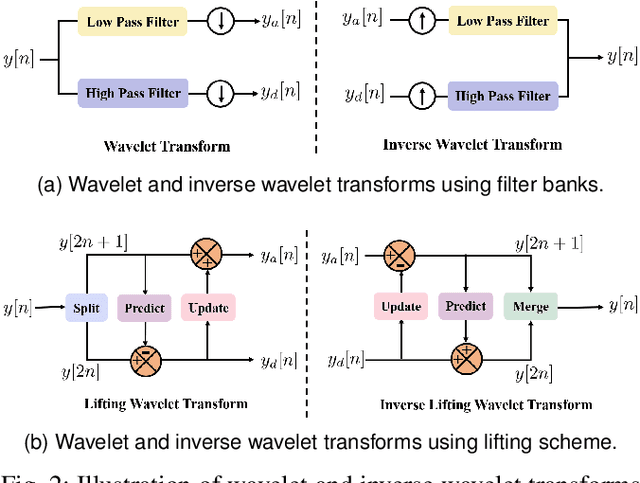
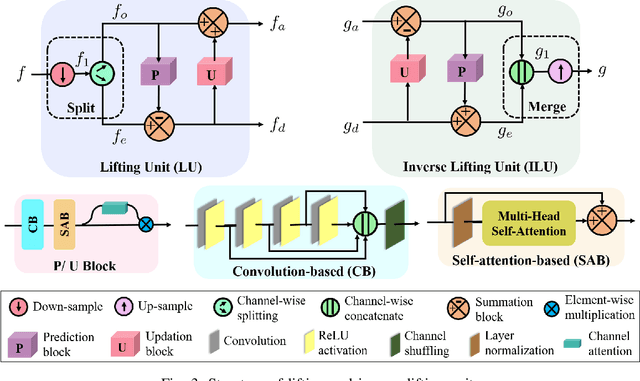
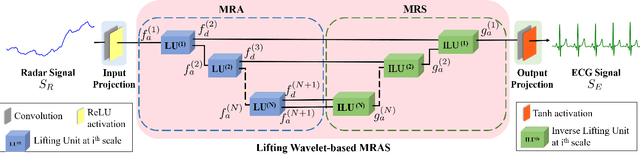
Non-contact electrocardiogram (ECG) reconstruction from radar signals offers a promising approach for unobtrusive cardiac monitoring. We present LifWavNet, a lifting wavelet network based on a multi-resolution analysis and synthesis (MRAS) model for radar-to-ECG reconstruction. Unlike prior models that use fixed wavelet approaches, LifWavNet employs learnable lifting wavelets with lifting and inverse lifting units to adaptively capture radar signal features and synthesize physiologically meaningful ECG waveforms. To improve reconstruction fidelity, we introduce a multi-resolution short-time Fourier transform (STFT) loss, that enforces consistency with the ground-truth ECG in both temporal and spectral domains. Evaluations on two public datasets demonstrate that LifWavNet outperforms state-of-the-art methods in ECG reconstruction and downstream vital sign estimation (heart rate and heart rate variability). Furthermore, intermediate feature visualization highlights the interpretability of multi-resolution decomposition and synthesis in radar-to-ECG reconstruction. These results establish LifWavNet as a robust framework for radar-based non-contact ECG measurement.
F-ANcGAN: An Attention-Enhanced Cycle Consistent Generative Adversarial Architecture for Synthetic Image Generation of Nanoparticles
May 23, 2025Nanomaterial research is becoming a vital area for energy, medicine, and materials science, and accurate analysis of the nanoparticle topology is essential to determine their properties. Unfortunately, the lack of high-quality annotated datasets drastically hinders the creation of strong segmentation models for nanoscale imaging. To alleviate this problem, we introduce F-ANcGAN, an attention-enhanced cycle consistent generative adversarial system that can be trained using a limited number of data samples and generates realistic scanning electron microscopy (SEM) images directly from segmentation maps. Our model uses a Style U-Net generator and a U-Net segmentation network equipped with self-attention to capture structural relationships and applies augmentation methods to increase the variety of the dataset. The architecture reached a raw FID score of 17.65 for TiO$_2$ dataset generation, with a further reduction in FID score to nearly 10.39 by using efficient post-processing techniques. By facilitating scalable high-fidelity synthetic dataset generation, our approach can improve the effectiveness of downstream segmentation task training, overcoming severe data shortage issues in nanoparticle analysis, thus extending its applications to resource-limited fields.
Federated Self-Supervised Learning for One-Shot Cross-Modal and Cross-Imaging Technique Segmentation
Mar 30, 2025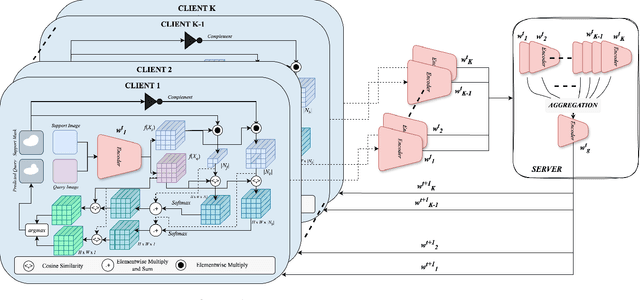



Decentralized federated learning enables learning of data representations from multiple sources without compromising the privacy of the clients. In applications like medical image segmentation, where obtaining a large annotated dataset from a single source is a distressing problem, federated self-supervised learning can provide some solace. In this work, we push the limits further by exploring a federated self-supervised one-shot segmentation task representing a more data-scarce scenario. We adopt a pre-existing self-supervised few-shot segmentation framework CoWPro and adapt it to the federated learning scenario. To the best of our knowledge, this work is the first to attempt a self-supervised few-shot segmentation task in the federated learning domain. Moreover, we consider the clients to be constituted of data from different modalities and imaging techniques like MR or CT, which makes the problem even harder. Additionally, we reinforce and improve the baseline CoWPro method using a fused dice loss which shows considerable improvement in performance over the baseline CoWPro. Finally, we evaluate this novel framework on a completely unseen held-out part of the local client dataset. We observe that the proposed framework can achieve performance at par or better than the FedAvg version of the CoWPro framework on the held-out validation dataset.
SSNet: Saliency Prior and State Space Model-based Network for Salient Object Detection in RGB-D Images
Mar 04, 2025
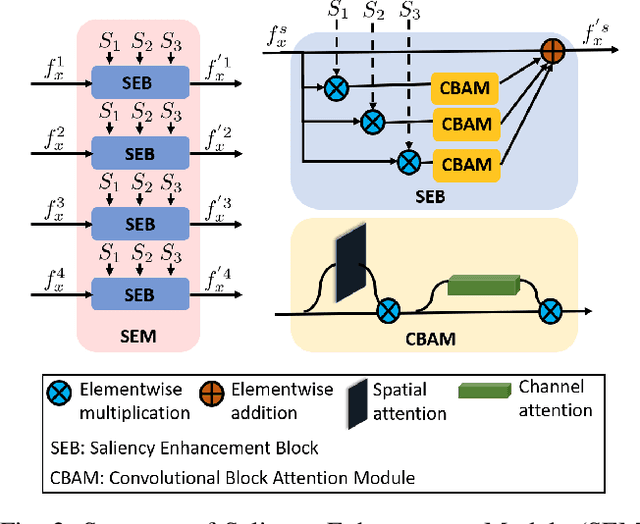
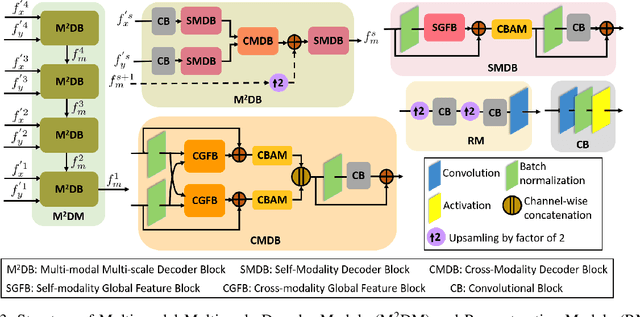
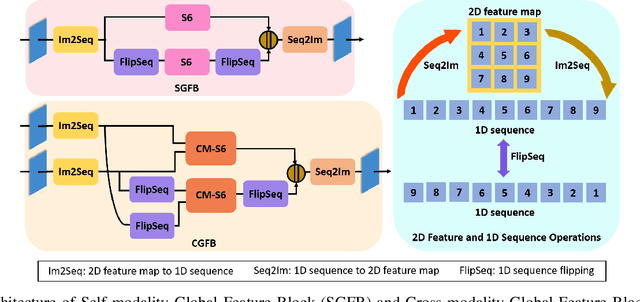
Salient object detection (SOD) in RGB-D images is an essential task in computer vision, enabling applications in scene understanding, robotics, and augmented reality. However, existing methods struggle to capture global dependency across modalities, lack comprehensive saliency priors from both RGB and depth data, and are ineffective in handling low-quality depth maps. To address these challenges, we propose SSNet, a saliency-prior and state space model (SSM)-based network for the RGB-D SOD task. Unlike existing convolution- or transformer-based approaches, SSNet introduces an SSM-based multi-modal multi-scale decoder module to efficiently capture both intra- and inter-modal global dependency with linear complexity. Specifically, we propose a cross-modal selective scan SSM (CM-S6) mechanism, which effectively captures global dependency between different modalities. Furthermore, we introduce a saliency enhancement module (SEM) that integrates three saliency priors with deep features to refine feature representation and improve the localization of salient objects. To further address the issue of low-quality depth maps, we propose an adaptive contrast enhancement technique that dynamically refines depth maps, making them more suitable for the RGB-D SOD task. Extensive quantitative and qualitative experiments on seven benchmark datasets demonstrate that SSNet outperforms state-of-the-art methods.
Exploring Mutual Cross-Modal Attention for Context-Aware Human Affordance Generation
Feb 19, 2025



Human affordance learning investigates contextually relevant novel pose prediction such that the estimated pose represents a valid human action within the scene. While the task is fundamental to machine perception and automated interactive navigation agents, the exponentially large number of probable pose and action variations make the problem challenging and non-trivial. However, the existing datasets and methods for human affordance prediction in 2D scenes are significantly limited in the literature. In this paper, we propose a novel cross-attention mechanism to encode the scene context for affordance prediction by mutually attending spatial feature maps from two different modalities. The proposed method is disentangled among individual subtasks to efficiently reduce the problem complexity. First, we sample a probable location for a person within the scene using a variational autoencoder (VAE) conditioned on the global scene context encoding. Next, we predict a potential pose template from a set of existing human pose candidates using a classifier on the local context encoding around the predicted location. In the subsequent steps, we use two VAEs to sample the scale and deformation parameters for the predicted pose template by conditioning on the local context and template class. Our experiments show significant improvements over the previous baseline of human affordance injection into complex 2D scenes.
d-Sketch: Improving Visual Fidelity of Sketch-to-Image Translation with Pretrained Latent Diffusion Models without Retraining
Feb 19, 2025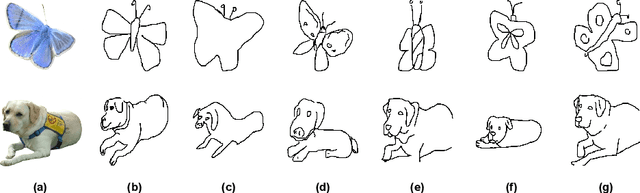
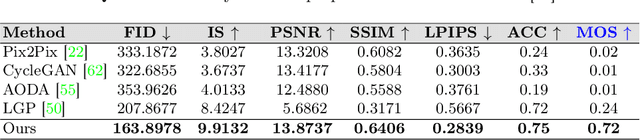

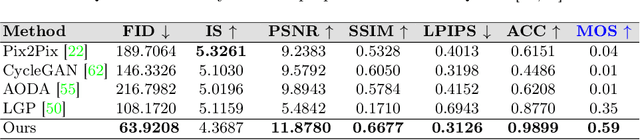
Structural guidance in an image-to-image translation allows intricate control over the shapes of synthesized images. Generating high-quality realistic images from user-specified rough hand-drawn sketches is one such task that aims to impose a structural constraint on the conditional generation process. While the premise is intriguing for numerous use cases of content creation and academic research, the problem becomes fundamentally challenging due to substantial ambiguities in freehand sketches. Furthermore, balancing the trade-off between shape consistency and realistic generation contributes to additional complexity in the process. Existing approaches based on Generative Adversarial Networks (GANs) generally utilize conditional GANs or GAN inversions, often requiring application-specific data and optimization objectives. The recent introduction of Denoising Diffusion Probabilistic Models (DDPMs) achieves a generational leap for low-level visual attributes in general image synthesis. However, directly retraining a large-scale diffusion model on a domain-specific subtask is often extremely difficult due to demanding computation costs and insufficient data. In this paper, we introduce a technique for sketch-to-image translation by exploiting the feature generalization capabilities of a large-scale diffusion model without retraining. In particular, we use a learnable lightweight mapping network to achieve latent feature translation from source to target domain. Experimental results demonstrate that the proposed method outperforms the existing techniques in qualitative and quantitative benchmarks, allowing high-resolution realistic image synthesis from rough hand-drawn sketches.
l0-Regularized Sparse Coding-based Interpretable Network for Multi-Modal Image Fusion
Nov 07, 2024

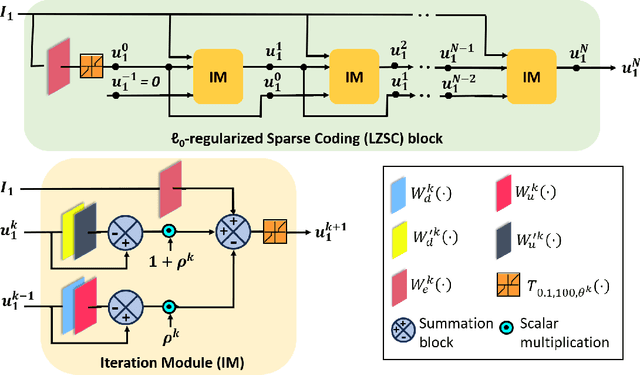
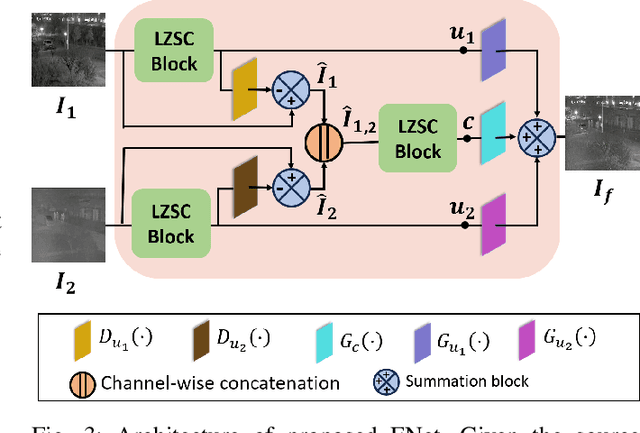
Multi-modal image fusion (MMIF) enhances the information content of the fused image by combining the unique as well as common features obtained from different modality sensor images, improving visualization, object detection, and many more tasks. In this work, we introduce an interpretable network for the MMIF task, named FNet, based on an l0-regularized multi-modal convolutional sparse coding (MCSC) model. Specifically, for solving the l0-regularized CSC problem, we develop an algorithm unrolling-based l0-regularized sparse coding (LZSC) block. Given different modality source images, FNet first separates the unique and common features from them using the LZSC block and then these features are combined to generate the final fused image. Additionally, we propose an l0-regularized MCSC model for the inverse fusion process. Based on this model, we introduce an interpretable inverse fusion network named IFNet, which is utilized during FNet's training. Extensive experiments show that FNet achieves high-quality fusion results across five different MMIF tasks. Furthermore, we show that FNet enhances downstream object detection in visible-thermal image pairs. We have also visualized the intermediate results of FNet, which demonstrates the good interpretability of our network.
Decorrelation-based Self-Supervised Visual Representation Learning for Writer Identification
Oct 02, 2024



Self-supervised learning has developed rapidly over the last decade and has been applied in many areas of computer vision. Decorrelation-based self-supervised pretraining has shown great promise among non-contrastive algorithms, yielding performance at par with supervised and contrastive self-supervised baselines. In this work, we explore the decorrelation-based paradigm of self-supervised learning and apply the same to learning disentangled stroke features for writer identification. Here we propose a modified formulation of the decorrelation-based framework named SWIS which was proposed for signature verification by standardizing the features along each dimension on top of the existing framework. We show that the proposed framework outperforms the contemporary self-supervised learning framework on the writer identification benchmark and also outperforms several supervised methods as well. To the best of our knowledge, this work is the first of its kind to apply self-supervised learning for learning representations for writer verification tasks.