 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSNet: Saliency Prior and State Space Model-based Network for Salient Object Detection in RGB-D Images
Paper and Code
Mar 04, 2025
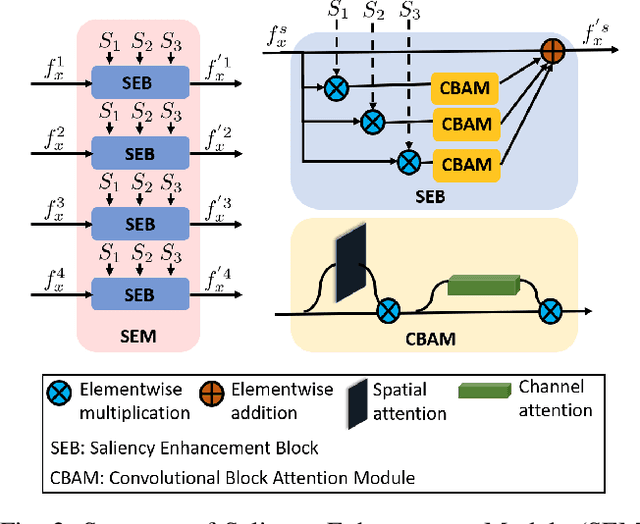
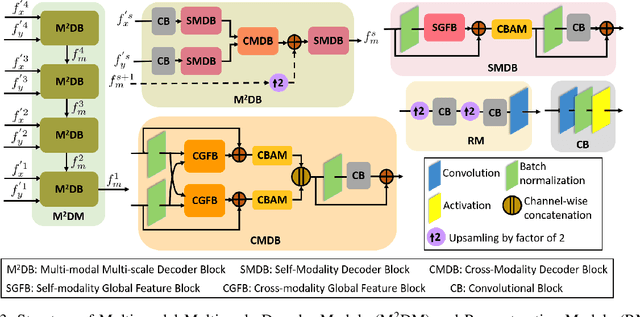
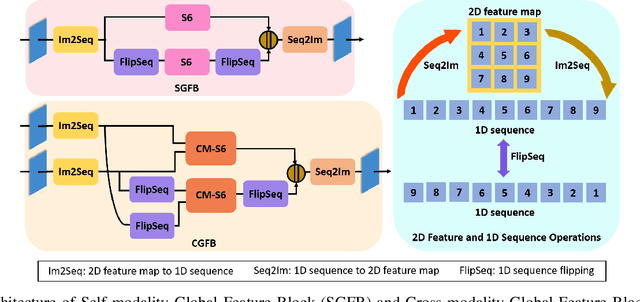
Salient object detection (SOD) in RGB-D images is an essential task in computer vision, enabling applications in scene understanding, robotics, and augmented reality. However, existing methods struggle to capture global dependency across modalities, lack comprehensive saliency priors from both RGB and depth data, and are ineffective in handling low-quality depth maps. To address these challenges, we propose SSNet, a saliency-prior and state space model (SSM)-based network for the RGB-D SOD task. Unlike existing convolution- or transformer-based approaches, SSNet introduces an SSM-based multi-modal multi-scale decoder module to efficiently capture both intra- and inter-modal global dependency with linear complexity. Specifically, we propose a cross-modal selective scan SSM (CM-S6) mechanism, which effectively captures global dependency between different modalities. Furthermore, we introduce a saliency enhancement module (SEM) that integrates three saliency priors with deep features to refine feature representation and improve the localization of salient objects. To further address the issue of low-quality depth maps, we propose an adaptive contrast enhancement technique that dynamically refines depth maps, making them more suitable for the RGB-D SOD task. Extensive quantitative and qualitative experiments on seven benchmark datasets demonstrate that SSNet outperforms state-of-the-art methods.