 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifWavNet: Lifting Wavelet-based Network for Non-contact ECG Reconstruction from Radar
Oct 31, 2025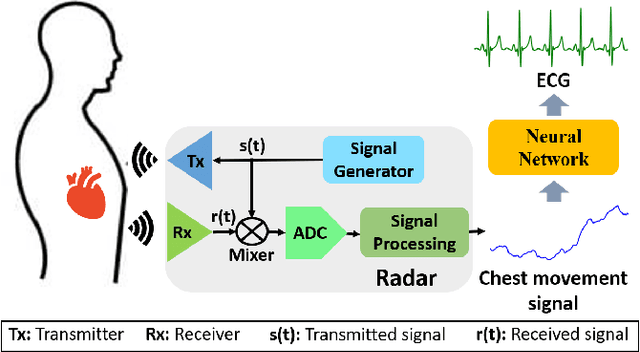
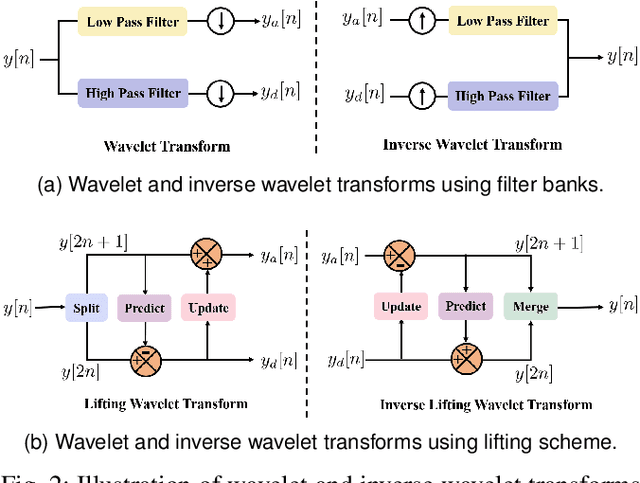
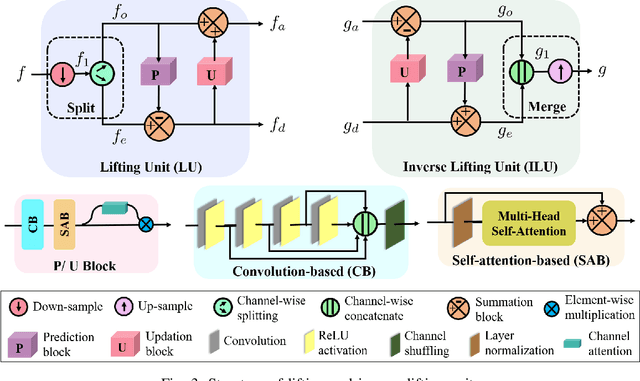
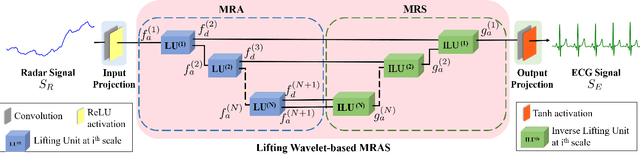
Non-contact electrocardiogram (ECG) reconstruction from radar signals offers a promising approach for unobtrusive cardiac monitoring. We present LifWavNet, a lifting wavelet network based on a multi-resolution analysis and synthesis (MRAS) model for radar-to-ECG reconstruction. Unlike prior models that use fixed wavelet approaches, LifWavNet employs learnable lifting wavelets with lifting and inverse lifting units to adaptively capture radar signal features and synthesize physiologically meaningful ECG waveforms. To improve reconstruction fidelity, we introduce a multi-resolution short-time Fourier transform (STFT) loss, that enforces consistency with the ground-truth ECG in both temporal and spectral domains. Evaluations on two public datasets demonstrate that LifWavNet outperforms state-of-the-art methods in ECG reconstruction and downstream vital sign estimation (heart rate and heart rate variability). Furthermore, intermediate feature visualization highlights the interpretability of multi-resolution decomposition and synthesis in radar-to-ECG reconstruction. These results establish LifWavNet as a robust framework for radar-based non-contact ECG measurement.
INN-PAR: Invertible Neural Network for PPG to ABP Reconstruction
Sep 13, 2024Non-invasive and continuous blood pressure (BP) monitoring is essential for the early prevention of many cardiovascular diseases. Estimating arterial blood pressure (ABP) from photoplethysmography (PPG) has emerged as a promising solution. However, existing deep learning approaches for PPG-to-ABP reconstruction (PAR) encounter certain information loss, impacting the precision of the reconstructed signal. To overcome this limitation, we introduce an invertible neural network for PPG to ABP reconstruction (INN-PAR), which employs a series of invertible blocks to jointly learn the mapping between PPG and its gradient with the ABP signal and its gradient. INN-PAR efficiently captures both forward and inverse mappings simultaneously, thereby preventing information loss. By integrating signal gradients into the learning process, INN-PAR enhances the network's ability to capture essential high-frequency details, leading to more accurate signal reconstruction. Moreover, we propose a multi-scale convolution module (MSCM) within the invertible block, enabling the model to learn features across multiple scales effectively. We have experimented on two benchmark datasets, which show that INN-PAR significantly outperforms the state-of-the-art methods in both waveform reconstruction and BP measurement accuracy.
Artificial Intelligence Methods Based Hierarchical Classification of Frontotemporal Dementia to Improve Diagnostic Predictability
Apr 12, 2021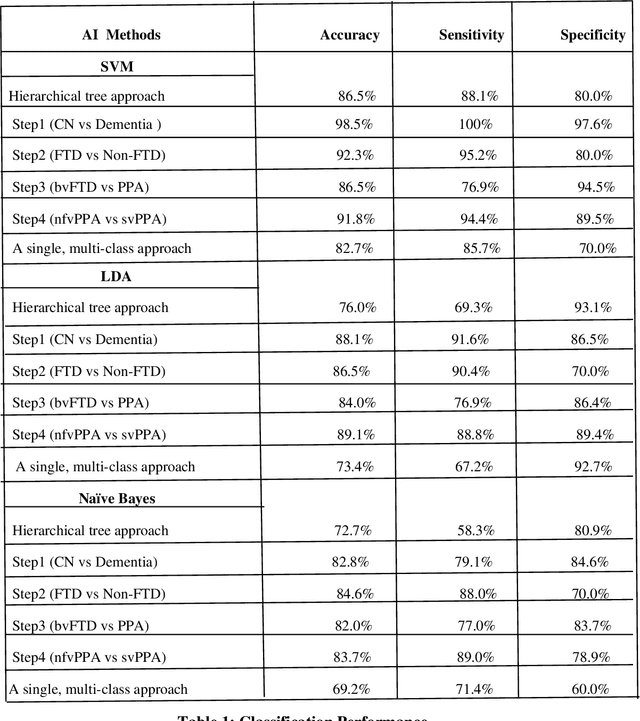
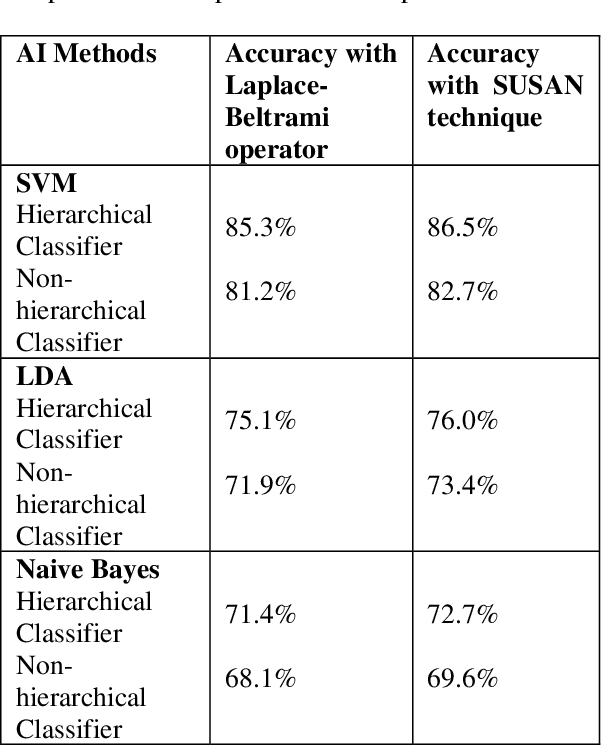
Patients with Frontotemporal Dementia (FTD) have impaired cognitive abilities, executive and behavioral traits, loss of language ability, and decreased memory capabilities. Based on the distinct patterns of cortical atrophy and symptoms, the FTD spectrum primarily includes three variants: behavioral variant FTD (bvFTD), non-fluent variant primary progressive aphasia (nfvPPA), and semantic variant primary progressive aphasia (svPPA). The purpose of this study is to classify MRI images of every single subject into one of the spectrums of the FTD in a hierarchical order by applying data-driven techniques of Artificial Intelligence (AI) on cortical thickness data. This data is computed by FreeSurfer software. We used the Smallest Univalue Segment Assimilating Nucleus (SUSAN) technique to minimize the noise in cortical thickness data. Specifically, we took 204 subjects from the frontotemporal lobar degeneration neuroimaging initiative (NIFTD) database to validate this approach, and each subject was diagnosed in one of the diagnostic categories (bvFTD, svPPA, nfvPPA and cognitively normal). Our proposed automated classification model yielded classification accuracy of 86.5, 76, and 72.7 with support vector machine (SVM), linear discriminant analysis (LDA), and Naive Bayes methods, respectively, in 10-fold cross-validation analysis, which is a significant improvement on a traditional single multi-class model with an accuracy of 82.7, 73.4, and 69.2.
The Indian Spontaneous Expression Database for Emotion Recognition
Jun 16, 2016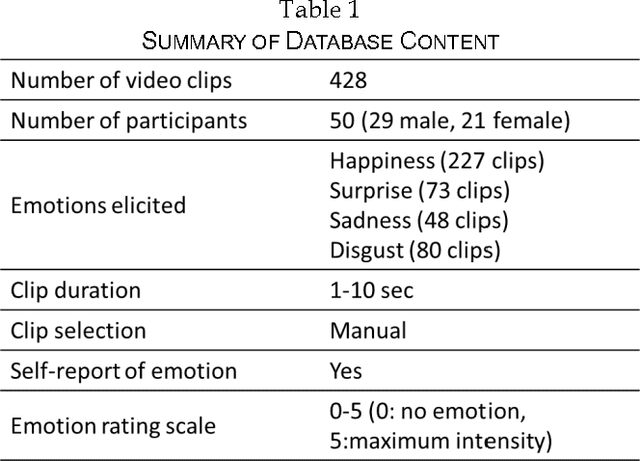
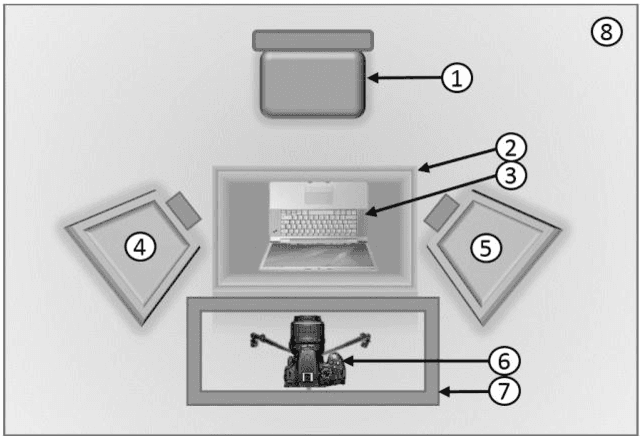
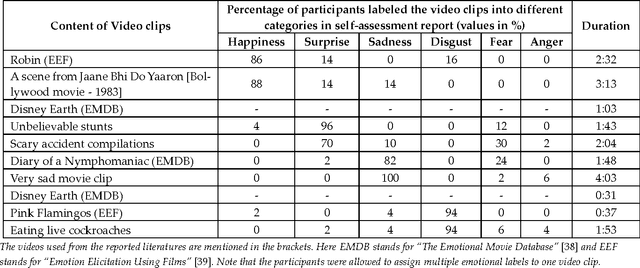
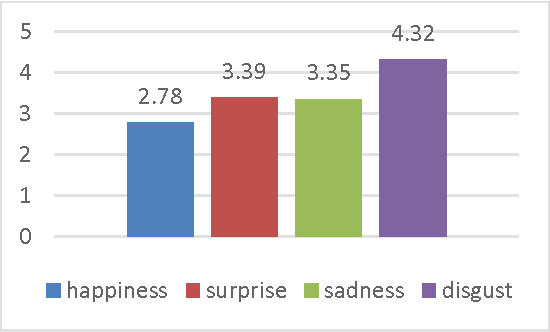
Automatic recognition of spontaneous facial expressions is a major challenge in the field of affective computing. Head rotation, face pose, illumination variation, occlusion etc. are the attributes that increase the complexity of recognition of spontaneous expressions in practical applications. Effective recognition of expressions depends significantly on the quality of the database used. Most well-known facial expression databases consist of posed expressions. However, currently there is a huge demand for spontaneous expression databases for the pragmatic implementation of the facial expression recognition algorithms. In this paper, we propose and establish a new facial expression database containing spontaneous expressions of both male and female participants of Indian origin. The database consists of 428 segmented video clips of the spontaneous facial expressions of 50 participants. In our experiment, emotions were induced among the participants by using emotional videos and simultaneously their self-ratings were collected for each experienced emotion. Facial expression clips were annotated carefully by four trained decoders, which were further validated by the nature of stimuli used and self-report of emotions. An extensive analysis was carried out on the database using several machine learning algorithms and the results are provided for future reference. Such a spontaneous database will help in the development and validation of algorithms for recognition of spontaneous expressions.