 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoTeS-Bank: Benchmarking Neural Transcription and Search for Scientific Notes Understanding
Apr 12, 2025Understanding and reasoning over academic handwritten notes remains a challenge in document AI, particularly for mathematical equations, diagrams, and scientific notations. Existing visual question answering (VQA) benchmarks focus on printed or structured handwritten text, limiting generalization to real-world note-taking. To address this, we introduce NoTeS-Bank, an evaluation benchmark for Neural Transcription and Search in note-based question answering. NoTeS-Bank comprises complex notes across multiple domains, requiring models to process unstructured and multimodal content. The benchmark defines two tasks: (1) Evidence-Based VQA, where models retrieve localized answers with bounding-box evidence, and (2) Open-Domain VQA, where models classify the domain before retrieving relevant documents and answers. Unlike classical Document VQA datasets relying on optical character recognition (OCR) and structured data, NoTeS-BANK demands vision-language fusion, retrieval, and multimodal reasoning. We benchmark state-of-the-art Vision-Language Models (VLMs) and retrieval frameworks, exposing structured transcription and reasoning limitations. NoTeS-Bank provides a rigorous evaluation with NDCG@5, MRR, Recall@K, IoU, and ANLS, establishing a new standard for visual document understanding and reasoning.
BigDocs: An Open and Permissively-Licensed Dataset for Training Multimodal Models on Document and Code Tasks
Dec 05, 2024



Multimodal AI has the potential to significantly enhance document-understanding tasks, such as processing receipts, understanding workflows, extracting data from documents, and summarizing reports. Code generation tasks that require long-structured outputs can also be enhanced by multimodality. Despite this, their use in commercial applications is often limited due to limited access to training data and restrictive licensing, which hinders open access. To address these limitations, we introduce BigDocs-7.5M, a high-quality, open-access dataset comprising 7.5 million multimodal documents across 30 tasks. We use an efficient data curation process to ensure our data is high-quality and license-permissive. Our process emphasizes accountability, responsibility, and transparency through filtering rules, traceable metadata, and careful content analysis. Additionally, we introduce BigDocs-Bench, a benchmark suite with 10 novel tasks where we create datasets that reflect real-world use cases involving reasoning over Graphical User Interfaces (GUI) and code generation from images. Our experiments show that training with BigDocs-Bench improves average performance up to 25.8% over closed-source GPT-4o in document reasoning and structured output tasks such as Screenshot2HTML or Image2Latex generation. Finally, human evaluations showed a preference for outputs from models trained on BigDocs over GPT-4o. This suggests that BigDocs can help both academics and the open-source community utilize and improve AI tools to enhance multimodal capabilities and document reasoning. The project is hosted at https://bigdocs.github.io .
Recurrent Few-Shot model for Document Verification
Oct 03, 2024General-purpose ID, or travel, document image- and video-based verification systems have yet to achieve good enough performance to be considered a solved problem. There are several factors that negatively impact their performance, including low-resolution images and videos and a lack of sufficient data to train the models. This task is particularly challenging when dealing with unseen class of ID, or travel, documents. In this paper we address this task by proposing a recurrent-based model able to detect forged documents in a few-shot scenario. The recurrent architecture makes the model robust to document resolution variability. Moreover, the few-shot approach allow the model to perform well even for unseen class of documents. Preliminary results on the SIDTD and Findit datasets show good performance of this model for this task.
Towards Generative Class Prompt Learning for Few-shot Visual Recognition
Sep 03, 2024



Although foundational vision-language models (VLMs) have proven to be very successful for various semantic discrimination tasks, they still struggle to perform faithfully for fine-grained categorization. Moreover, foundational models trained on one domain do not generalize well on a different domain without fine-tuning. We attribute these to the limitations of the VLM's semantic representations and attempt to improve their fine-grained visual awareness using generative modeling. Specifically, we propose two novel methods: Generative Class Prompt Learning (GCPL) and Contrastive Multi-class Prompt Learning (CoMPLe). Utilizing text-to-image diffusion models, GCPL significantly improves the visio-linguistic synergy in class embeddings by conditioning on few-shot exemplars with learnable class prompts. CoMPLe builds on this foundation by introducing a contrastive learning component that encourages inter-class separation during the generative optimization process. Our empirical results demonstrate that such a generative class prompt learning approach substantially outperform existing methods, offering a better alternative to few shot image recognition challenges. The source code will be made available at: https://github.com/soumitri2001/GCPL.
FastTextSpotter: A High-Efficiency Transformer for Multilingual Scene Text Spotting
Aug 27, 2024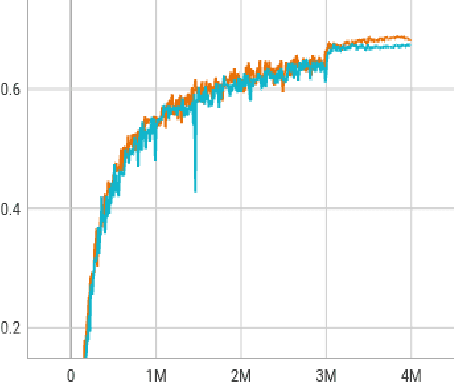
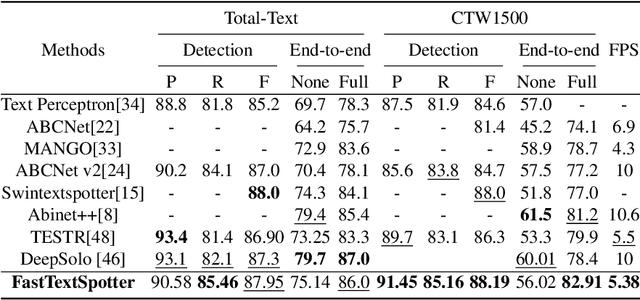
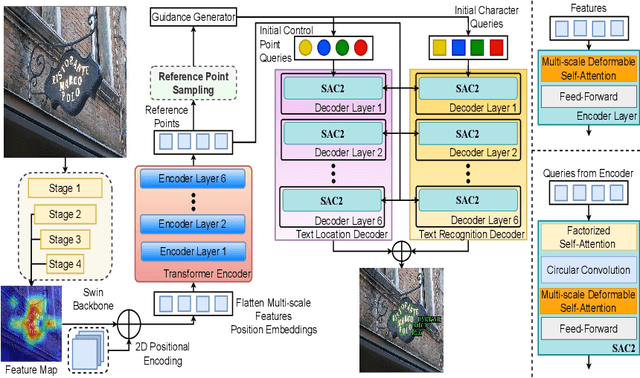
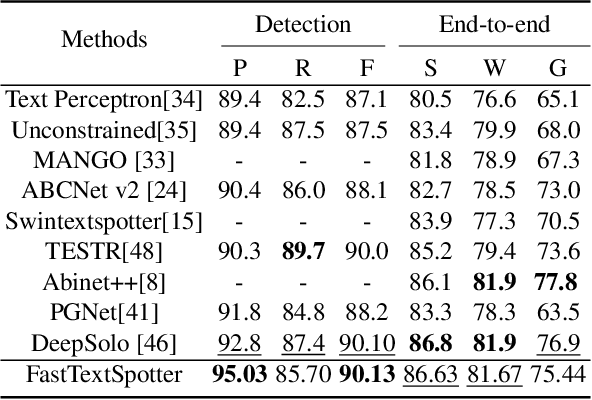
The proliferation of scene text in both structured and unstructured environments presents significant challenges in optical character recognition (OCR), necessitating more efficient and robust text spotting solutions. This paper presents FastTextSpotter, a framework that integrates a Swin Transformer visual backbone with a Transformer Encoder-Decoder architecture, enhanced by a novel, faster self-attention unit, SAC2, to improve processing speeds while maintaining accuracy. FastTextSpotter has been validated across multiple datasets, including ICDAR2015 for regular texts and CTW1500 and TotalText for arbitrary-shaped texts, benchmarking against current state-of-the-art models. Our results indicate that FastTextSpotter not only achieves superior accuracy in detecting and recognizing multilingual scene text (English and Vietnamese) but also improves model efficiency, thereby setting new benchmarks in the field. This study underscores the potential of advanced transformer architectures in improving the adaptability and speed of text spotting applications in diverse real-world settings. The dataset, code, and pre-trained models have been released in our Github.
DocSynthv2: A Practical Autoregressive Modeling for Document Generation
Jun 12, 2024



While the generation of document layouts has been extensively explored, comprehensive document generation encompassing both layout and content presents a more complex challenge. This paper delves into this advanced domain, proposing a novel approach called DocSynthv2 through the development of a simple yet effective autoregressive structured model. Our model, distinct in its integration of both layout and textual cues, marks a step beyond existing layout-generation approaches. By focusing on the relationship between the structural elements and the textual content within documents, we aim to generate cohesive and contextually relevant documents without any reliance on visual components. Through experimental studies on our curated benchmark for the new task, we demonstrate the ability of our model combining layout and textual information in enhancing the generation quality and relevance of documents, opening new pathways for research in document creation and automated design. Our findings emphasize the effectiveness of autoregressive models in handling complex document generation tasks.
DistilDoc: Knowledge Distillation for Visually-Rich Document Applications
Jun 12, 2024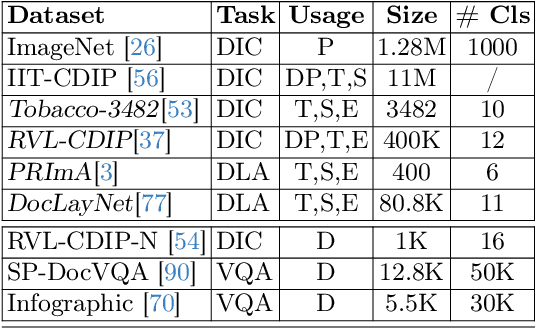
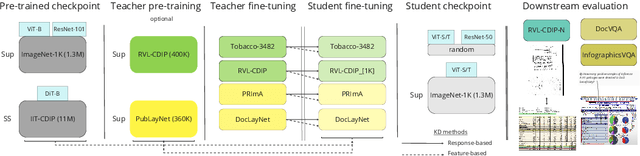
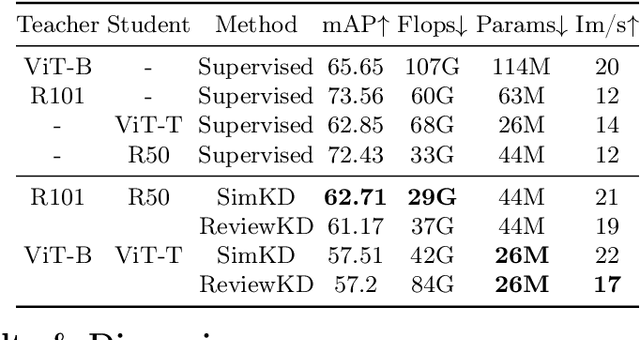
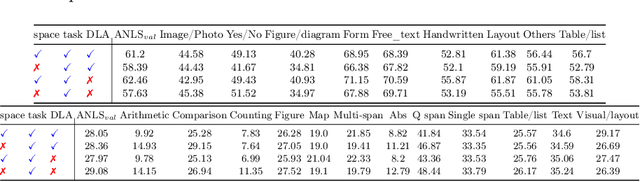
This work explores knowledge distillation (KD) for visually-rich document (VRD) applications such as document layout analysis (DLA) and document image classification (DIC). While VRD research is dependent on increasingly sophisticated and cumbersome models, the field has neglected to study efficiency via model compression. Here, we design a KD experimentation methodology for more lean, performant models on document understanding (DU) tasks that are integral within larger task pipelines. We carefully selected KD strategies (response-based, feature-based) for distilling knowledge to and from backbones with different architectures (ResNet, ViT, DiT) and capacities (base, small, tiny). We study what affects the teacher-student knowledge gap and find that some methods (tuned vanilla KD, MSE, SimKD with an apt projector) can consistently outperform supervised student training. Furthermore, we design downstream task setups to evaluate covariate shift and the robustness of distilled DLA models on zero-shot layout-aware document visual question answering (DocVQA). DLA-KD experiments result in a large mAP knowledge gap, which unpredictably translates to downstream robustness, accentuating the need to further explore how to efficiently obtain more semantic document layout awareness.
LayeredDoc: Domain Adaptive Document Restoration with a Layer Separation Approach
Jun 12, 2024



The rapid evolution of intelligent document processing systems demands robust solutions that adapt to diverse domains without extensive retraining. Traditional methods often falter with variable document types, leading to poor performance. To overcome these limitations, this paper introduces a text-graphic layer separation approach that enhances domain adaptability in document image restoration (DIR) systems. We propose LayeredDoc, which utilizes two layers of information: the first targets coarse-grained graphic components, while the second refines machine-printed textual content. This hierarchical DIR framework dynamically adjusts to the characteristics of the input document, facilitating effective domain adaptation. We evaluated our approach both qualitatively and quantitatively using a new real-world dataset, LayeredDocDB, developed for this study. Initially trained on a synthetically generated dataset, our model demonstrates strong generalization capabilities for the DIR task, offering a promising solution for handling variability in real-world data. Our code is accessible on GitHub.
SketchGPT: Autoregressive Modeling for Sketch Generation and Recognition
May 06, 2024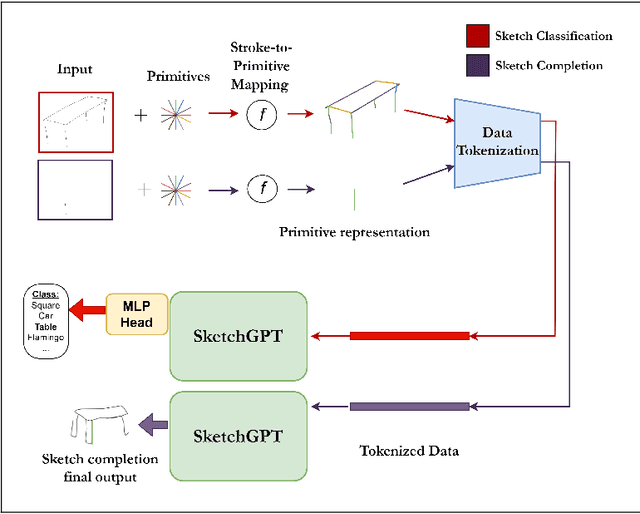
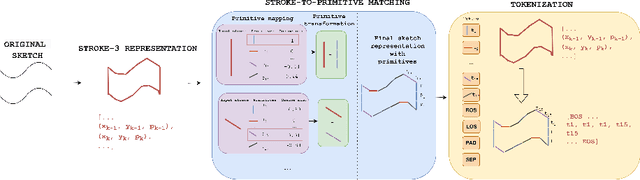
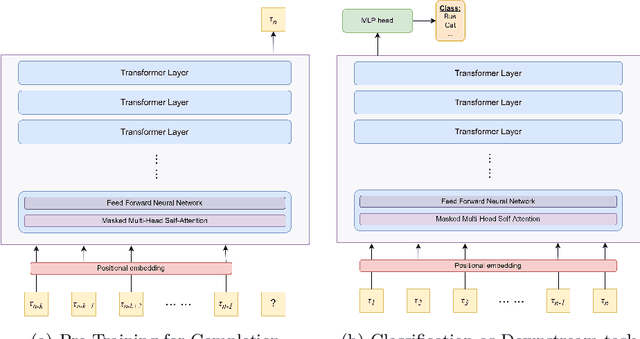

We present SketchGPT, a flexible framework that employs a sequence-to-sequence autoregressive model for sketch generation, and completion, and an interpretation case study for sketch recognition. By mapping complex sketches into simplified sequences of abstract primitives, our approach significantly streamlines the input for autoregressive modeling. SketchGPT leverages the next token prediction objective strategy to understand sketch patterns, facilitating the creation and completion of drawings and also categorizing them accurately. This proposed sketch representation strategy aids in overcoming existing challenges of autoregressive modeling for continuous stroke data, enabling smoother model training and competitive performance. Our findings exhibit SketchGPT's capability to generate a diverse variety of drawings by adding both qualitative and quantitative comparisons with existing state-of-the-art, along with a comprehensive human evaluation study. The code and pretrained models will be released on our official GitHub.
GeoContrastNet: Contrastive Key-Value Edge Learning for Language-Agnostic Document Understanding
May 06, 2024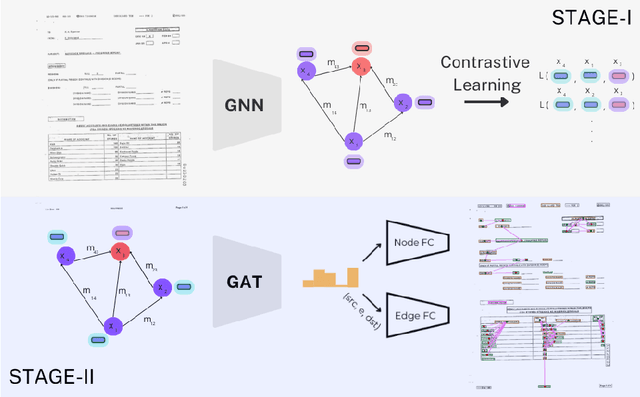
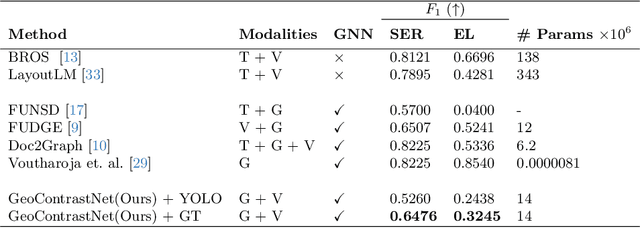
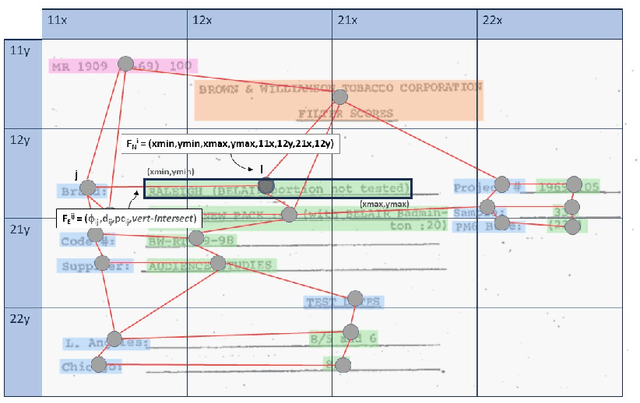

This paper presents GeoContrastNet, a language-agnostic framework to structured document understanding (DU) by integrating a contrastive learning objective with graph attention networks (GATs), emphasizing the significant role of geometric features. We propose a novel methodology that combines geometric edge features with visual features within an overall two-staged GAT-based framework, demonstrating promising results in both link prediction and semantic entity recognition performance. Our findings reveal that combining both geometric and visual features could match the capabilities of large DU models that rely heavily on Optical Character Recognition (OCR) features in terms of performance accuracy and efficiency. This approach underscores the critical importance of relational layout information between the named text entities in a semi-structured layout of a page. Specifically, our results highlight the model's proficiency in identifying key-value relationships within the FUNSD dataset for forms and also discovering the spatial relationships in table-structured layouts for RVLCDIP business invoices. Our code and pretrained models will be accessible on our official GitHub.