 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Few-Shot model for Document Verification
Oct 03, 2024General-purpose ID, or travel, document image- and video-based verification systems have yet to achieve good enough performance to be considered a solved problem. There are several factors that negatively impact their performance, including low-resolution images and videos and a lack of sufficient data to train the models. This task is particularly challenging when dealing with unseen class of ID, or travel, documents. In this paper we address this task by proposing a recurrent-based model able to detect forged documents in a few-shot scenario. The recurrent architecture makes the model robust to document resolution variability. Moreover, the few-shot approach allow the model to perform well even for unseen class of documents. Preliminary results on the SIDTD and Findit datasets show good performance of this model for this task.
GeoContrastNet: Contrastive Key-Value Edge Learning for Language-Agnostic Document Understanding
May 06, 2024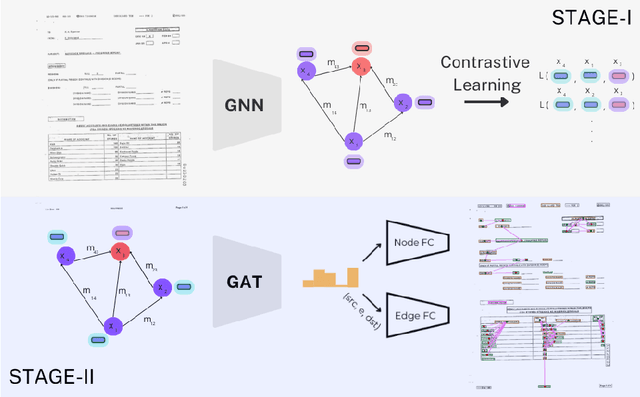
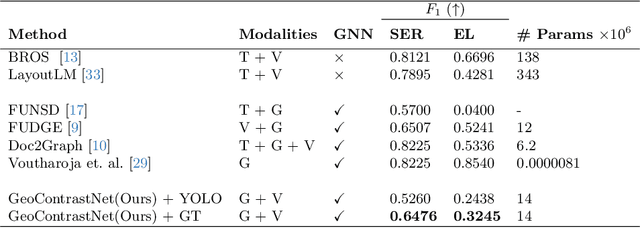
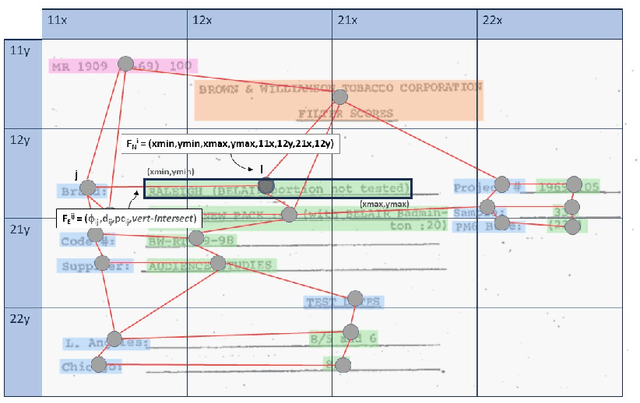

This paper presents GeoContrastNet, a language-agnostic framework to structured document understanding (DU) by integrating a contrastive learning objective with graph attention networks (GATs), emphasizing the significant role of geometric features. We propose a novel methodology that combines geometric edge features with visual features within an overall two-staged GAT-based framework, demonstrating promising results in both link prediction and semantic entity recognition performance. Our findings reveal that combining both geometric and visual features could match the capabilities of large DU models that rely heavily on Optical Character Recognition (OCR) features in terms of performance accuracy and efficiency. This approach underscores the critical importance of relational layout information between the named text entities in a semi-structured layout of a page. Specifically, our results highlight the model's proficiency in identifying key-value relationships within the FUNSD dataset for forms and also discovering the spatial relationships in table-structured layouts for RVLCDIP business invoices. Our code and pretrained models will be accessible on our official GitHub.
Synthetic dataset of ID and Travel Document
Jan 03, 2024



This paper presents a new synthetic dataset of ID and travel documents, called SIDTD. The SIDTD dataset is created to help training and evaluating forged ID documents detection systems. Such a dataset has become a necessity as ID documents contain personal information and a public dataset of real documents can not be released. Moreover, forged documents are scarce, compared to legit ones, and the way they are generated varies from one fraudster to another resulting in a class of high intra-variability. In this paper we trained state-of-the-art models on this dataset and we compare them to the performance achieved in larger, but private, datasets. The creation of this dataset will help to document image analysis community to progress in the task of ID document verification.