 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Model Checking: Graph-Based Inference of Visual Routines for Image Retrieval
Feb 19, 2026Information retrieval lies at the foundation of the modern digital industry. While natural language search has seen dramatic progress in recent years largely driven by embedding-based models and large-scale pretraining, the field still faces significant challenges. Specifically, queries that involve complex relationships, object compositions, or precise constraints such as identities, counts and proportions often remain unresolved or unreliable within current frameworks. In this paper, we propose a novel framework that integrates formal verification into deep learning-based image retrieval through a synergistic combination of graph-based verification methods and neural code generation. Our approach aims to support open-vocabulary natural language queries while producing results that are both trustworthy and verifiable. By grounding retrieval results in a system of formal reasoning, we move beyond the ambiguity and approximation that often characterize vector representations. Instead of accepting uncertainty as a given, our framework explicitly verifies each atomic truth in the user query against the retrieved content. This allows us to not only return matching results, but also to identify and mark which specific constraints are satisfied and which remain unmet, thereby offering a more transparent and accountable retrieval process while boosting the results of the most popular embedding-based approaches.
TaleDiffusion: Multi-Character Story Generation with Dialogue Rendering
Sep 04, 2025Text-to-story visualization is challenging due to the need for consistent interaction among multiple characters across frames. Existing methods struggle with character consistency, leading to artifact generation and inaccurate dialogue rendering, which results in disjointed storytelling. In response, we introduce TaleDiffusion, a novel framework for generating multi-character stories with an iterative process, maintaining character consistency, and accurate dialogue assignment via postprocessing. Given a story, we use a pre-trained LLM to generate per-frame descriptions, character details, and dialogues via in-context learning, followed by a bounded attention-based per-box mask technique to control character interactions and minimize artifacts. We then apply an identity-consistent self-attention mechanism to ensure character consistency across frames and region-aware cross-attention for precise object placement. Dialogues are also rendered as bubbles and assigned to characters via CLIPSeg. Experimental results demonstrate that TaleDiffusion outperforms existing methods in consistency, noise reduction, and dialogue rendering.
The OCR Quest for Generalization: Learning to recognize low-resource alphabets with model editing
Jun 07, 2025Achieving robustness in recognition systems across diverse domains is crucial for their practical utility. While ample data availability is usually assumed, low-resource languages, such as ancient manuscripts and non-western languages, tend to be kept out of the equations of massive pretraining and foundational techniques due to an under representation. In this work, we aim for building models which can generalize to new distributions of data, such as alphabets, faster than centralized fine-tune strategies. For doing so, we take advantage of the recent advancements in model editing to enhance the incorporation of unseen scripts (low-resource learning). In contrast to state-of-the-art meta-learning, we showcase the effectiveness of domain merging in sparse distributions of data, with agnosticity of its relation to the overall distribution or any other prototyping necessity. Even when using the same exact training data, our experiments showcase significant performance boosts in \textbf{transfer learning} to new alphabets and \textbf{out-of-domain evaluation} in challenging domain shifts, including historical ciphered texts and non-Latin scripts. This research contributes a novel approach into building models that can easily adopt under-represented alphabets and, therefore, enable document recognition to a wider set of contexts and cultures.
Towards Generative Class Prompt Learning for Few-shot Visual Recognition
Sep 03, 2024



Although foundational vision-language models (VLMs) have proven to be very successful for various semantic discrimination tasks, they still struggle to perform faithfully for fine-grained categorization. Moreover, foundational models trained on one domain do not generalize well on a different domain without fine-tuning. We attribute these to the limitations of the VLM's semantic representations and attempt to improve their fine-grained visual awareness using generative modeling. Specifically, we propose two novel methods: Generative Class Prompt Learning (GCPL) and Contrastive Multi-class Prompt Learning (CoMPLe). Utilizing text-to-image diffusion models, GCPL significantly improves the visio-linguistic synergy in class embeddings by conditioning on few-shot exemplars with learnable class prompts. CoMPLe builds on this foundation by introducing a contrastive learning component that encourages inter-class separation during the generative optimization process. Our empirical results demonstrate that such a generative class prompt learning approach substantially outperform existing methods, offering a better alternative to few shot image recognition challenges. The source code will be made available at: https://github.com/soumitri2001/GCPL.
FastTextSpotter: A High-Efficiency Transformer for Multilingual Scene Text Spotting
Aug 27, 2024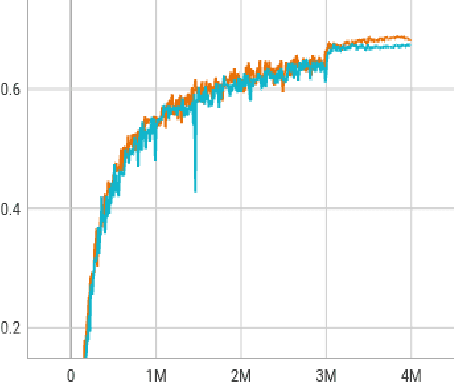
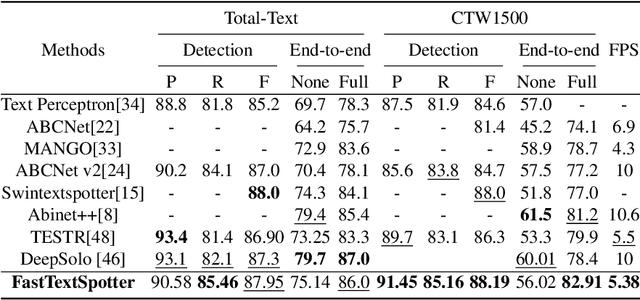
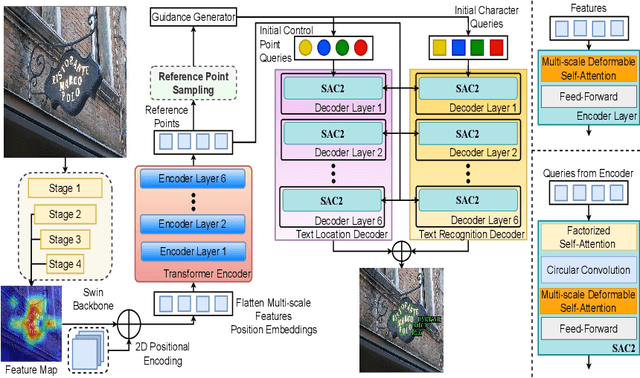
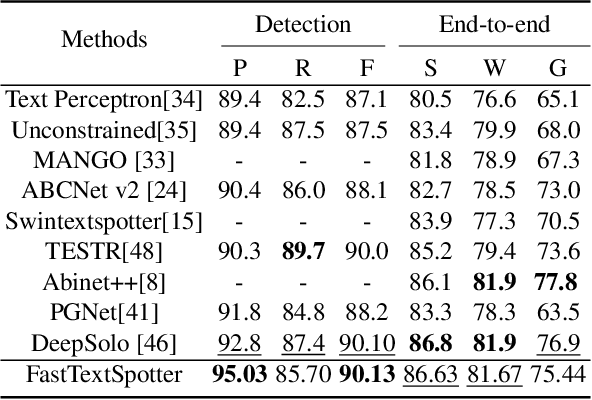
The proliferation of scene text in both structured and unstructured environments presents significant challenges in optical character recognition (OCR), necessitating more efficient and robust text spotting solutions. This paper presents FastTextSpotter, a framework that integrates a Swin Transformer visual backbone with a Transformer Encoder-Decoder architecture, enhanced by a novel, faster self-attention unit, SAC2, to improve processing speeds while maintaining accuracy. FastTextSpotter has been validated across multiple datasets, including ICDAR2015 for regular texts and CTW1500 and TotalText for arbitrary-shaped texts, benchmarking against current state-of-the-art models. Our results indicate that FastTextSpotter not only achieves superior accuracy in detecting and recognizing multilingual scene text (English and Vietnamese) but also improves model efficiency, thereby setting new benchmarks in the field. This study underscores the potential of advanced transformer architectures in improving the adaptability and speed of text spotting applications in diverse real-world settings. The dataset, code, and pre-trained models have been released in our Github.
LayeredDoc: Domain Adaptive Document Restoration with a Layer Separation Approach
Jun 12, 2024



The rapid evolution of intelligent document processing systems demands robust solutions that adapt to diverse domains without extensive retraining. Traditional methods often falter with variable document types, leading to poor performance. To overcome these limitations, this paper introduces a text-graphic layer separation approach that enhances domain adaptability in document image restoration (DIR) systems. We propose LayeredDoc, which utilizes two layers of information: the first targets coarse-grained graphic components, while the second refines machine-printed textual content. This hierarchical DIR framework dynamically adjusts to the characteristics of the input document, facilitating effective domain adaptation. We evaluated our approach both qualitatively and quantitatively using a new real-world dataset, LayeredDocDB, developed for this study. Initially trained on a synthetically generated dataset, our model demonstrates strong generalization capabilities for the DIR task, offering a promising solution for handling variability in real-world data. Our code is accessible on GitHub.
DocSynthv2: A Practical Autoregressive Modeling for Document Generation
Jun 12, 2024



While the generation of document layouts has been extensively explored, comprehensive document generation encompassing both layout and content presents a more complex challenge. This paper delves into this advanced domain, proposing a novel approach called DocSynthv2 through the development of a simple yet effective autoregressive structured model. Our model, distinct in its integration of both layout and textual cues, marks a step beyond existing layout-generation approaches. By focusing on the relationship between the structural elements and the textual content within documents, we aim to generate cohesive and contextually relevant documents without any reliance on visual components. Through experimental studies on our curated benchmark for the new task, we demonstrate the ability of our model combining layout and textual information in enhancing the generation quality and relevance of documents, opening new pathways for research in document creation and automated design. Our findings emphasize the effectiveness of autoregressive models in handling complex document generation tasks.
DistilDoc: Knowledge Distillation for Visually-Rich Document Applications
Jun 12, 2024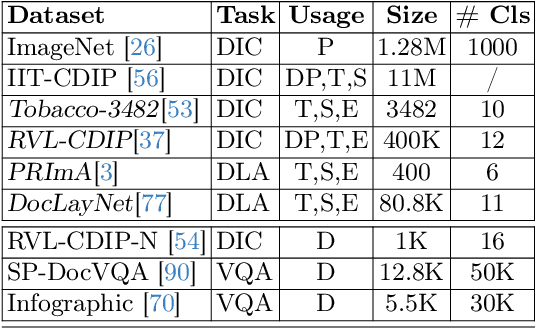
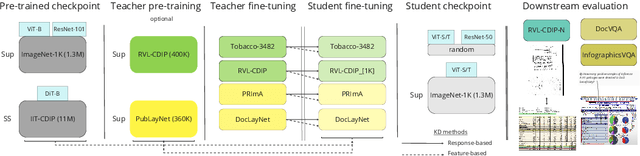
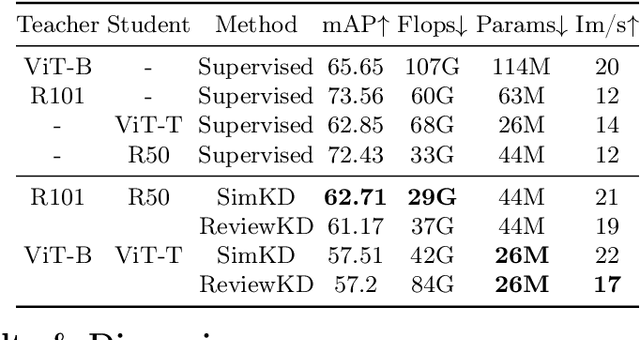
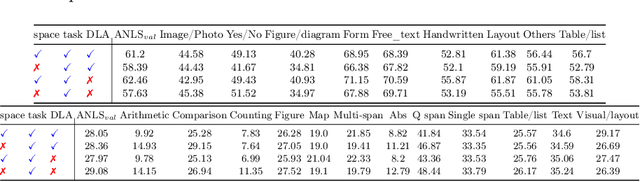
This work explores knowledge distillation (KD) for visually-rich document (VRD) applications such as document layout analysis (DLA) and document image classification (DIC). While VRD research is dependent on increasingly sophisticated and cumbersome models, the field has neglected to study efficiency via model compression. Here, we design a KD experimentation methodology for more lean, performant models on document understanding (DU) tasks that are integral within larger task pipelines. We carefully selected KD strategies (response-based, feature-based) for distilling knowledge to and from backbones with different architectures (ResNet, ViT, DiT) and capacities (base, small, tiny). We study what affects the teacher-student knowledge gap and find that some methods (tuned vanilla KD, MSE, SimKD with an apt projector) can consistently outperform supervised student training. Furthermore, we design downstream task setups to evaluate covariate shift and the robustness of distilled DLA models on zero-shot layout-aware document visual question answering (DocVQA). DLA-KD experiments result in a large mAP knowledge gap, which unpredictably translates to downstream robustness, accentuating the need to further explore how to efficiently obtain more semantic document layout awareness.
Fetch-A-Set: A Large-Scale OCR-Free Benchmark for Historical Document Retrieval
Jun 11, 2024



This paper introduces Fetch-A-Set (FAS), a comprehensive benchmark tailored for legislative historical document analysis systems, addressing the challenges of large-scale document retrieval in historical contexts. The benchmark comprises a vast repository of documents dating back to the XVII century, serving both as a training resource and an evaluation benchmark for retrieval systems. It fills a critical gap in the literature by focusing on complex extractive tasks within the domain of cultural heritage. The proposed benchmark tackles the multifaceted problem of historical document analysis, including text-to-image retrieval for queries and image-to-text topic extraction from document fragments, all while accommodating varying levels of document legibility. This benchmark aims to spur advancements in the field by providing baselines and data for the development and evaluation of robust historical document retrieval systems, particularly in scenarios characterized by wide historical spectrum.
SketchGPT: Autoregressive Modeling for Sketch Generation and Recognition
May 06, 2024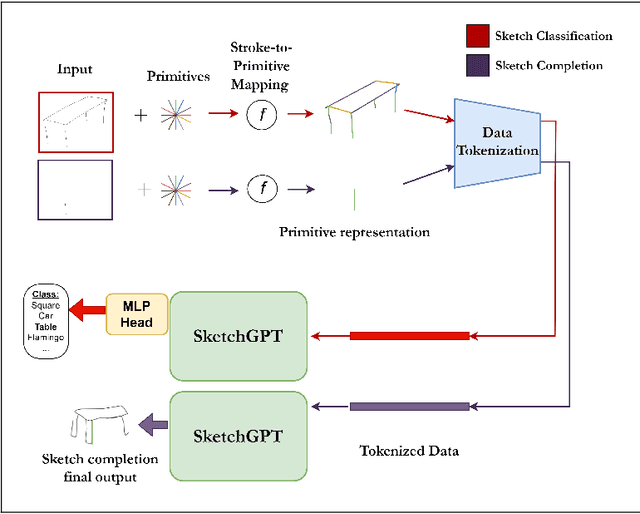
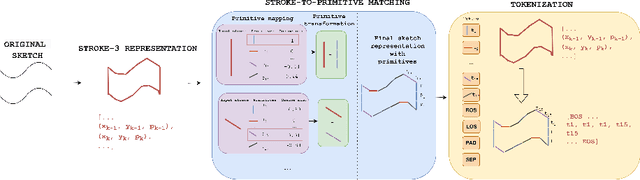
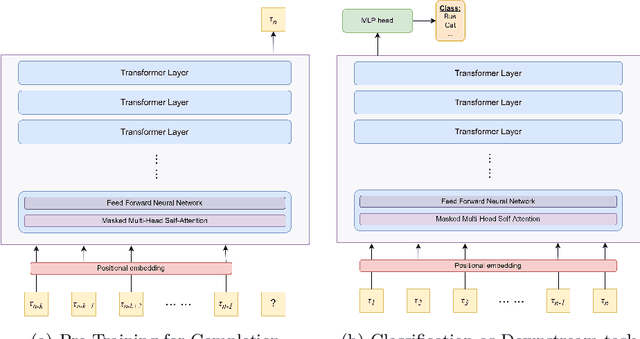

We present SketchGPT, a flexible framework that employs a sequence-to-sequence autoregressive model for sketch generation, and completion, and an interpretation case study for sketch recognition. By mapping complex sketches into simplified sequences of abstract primitives, our approach significantly streamlines the input for autoregressive modeling. SketchGPT leverages the next token prediction objective strategy to understand sketch patterns, facilitating the creation and completion of drawings and also categorizing them accurately. This proposed sketch representation strategy aids in overcoming existing challenges of autoregressive modeling for continuous stroke data, enabling smoother model training and competitive performance. Our findings exhibit SketchGPT's capability to generate a diverse variety of drawings by adding both qualitative and quantitative comparisons with existing state-of-the-art, along with a comprehensive human evaluation study. The code and pretrained models will be released on our official GitHub.