 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperience with Single Domain Generalization in Real World Medical Imaging Deployments
Jan 22, 2026A desirable property of any deployed artificial intelligence is generalization across domains, i.e. data generation distribution under a specific acquisition condition. In medical imagining applications the most coveted property for effective deployment is Single Domain Generalization (SDG), which addresses the challenge of training a model on a single domain to ensure it generalizes well to unseen target domains. In multi-center studies, differences in scanners and imaging protocols introduce domain shifts that exacerbate variability in rare class characteristics. This paper presents our experience on SDG in real life deployment for two exemplary medical imaging case studies on seizure onset zone detection using fMRI data, and stress electrocardiogram based coronary artery detection. Utilizing the commonly used application of diabetic retinopathy, we first demonstrate that state-of-the-art SDG techniques fail to achieve generalized performance across data domains. We then develop a generic expert knowledge integrated deep learning technique DL+EKE and instantiate it for the DR application and show that DL+EKE outperforms SOTA SDG methods on DR. We then deploy instances of DL+EKE technique on the two real world examples of stress ECG and resting state (rs)-fMRI and discuss issues faced with SDG techniques.
Detection of Deployment Operational Deviations for Safety and Security of AI-Enabled Human-Centric Cyber Physical Systems
Jan 08, 2026In recent years, Human-centric cyber-physical systems have increasingly involved artificial intelligence to enable knowledge extraction from sensor-collected data. Examples include medical monitoring and control systems, as well as autonomous cars. Such systems are intended to operate according to the protocols and guidelines for regular system operations. However, in many scenarios, such as closed-loop blood glucose control for Type 1 diabetics, self-driving cars, and monitoring systems for stroke diagnosis. The operations of such AI-enabled human-centric applications can expose them to cases for which their operational mode may be uncertain, for instance, resulting from the interactions with a human with the system. Such cases, in which the system is in uncertain conditions, can violate the system's safety and security requirements. This paper will discuss operational deviations that can lead these systems to operate in unknown conditions. We will then create a framework to evaluate different strategies for ensuring the safety and security of AI-enabled human-centric cyber-physical systems in operation deployment. Then, as an example, we show a personalized image-based novel technique for detecting the non-announcement of meals in closed-loop blood glucose control for Type 1 diabetics.
Personalized Model-Based Design of Human Centric AI enabled CPS for Long term usage
Jan 08, 2026Human centric critical systems are increasingly involving artificial intelligence to enable knowledge extraction from sensor collected data. Examples include medical monitoring and control systems, gesture based human computer interaction systems, and autonomous cars. Such systems are intended to operate for a long term potentially for a lifetime in many scenarios such as closed loop blood glucose control for Type 1 diabetics, self-driving cars, and monitoting systems for stroke diagnosis, and rehabilitation. Long term operation of such AI enabled human centric applications can expose them to corner cases for which their operation is may be uncertain. This can be due to many reasons such as inherent flaws in the design, limited resources for testing, inherent computational limitations of the testing methodology, or unknown use cases resulting from human interaction with the system. Such untested corner cases or cases for which the system performance is uncertain can lead to violations in the safety, sustainability, and security requirements of the system. In this paper, we analyze the existing techniques for safety, sustainability, and security analysis of an AI enabled human centric control system and discuss their limitations for testing the system for long term use in practice. We then propose personalized model based solutions for potentially eliminating such limitations.
XAI-MeD: Explainable Knowledge Guided Neuro-Symbolic Framework for Domain Generalization and Rare Class Detection in Medical Imaging
Jan 05, 2026Explainability domain generalization and rare class reliability are critical challenges in medical AI where deep models often fail under real world distribution shifts and exhibit bias against infrequent clinical conditions This paper introduces XAIMeD an explainable medical AI framework that integrates clinically accurate expert knowledge into deep learning through a unified neuro symbolic architecture XAIMeD is designed to improve robustness under distribution shift enhance rare class sensitivity and deliver transparent clinically aligned interpretations The framework encodes clinical expertise as logical connectives over atomic medical propositions transforming them into machine checkable class specific rules Their diagnostic utility is quantified through weighted feature satisfaction scores enabling a symbolic reasoning branch that complements neural predictions A confidence weighted fusion integrates symbolic and deep outputs while a Hunt inspired adaptive routing mechanism guided by Entropy Imbalance Gain EIG and Rare Class Gini mitigates class imbalance high intra class variability and uncertainty We evaluate XAIMeD across diverse modalities on four challenging tasks i Seizure Onset Zone SOZ localization from rs fMRI ii Diabetic Retinopathy grading across 6 multicenter datasets demonstrate substantial performance improvements including 6 percent gains in cross domain generalization and a 10 percent improved rare class F1 score far outperforming state of the art deep learning baselines Ablation studies confirm that the clinically grounded symbolic components act as effective regularizers ensuring robustness to distribution shifts XAIMeD thus provides a principled clinically faithful and interpretable approach to multimodal medical AI.
Enabling Physical AI at the Edge: Hardware-Accelerated Recovery of System Dynamics
Dec 29, 2025Physical AI at the edge -- enabling autonomous systems to understand and predict real-world dynamics in real time -- requires hardware-efficient learning and inference. Model recovery (MR), which identifies governing equations from sensor data, is a key primitive for safe and explainable monitoring in mission-critical autonomous systems operating under strict latency, compute, and power constraints. However, state-of-the-art MR methods (e.g., EMILY and PINN+SR) rely on Neural ODE formulations that require iterative solvers and are difficult to accelerate efficiently on edge hardware. We present \textbf{MERINDA} (Model Recovery in Reconfigurable Dynamic Architecture), an FPGA-accelerated MR framework designed to make physical AI practical on resource-constrained devices. MERINDA replaces expensive Neural ODE components with a hardware-friendly formulation that combines (i) GRU-based discretized dynamics, (ii) dense inverse-ODE layers, (iii) sparsity-driven dropout, and (iv) lightweight ODE solvers. The resulting computation is structured for streaming parallelism, enabling critical kernels to be fully parallelized on the FPGA. Across four benchmark nonlinear dynamical systems, MERINDA delivers substantial gains over GPU implementations: \textbf{114$\times$ lower energy} (434~J vs.\ 49{,}375~J), \textbf{28$\times$ smaller memory footprint} (214~MB vs.\ 6{,}118~MB), and \textbf{1.68$\times$ faster training}, while matching state-of-the-art model-recovery accuracy. These results demonstrate that MERINDA can bring accurate, explainable MR to the edge for real-time monitoring of autonomous systems.
NEURO-GUARD: Neuro-Symbolic Generalization and Unbiased Adaptive Routing for Diagnostics -- Explainable Medical AI
Dec 20, 2025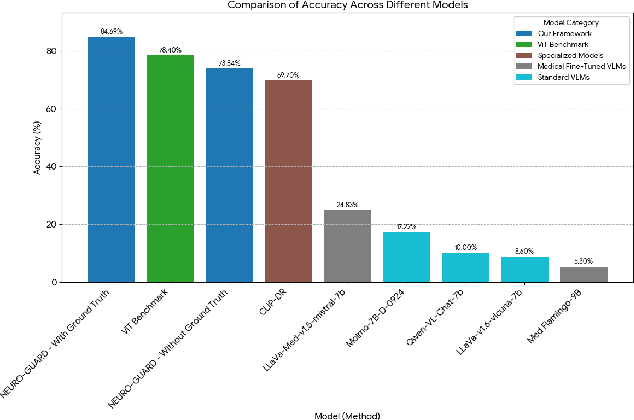
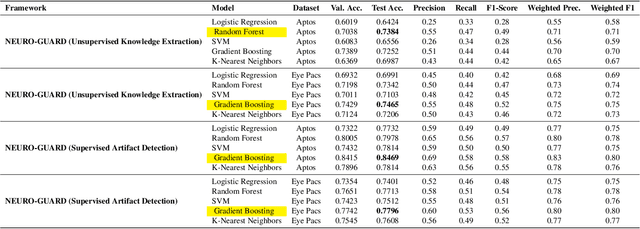
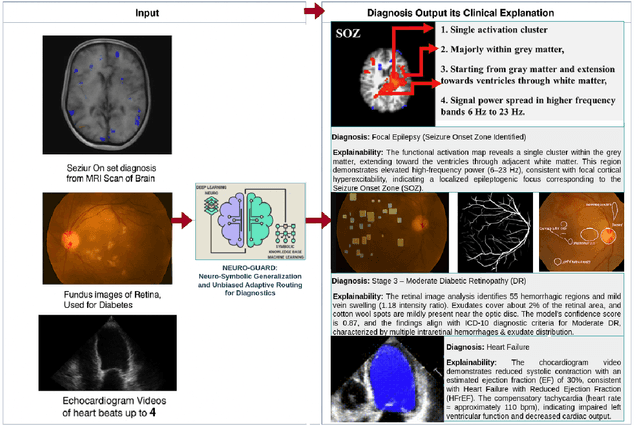

Accurate yet interpretable image-based diagnosis remains a central challenge in medical AI, particularly in settings characterized by limited data, subtle visual cues, and high-stakes clinical decision-making. Most existing vision models rely on purely data-driven learning and produce black-box predictions with limited interpretability and poor cross-domain generalization, hindering their real-world clinical adoption. We present NEURO-GUARD, a novel knowledge-guided vision framework that integrates Vision Transformers (ViTs) with language-driven reasoning to improve performance, transparency, and domain robustness. NEURO-GUARD employs a retrieval-augmented generation (RAG) mechanism for self-verification, in which a large language model (LLM) iteratively generates, evaluates, and refines feature-extraction code for medical images. By grounding this process in clinical guidelines and expert knowledge, the framework progressively enhances feature detection and classification beyond purely data-driven baselines. Extensive experiments on diabetic retinopathy classification across four benchmark datasets APTOS, EyePACS, Messidor-1, and Messidor-2 demonstrate that NEURO-GUARD improves accuracy by 6.2% over a ViT-only baseline (84.69% vs. 78.4%) and achieves a 5% gain in domain generalization. Additional evaluations on MRI-based seizure detection further confirm its cross-domain robustness, consistently outperforming existing methods. Overall, NEURO-GUARD bridges symbolic medical reasoning with subsymbolic visual learning, enabling interpretable, knowledge-aware, and generalizable medical image diagnosis while achieving state-of-the-art performance across multiple datasets.
Accelerated Digital Twin Learning for Edge AI: A Comparison of FPGA and Mobile GPU
Dec 13, 2025Digital twins (DTs) can enable precision healthcare by continually learning a mathematical representation of patient-specific dynamics. However, mission critical healthcare applications require fast, resource-efficient DT learning, which is often infeasible with existing model recovery (MR) techniques due to their reliance on iterative solvers and high compute/memory demands. In this paper, we present a general DT learning framework that is amenable to acceleration on reconfigurable hardware such as FPGAs, enabling substantial speedup and energy efficiency. We compare our FPGA-based implementation with a multi-processing implementation in mobile GPU, which is a popular choice for AI in edge devices. Further, we compare both edge AI implementations with cloud GPU baseline. Specifically, our FPGA implementation achieves an 8.8x improvement in \text{performance-per-watt} for the MR task, a 28.5x reduction in DRAM footprint, and a 1.67x runtime speedup compared to cloud GPU baselines. On the other hand, mobile GPU achieves 2x better performance per watts but has 2x increase in runtime and 10x more DRAM footprint than FPGA. We show the usage of this technique in DT guided synthetic data generation for Type 1 Diabetes and proactive coronary artery disease detection.
MedXAI: A Retrieval-Augmented and Self-Verifying Framework for Knowledge-Guided Medical Image Analysis
Dec 10, 2025Accurate and interpretable image-based diagnosis remains a fundamental challenge in medical AI, particularly under domain shifts and rare-class conditions. Deep learning models often struggle with real-world distribution changes, exhibit bias against infrequent pathologies, and lack the transparency required for deployment in safety-critical clinical environments. We introduce MedXAI (An Explainable Framework for Medical Imaging Classification), a unified expert knowledge based framework that integrates deep vision models with clinician-derived expert knowledge to improve generalization, reduce rare-class bias, and provide human-understandable explanations by localizing the relevant diagnostic features rather than relying on technical post-hoc methods (e.g., Saliency Maps, LIME). We evaluate MedXAI across heterogeneous modalities on two challenging tasks: (i) Seizure Onset Zone localization from resting-state fMRI, and (ii) Diabetic Retinopathy grading. Ex periments on ten multicenter datasets show consistent gains, including a 3% improvement in cross-domain generalization and a 10% improvmnet in F1 score of rare class, substantially outperforming strong deep learning baselines. Ablations confirm that the symbolic components act as effective clinical priors and regularizers, improving robustness under distribution shift. MedXAI delivers clinically aligned explanations while achieving superior in-domain and cross-domain performance, particularly for rare diseases in multimodal medical AI.
TaleDiffusion: Multi-Character Story Generation with Dialogue Rendering
Sep 04, 2025Text-to-story visualization is challenging due to the need for consistent interaction among multiple characters across frames. Existing methods struggle with character consistency, leading to artifact generation and inaccurate dialogue rendering, which results in disjointed storytelling. In response, we introduce TaleDiffusion, a novel framework for generating multi-character stories with an iterative process, maintaining character consistency, and accurate dialogue assignment via postprocessing. Given a story, we use a pre-trained LLM to generate per-frame descriptions, character details, and dialogues via in-context learning, followed by a bounded attention-based per-box mask technique to control character interactions and minimize artifacts. We then apply an identity-consistent self-attention mechanism to ensure character consistency across frames and region-aware cross-attention for precise object placement. Dialogues are also rendered as bubbles and assigned to characters via CLIPSeg. Experimental results demonstrate that TaleDiffusion outperforms existing methods in consistency, noise reduction, and dialogue rendering.
Generating customized prompts for Zero-Shot Rare Event Medical Image Classification using LLM
Jan 27, 2025Rare events, due to their infrequent occurrences, do not have much data, and hence deep learning techniques fail in estimating the distribution for such data. Open-vocabulary models represent an innovative approach to image classification. Unlike traditional models, these models classify images into any set of categories specified with natural language prompts during inference. These prompts usually comprise manually crafted templates (e.g., 'a photo of a {}') that are filled in with the names of each category. This paper introduces a simple yet effective method for generating highly accurate and contextually descriptive prompts containing discriminative characteristics. Rare event detection, especially in medicine, is more challenging due to low inter-class and high intra-class variability. To address these, we propose a novel approach that uses domain-specific expert knowledge on rare events to generate customized and contextually relevant prompts, which are then used by large language models for image classification. Our zero-shot, privacy-preserving method enhances rare event classification without additional training, outperforming state-of-the-art techniques.