 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSonoEdit: Null-Space Constrained Knowledge Editing for Pronunciation Correction in LLM-Based TTS
Jan 23, 2026Neural text-to-speech (TTS) systems systematically mispronounce low-resource proper nouns, particularly non-English names, brands, and geographic locations, due to their underrepresentation in predominantly English training corpora. Existing solutions typically rely on expensive multilingual data collection, supervised finetuning, or manual phonetic annotation, which limits the deployment of TTS systems in linguistically diverse settings. We introduce SonoEdit, a model editing technique that surgically corrects pronunciation errors in pre-trained TTS models without retraining. Instead of costly finetuning or explicit phoneme injection, we propose a parsimonious alternative based on Null-Space Pronunciation Editing, which performs a single-shot parameter update to modify the pronunciation of specific words while provably preserving all other model behavior. We first adapt Acoustic Causal Tracing to identify the Transformer layers responsible for text-to-pronunciation mapping. We then apply Null-Space Constrained Editing to compute a closed-form weight update that corrects the target pronunciation while remaining mathematically orthogonal to the subspace governing general speech generation. This constrained update steers the model's acoustic output toward a desired pronunciation exemplar while guaranteeing zero first-order change on a preserved speech corpus.
SVGCraft: Beyond Single Object Text-to-SVG Synthesis with Comprehensive Canvas Layout
Mar 30, 2024



Generating VectorArt from text prompts is a challenging vision task, requiring diverse yet realistic depictions of the seen as well as unseen entities. However, existing research has been mostly limited to the generation of single objects, rather than comprehensive scenes comprising multiple elements. In response, this work introduces SVGCraft, a novel end-to-end framework for the creation of vector graphics depicting entire scenes from textual descriptions. Utilizing a pre-trained LLM for layout generation from text prompts, this framework introduces a technique for producing masked latents in specified bounding boxes for accurate object placement. It introduces a fusion mechanism for integrating attention maps and employs a diffusion U-Net for coherent composition, speeding up the drawing process. The resulting SVG is optimized using a pre-trained encoder and LPIPS loss with opacity modulation to maximize similarity. Additionally, this work explores the potential of primitive shapes in facilitating canvas completion in constrained environments. Through both qualitative and quantitative assessments, SVGCraft is demonstrated to surpass prior works in abstraction, recognizability, and detail, as evidenced by its performance metrics (CLIP-T: 0.4563, Cosine Similarity: 0.6342, Confusion: 0.66, Aesthetic: 6.7832). The code will be available at https://github.com/ayanban011/SVGCraft.
DiffuseKronA: A Parameter Efficient Fine-tuning Method for Personalized Diffusion Models
Feb 28, 2024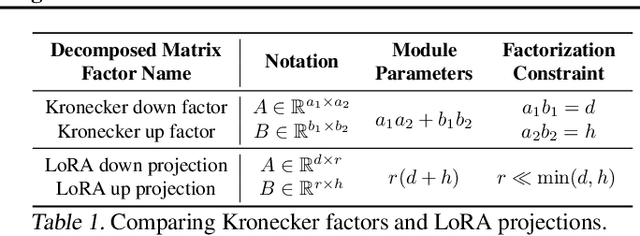



In the realm of subject-driven text-to-image (T2I) generative models, recent developments like DreamBooth and BLIP-Diffusion have led to impressive results yet encounter limitations due to their intensive fine-tuning demands and substantial parameter requirements. While the low-rank adaptation (LoRA) module within DreamBooth offers a reduction in trainable parameters, it introduces a pronounced sensitivity to hyperparameters, leading to a compromise between parameter efficiency and the quality of T2I personalized image synthesis. Addressing these constraints, we introduce \textbf{\textit{DiffuseKronA}}, a novel Kronecker product-based adaptation module that not only significantly reduces the parameter count by 35\% and 99.947\% compared to LoRA-DreamBooth and the original DreamBooth, respectively, but also enhances the quality of image synthesis. Crucially, \textit{DiffuseKronA} mitigates the issue of hyperparameter sensitivity, delivering consistent high-quality generations across a wide range of hyperparameters, thereby diminishing the necessity for extensive fine-tuning. Furthermore, a more controllable decomposition makes \textit{DiffuseKronA} more interpretable and even can achieve up to a 50\% reduction with results comparable to LoRA-Dreambooth. Evaluated against diverse and complex input images and text prompts, \textit{DiffuseKronA} consistently outperforms existing models, producing diverse images of higher quality with improved fidelity and a more accurate color distribution of objects, all the while upholding exceptional parameter efficiency, thus presenting a substantial advancement in the field of T2I generative modeling. Our project page, consisting of links to the code, and pre-trained checkpoints, is available at https://diffusekrona.github.io/.
CLIPDrawX: Primitive-based Explanations for Text Guided Sketch Synthesis
Dec 04, 2023



With the goal of understanding the visual concepts that CLIP associates with text prompts, we show that the latent space of CLIP can be visualized solely in terms of linear transformations on simple geometric primitives like circles and straight lines. Although existing approaches achieve this by sketch-synthesis-through-optimization, they do so on the space of B\'ezier curves, which exhibit a wastefully large set of structures that they can evolve into, as most of them are non-essential for generating meaningful sketches. We present CLIPDrawX, an algorithm that provides significantly better visualizations for CLIP text embeddings, using only simple primitive shapes like straight lines and circles. This constrains the set of possible outputs to linear transformations on these primitives, thereby exhibiting an inherently simpler mathematical form. The synthesis process of CLIPDrawX can be tracked end-to-end, with each visual concept being explained exclusively in terms of primitives. Implementation will be released upon acceptance. Project Page: $\href{https://clipdrawx.github.io/}{\text{https://clipdrawx.github.io/}}$.