 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Multimodal Representation Collapse
May 28, 2025We aim to develop a fundamental understanding of modality collapse, a recently observed empirical phenomenon wherein models trained for multimodal fusion tend to rely only on a subset of the modalities, ignoring the rest. We show that modality collapse happens when noisy features from one modality are entangled, via a shared set of neurons in the fusion head, with predictive features from another, effectively masking out positive contributions from the predictive features of the former modality and leading to its collapse. We further prove that cross-modal knowledge distillation implicitly disentangles such representations by freeing up rank bottlenecks in the student encoder, denoising the fusion-head outputs without negatively impacting the predictive features from either modality. Based on the above findings, we propose an algorithm that prevents modality collapse through explicit basis reallocation, with applications in dealing with missing modalities. Extensive experiments on multiple multimodal benchmarks validate our theoretical claims. Project page: https://abhrac.github.io/mmcollapse/.
Sebra: Debiasing Through Self-Guided Bias Ranking
Jan 30, 2025



Ranking samples by fine-grained estimates of spuriosity (the degree to which spurious cues are present) has recently been shown to significantly benefit bias mitigation, over the traditional binary biased-\textit{vs}-unbiased partitioning of train sets. However, this spuriosity ranking comes with the requirement of human supervision. In this paper, we propose a debiasing framework based on our novel \ul{Se}lf-Guided \ul{B}ias \ul{Ra}nking (\emph{Sebra}), that mitigates biases (spurious correlations) via an automatic ranking of data points by spuriosity within their respective classes. Sebra leverages a key local symmetry in Empirical Risk Minimization (ERM) training -- the ease of learning a sample via ERM inversely correlates with its spuriousity; the fewer spurious correlations a sample exhibits, the harder it is to learn, and vice versa. However, globally across iterations, ERM tends to deviate from this symmetry. Sebra dynamically steers ERM to correct this deviation, facilitating the sequential learning of attributes in increasing order of difficulty, \ie, decreasing order of spuriosity. As a result, the sequence in which Sebra learns samples naturally provides spuriousity rankings. We use the resulting fine-grained bias characterization in a contrastive learning framework to mitigate biases from multiple sources. Extensive experiments show that Sebra consistently outperforms previous state-of-the-art unsupervised debiasing techniques across multiple standard benchmarks, including UrbanCars, BAR, CelebA, and ImageNet-1K. Code, pre-trained models, and training logs are available at https://kadarsh22.github.io/sebra_iclr25/.
Learning Conditional Invariances through Non-Commutativity
Feb 18, 2024Invariance learning algorithms that conditionally filter out domain-specific random variables as distractors, do so based only on the data semantics, and not the target domain under evaluation. We show that a provably optimal and sample-efficient way of learning conditional invariances is by relaxing the invariance criterion to be non-commutatively directed towards the target domain. Under domain asymmetry, i.e., when the target domain contains semantically relevant information absent in the source, the risk of the encoder $\varphi^*$ that is optimal on average across domains is strictly lower-bounded by the risk of the target-specific optimal encoder $\Phi^*_\tau$. We prove that non-commutativity steers the optimization towards $\Phi^*_\tau$ instead of $\varphi^*$, bringing the $\mathcal{H}$-divergence between domains down to zero, leading to a stricter bound on the target risk. Both our theory and experiments demonstrate that non-commutative invariance (NCI) can leverage source domain samples to meet the sample complexity needs of learning $\Phi^*_\tau$, surpassing SOTA invariance learning algorithms for domain adaptation, at times by over $2\%$, approaching the performance of an oracle. Implementation is available at https://github.com/abhrac/nci.
CLIPDrawX: Primitive-based Explanations for Text Guided Sketch Synthesis
Dec 04, 2023



With the goal of understanding the visual concepts that CLIP associates with text prompts, we show that the latent space of CLIP can be visualized solely in terms of linear transformations on simple geometric primitives like circles and straight lines. Although existing approaches achieve this by sketch-synthesis-through-optimization, they do so on the space of B\'ezier curves, which exhibit a wastefully large set of structures that they can evolve into, as most of them are non-essential for generating meaningful sketches. We present CLIPDrawX, an algorithm that provides significantly better visualizations for CLIP text embeddings, using only simple primitive shapes like straight lines and circles. This constrains the set of possible outputs to linear transformations on these primitives, thereby exhibiting an inherently simpler mathematical form. The synthesis process of CLIPDrawX can be tracked end-to-end, with each visual concept being explained exclusively in terms of primitives. Implementation will be released upon acceptance. Project Page: $\href{https://clipdrawx.github.io/}{\text{https://clipdrawx.github.io/}}$.
Transitivity Recovering Decompositions: Interpretable and Robust Fine-Grained Relationships
Oct 24, 2023Recent advances in fine-grained representation learning leverage local-to-global (emergent) relationships for achieving state-of-the-art results. The relational representations relied upon by such methods, however, are abstract. We aim to deconstruct this abstraction by expressing them as interpretable graphs over image views. We begin by theoretically showing that abstract relational representations are nothing but a way of recovering transitive relationships among local views. Based on this, we design Transitivity Recovering Decompositions (TRD), a graph-space search algorithm that identifies interpretable equivalents of abstract emergent relationships at both instance and class levels, and with no post-hoc computations. We additionally show that TRD is provably robust to noisy views, with empirical evidence also supporting this finding. The latter allows TRD to perform at par or even better than the state-of-the-art, while being fully interpretable. Implementation is available at https://github.com/abhrac/trd.
Sarcasm in Sight and Sound: Benchmarking and Expansion to Improve Multimodal Sarcasm Detection
Sep 29, 2023



The introduction of the MUStARD dataset, and its emotion recognition extension MUStARD++, have identified sarcasm to be a multi-modal phenomenon -- expressed not only in natural language text, but also through manners of speech (like tonality and intonation) and visual cues (facial expression). With this work, we aim to perform a rigorous benchmarking of the MUStARD++ dataset by considering state-of-the-art language, speech, and visual encoders, for fully utilizing the totality of the multi-modal richness that it has to offer, achieving a 2\% improvement in macro-F1 over the existing benchmark. Additionally, to cure the imbalance in the `sarcasm type' category in MUStARD++, we propose an extension, which we call \emph{MUStARD++ Balanced}, benchmarking the same with instances from the extension split across both train and test sets, achieving a further 2.4\% macro-F1 boost. The new clips were taken from a novel source -- the TV show, House MD, which adds to the diversity of the dataset, and were manually annotated by multiple annotators with substantial inter-annotator agreement in terms of Cohen's kappa and Krippendorf's alpha. Our code, extended data, and SOTA benchmark models are made public.
Data-Free Sketch-Based Image Retrieval
Mar 14, 2023



Rising concerns about privacy and anonymity preservation of deep learning models have facilitated research in data-free learning (DFL). For the first time, we identify that for data-scarce tasks like Sketch-Based Image Retrieval (SBIR), where the difficulty in acquiring paired photos and hand-drawn sketches limits data-dependent cross-modal learning algorithms, DFL can prove to be a much more practical paradigm. We thus propose Data-Free (DF)-SBIR, where, unlike existing DFL problems, pre-trained, single-modality classification models have to be leveraged to learn a cross-modal metric-space for retrieval without access to any training data. The widespread availability of pre-trained classification models, along with the difficulty in acquiring paired photo-sketch datasets for SBIR justify the practicality of this setting. We present a methodology for DF-SBIR, which can leverage knowledge from models independently trained to perform classification on photos and sketches. We evaluate our model on the Sketchy, TU-Berlin, and QuickDraw benchmarks, designing a variety of baselines based on state-of-the-art DFL literature, and observe that our method surpasses all of them by significant margins. Our method also achieves mAPs competitive with data-dependent approaches, all the while requiring no training data. Implementation is available at \url{https://github.com/abhrac/data-free-sbir}.
Cross-Modal Fusion Distillation for Fine-Grained Sketch-Based Image Retrieval
Oct 19, 2022
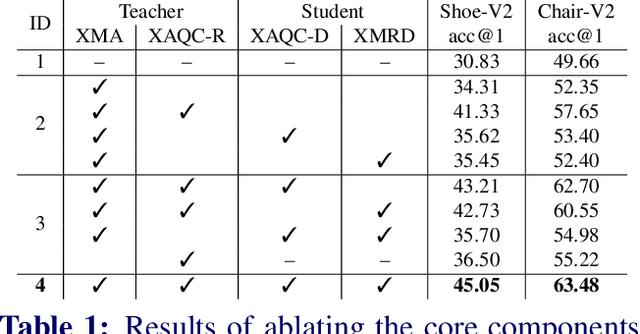

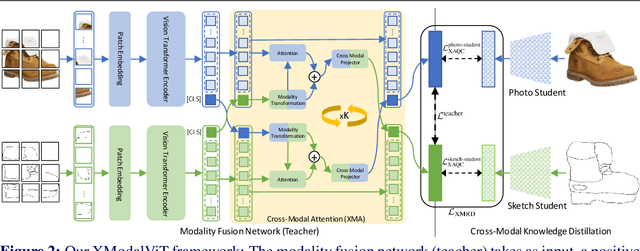
Representation learning for sketch-based image retrieval has mostly been tackled by learning embeddings that discard modality-specific information. As instances from different modalities can often provide complementary information describing the underlying concept, we propose a cross-attention framework for Vision Transformers (XModalViT) that fuses modality-specific information instead of discarding them. Our framework first maps paired datapoints from the individual photo and sketch modalities to fused representations that unify information from both modalities. We then decouple the input space of the aforementioned modality fusion network into independent encoders of the individual modalities via contrastive and relational cross-modal knowledge distillation. Such encoders can then be applied to downstream tasks like cross-modal retrieval. We demonstrate the expressive capacity of the learned representations by performing a wide range of experiments and achieving state-of-the-art results on three fine-grained sketch-based image retrieval benchmarks: Shoe-V2, Chair-V2 and Sketchy. Implementation is available at https://github.com/abhrac/xmodal-vit.
Relational Proxies: Emergent Relationships as Fine-Grained Discriminators
Oct 05, 2022
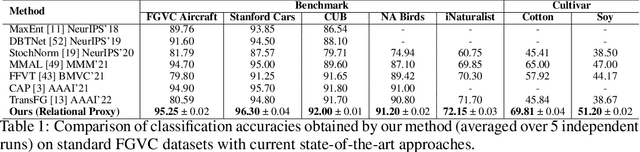


Fine-grained categories that largely share the same set of parts cannot be discriminated based on part information alone, as they mostly differ in the way the local parts relate to the overall global structure of the object. We propose Relational Proxies, a novel approach that leverages the relational information between the global and local views of an object for encoding its semantic label. Starting with a rigorous formalization of the notion of distinguishability between fine-grained categories, we prove the necessary and sufficient conditions that a model must satisfy in order to learn the underlying decision boundaries in the fine-grained setting. We design Relational Proxies based on our theoretical findings and evaluate it on seven challenging fine-grained benchmark datasets and achieve state-of-the-art results on all of them, surpassing the performance of all existing works with a margin exceeding 4% in some cases. We also experimentally validate our theory on fine-grained distinguishability and obtain consistent results across multiple benchmarks. Implementation is available at https://github.com/abhrac/relational-proxies.