 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable and Loosely-Coupled Multimodal Deep Learning for Breast Cancer Subtyping
Sep 03, 2025Healthcare applications are inherently multimodal, benefiting greatly from the integration of diverse data sources. However, the modalities available in clinical settings can vary across different locations and patients. A key area that stands to gain from multimodal integration is breast cancer molecular subtyping, an important clinical task that can facilitate personalized treatment and improve patient prognosis. In this work, we propose a scalable and loosely-coupled multimodal framework that seamlessly integrates data from various modalities, including copy number variation (CNV), clinical records, and histopathology images, to enhance breast cancer subtyping. While our primary focus is on breast cancer, our framework is designed to easily accommodate additional modalities, offering the flexibility to scale up or down with minimal overhead without requiring re-training of existing modalities, making it applicable to other types of cancers as well. We introduce a dual-based representation for whole slide images (WSIs), combining traditional image-based and graph-based WSI representations. This novel dual approach results in significant performance improvements. Moreover, we present a new multimodal fusion strategy, demonstrating its ability to enhance performance across a range of multimodal conditions. Our comprehensive results show that integrating our dual-based WSI representation with CNV and clinical health records, along with our pipeline and fusion strategy, outperforms state-of-the-art methods in breast cancer subtyping.
X2Graph for Cancer Subtyping Prediction on Biological Tabular Data
May 29, 2025Despite the transformative impact of deep learning on text, audio, and image datasets, its dominance in tabular data, especially in the medical domain where data are often scarce, remains less clear. In this paper, we propose X2Graph, a novel deep learning method that achieves strong performance on small biological tabular datasets. X2Graph leverages external knowledge about the relationships between table columns, such as gene interactions, to convert each sample into a graph structure. This transformation enables the application of standard message passing algorithms for graph modeling. Our X2Graph method demonstrates superior performance compared to existing tree-based and deep learning methods across three cancer subtyping datasets.
A Closer Look at Multimodal Representation Collapse
May 28, 2025We aim to develop a fundamental understanding of modality collapse, a recently observed empirical phenomenon wherein models trained for multimodal fusion tend to rely only on a subset of the modalities, ignoring the rest. We show that modality collapse happens when noisy features from one modality are entangled, via a shared set of neurons in the fusion head, with predictive features from another, effectively masking out positive contributions from the predictive features of the former modality and leading to its collapse. We further prove that cross-modal knowledge distillation implicitly disentangles such representations by freeing up rank bottlenecks in the student encoder, denoising the fusion-head outputs without negatively impacting the predictive features from either modality. Based on the above findings, we propose an algorithm that prevents modality collapse through explicit basis reallocation, with applications in dealing with missing modalities. Extensive experiments on multiple multimodal benchmarks validate our theoretical claims. Project page: https://abhrac.github.io/mmcollapse/.
ProMark: Proactive Diffusion Watermarking for Causal Attribution
Mar 14, 2024



Generative AI (GenAI) is transforming creative workflows through the capability to synthesize and manipulate images via high-level prompts. Yet creatives are not well supported to receive recognition or reward for the use of their content in GenAI training. To this end, we propose ProMark, a causal attribution technique to attribute a synthetically generated image to its training data concepts like objects, motifs, templates, artists, or styles. The concept information is proactively embedded into the input training images using imperceptible watermarks, and the diffusion models (unconditional or conditional) are trained to retain the corresponding watermarks in generated images. We show that we can embed as many as $2^{16}$ unique watermarks into the training data, and each training image can contain more than one watermark. ProMark can maintain image quality whilst outperforming correlation-based attribution. Finally, several qualitative examples are presented, providing the confidence that the presence of the watermark conveys a causative relationship between training data and synthetic images.
VIXEN: Visual Text Comparison Network for Image Difference Captioning
Mar 14, 2024
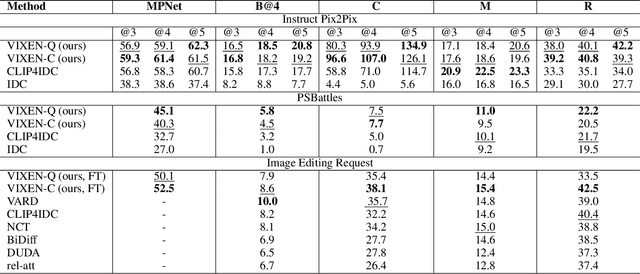
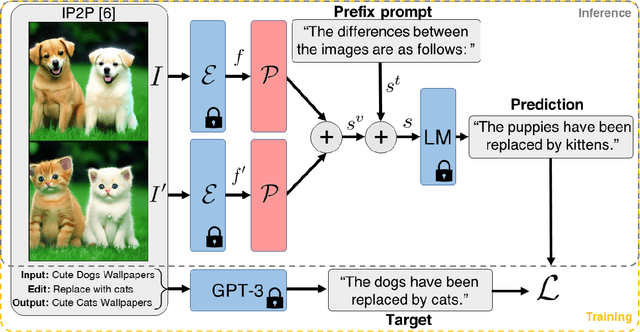
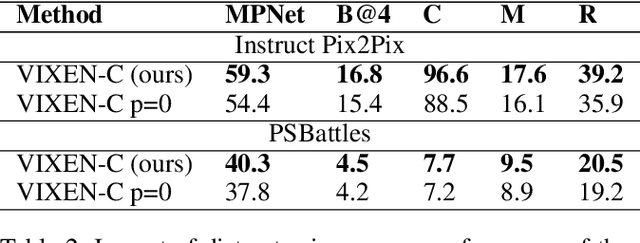
We present VIXEN - a technique that succinctly summarizes in text the visual differences between a pair of images in order to highlight any content manipulation present. Our proposed network linearly maps image features in a pairwise manner, constructing a soft prompt for a pretrained large language model. We address the challenge of low volume of training data and lack of manipulation variety in existing image difference captioning (IDC) datasets by training on synthetically manipulated images from the recent InstructPix2Pix dataset generated via prompt-to-prompt editing framework. We augment this dataset with change summaries produced via GPT-3. We show that VIXEN produces state-of-the-art, comprehensible difference captions for diverse image contents and edit types, offering a potential mitigation against misinformation disseminated via manipulated image content. Code and data are available at http://github.com/alexblck/vixen
TrustMark: Universal Watermarking for Arbitrary Resolution Images
Nov 30, 2023


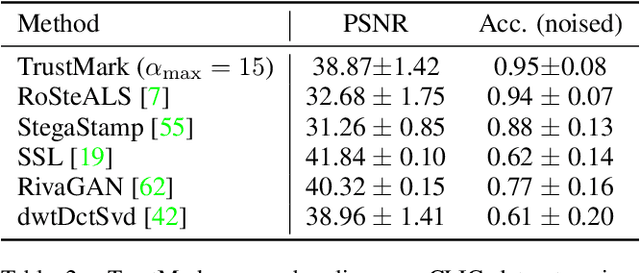
Imperceptible digital watermarking is important in copyright protection, misinformation prevention, and responsible generative AI. We propose TrustMark - a GAN-based watermarking method with novel design in architecture and spatio-spectra losses to balance the trade-off between watermarked image quality with the watermark recovery accuracy. Our model is trained with robustness in mind, withstanding various in- and out-place perturbations on the encoded image. Additionally, we introduce TrustMark-RM - a watermark remover method useful for re-watermarking. Our methods achieve state-of-art performance on 3 benchmarks comprising arbitrary resolution images.
RoSteALS: Robust Steganography using Autoencoder Latent Space
Apr 06, 2023



Data hiding such as steganography and invisible watermarking has important applications in copyright protection, privacy-preserved communication and content provenance. Existing works often fall short in either preserving image quality, or robustness against perturbations or are too complex to train. We propose RoSteALS, a practical steganography technique leveraging frozen pretrained autoencoders to free the payload embedding from learning the distribution of cover images. RoSteALS has a light-weight secret encoder of just 300k parameters, is easy to train, has perfect secret recovery performance and comparable image quality on three benchmarks. Additionally, RoSteALS can be adapted for novel cover-less steganography applications in which the cover image can be sampled from noise or conditioned on text prompts via a denoising diffusion process. Our model and code are available at \url{https://github.com/TuBui/RoSteALS}.
PARASOL: Parametric Style Control for Diffusion Image Synthesis
Mar 27, 2023We propose PARASOL, a multi-modal synthesis model that enables disentangled, parametric control of the visual style of the image by jointly conditioning synthesis on both content and a fine-grained visual style embedding. We train a latent diffusion model (LDM) using specific losses for each modality and adapt the classifier-free guidance for encouraging disentangled control over independent content and style modalities at inference time. We leverage auxiliary semantic and style-based search to create training triplets for supervision of the LDM, ensuring complementarity of content and style cues. PARASOL shows promise for enabling nuanced control over visual style in diffusion models for image creation and stylization, as well as generative search where text-based search results may be adapted to more closely match user intent by interpolating both content and style descriptors.
VADER: Video Alignment Differencing and Retrieval
Mar 25, 2023



We propose VADER, a spatio-temporal matching, alignment, and change summarization method to help fight misinformation spread via manipulated videos. VADER matches and coarsely aligns partial video fragments to candidate videos using a robust visual descriptor and scalable search over adaptively chunked video content. A transformer-based alignment module then refines the temporal localization of the query fragment within the matched video. A space-time comparator module identifies regions of manipulation between aligned content, invariant to any changes due to any residual temporal misalignments or artifacts arising from non-editorial changes of the content. Robustly matching video to a trusted source enables conclusions to be drawn on video provenance, enabling informed trust decisions on content encountered.
RepMix: Representation Mixing for Robust Attribution of Synthesized Images
Jul 12, 2022
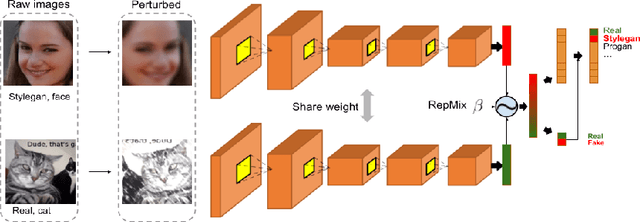
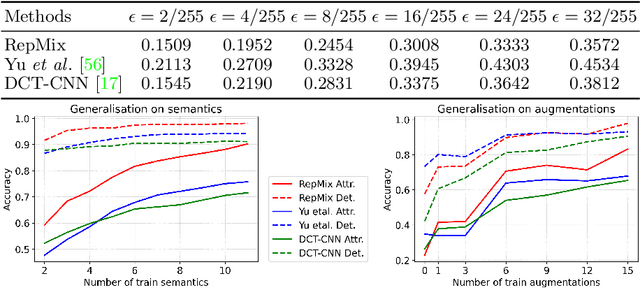
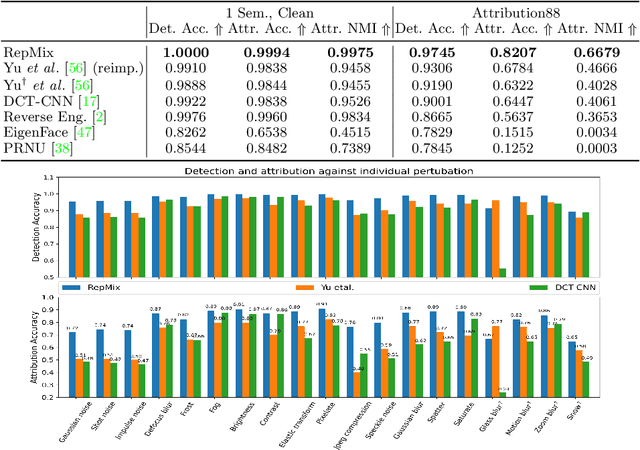
Rapid advances in Generative Adversarial Networks (GANs) raise new challenges for image attribution; detecting whether an image is synthetic and, if so, determining which GAN architecture created it. Uniquely, we present a solution to this task capable of 1) matching images invariant to their semantic content; 2) robust to benign transformations (changes in quality, resolution, shape, etc.) commonly encountered as images are re-shared online. In order to formalize our research, a challenging benchmark, Attribution88, is collected for robust and practical image attribution. We then propose RepMix, our GAN fingerprinting technique based on representation mixing and a novel loss. We validate its capability of tracing the provenance of GAN-generated images invariant to the semantic content of the image and also robust to perturbations. We show our approach improves significantly from existing GAN fingerprinting works on both semantic generalization and robustness. Data and code are available at https://github.com/TuBui/image_attribution.