 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX2Graph for Cancer Subtyping Prediction on Biological Tabular Data
May 29, 2025Despite the transformative impact of deep learning on text, audio, and image datasets, its dominance in tabular data, especially in the medical domain where data are often scarce, remains less clear. In this paper, we propose X2Graph, a novel deep learning method that achieves strong performance on small biological tabular datasets. X2Graph leverages external knowledge about the relationships between table columns, such as gene interactions, to convert each sample into a graph structure. This transformation enables the application of standard message passing algorithms for graph modeling. Our X2Graph method demonstrates superior performance compared to existing tree-based and deep learning methods across three cancer subtyping datasets.
Scalable Graph Convolutional Network Training on Distributed-Memory Systems
Dec 13, 2022
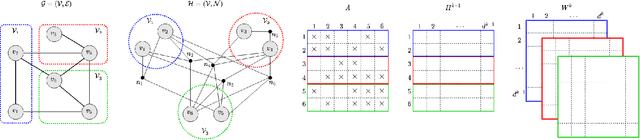
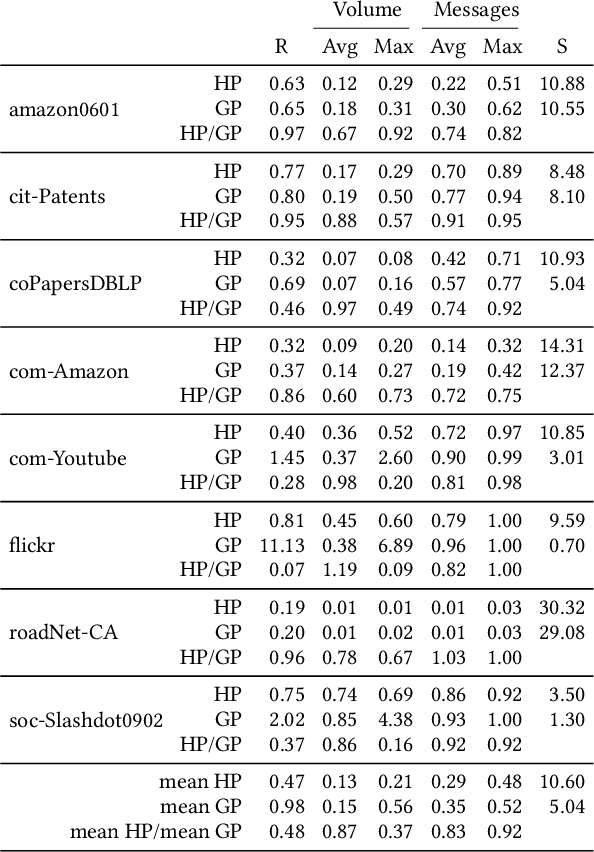
Graph Convolutional Networks (GCNs) are extensively utilized for deep learning on graphs. The large data sizes of graphs and their vertex features make scalable training algorithms and distributed memory systems necessary. Since the convolution operation on graphs induces irregular memory access patterns, designing a memory- and communication-efficient parallel algorithm for GCN training poses unique challenges. We propose a highly parallel training algorithm that scales to large processor counts. In our solution, the large adjacency and vertex-feature matrices are partitioned among processors. We exploit the vertex-partitioning of the graph to use non-blocking point-to-point communication operations between processors for better scalability. To further minimize the parallelization overheads, we introduce a sparse matrix partitioning scheme based on a hypergraph partitioning model for full-batch training. We also propose a novel stochastic hypergraph model to encode the expected communication volume in mini-batch training. We show the merits of the hypergraph model, previously unexplored for GCN training, over the standard graph partitioning model which does not accurately encode the communication costs. Experiments performed on real-world graph datasets demonstrate that the proposed algorithms achieve considerable speedups over alternative solutions. The optimizations achieved on communication costs become even more pronounced at high scalability with many processors. The performance benefits are preserved in deeper GCNs having more layers as well as on billion-scale graphs.
RAGUEL: Recourse-Aware Group Unfairness Elimination
Aug 30, 2022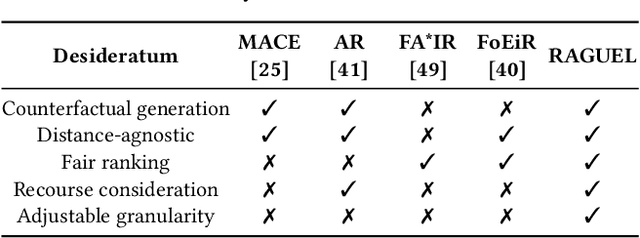
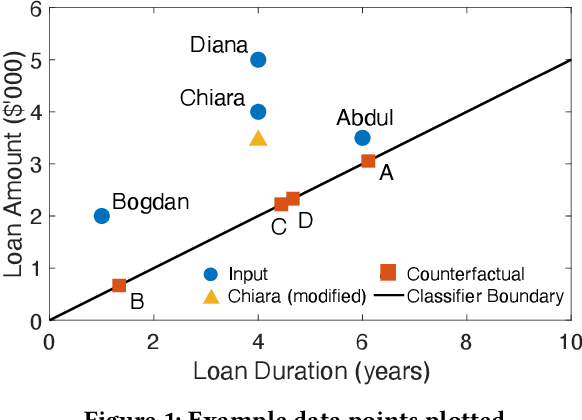
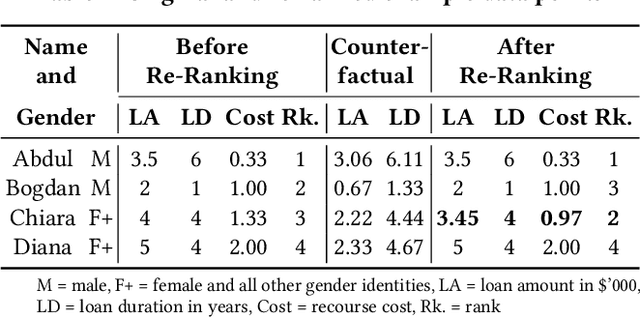
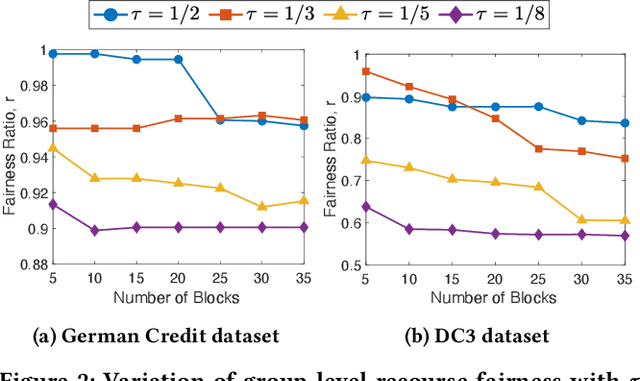
While machine learning and ranking-based systems are in widespread use for sensitive decision-making processes (e.g., determining job candidates, assigning credit scores), they are rife with concerns over unintended biases in their outcomes, which makes algorithmic fairness (e.g., demographic parity, equal opportunity) an objective of interest. 'Algorithmic recourse' offers feasible recovery actions to change unwanted outcomes through the modification of attributes. We introduce the notion of ranked group-level recourse fairness, and develop a 'recourse-aware ranking' solution that satisfies ranked recourse fairness constraints while minimizing the cost of suggested modifications. Our solution suggests interventions that can reorder the ranked list of database records and mitigate group-level unfairness; specifically, disproportionate representation of sub-groups and recourse cost imbalance. This re-ranking identifies the minimum modifications to data points, with these attribute modifications weighted according to their ease of recourse. We then present an efficient block-based extension that enables re-ranking at any granularity (e.g., multiple brackets of bank loan interest rates, multiple pages of search engine results). Evaluation on real datasets shows that, while existing methods may even exacerbate recourse unfairness, our solution -- RAGUEL -- significantly improves recourse-aware fairness. RAGUEL outperforms alternatives at improving recourse fairness, through a combined process of counterfactual generation and re-ranking, whilst remaining efficient for large-scale datasets.
Characterizing the impact of geometric properties of word embeddings on task performance
Apr 09, 2019
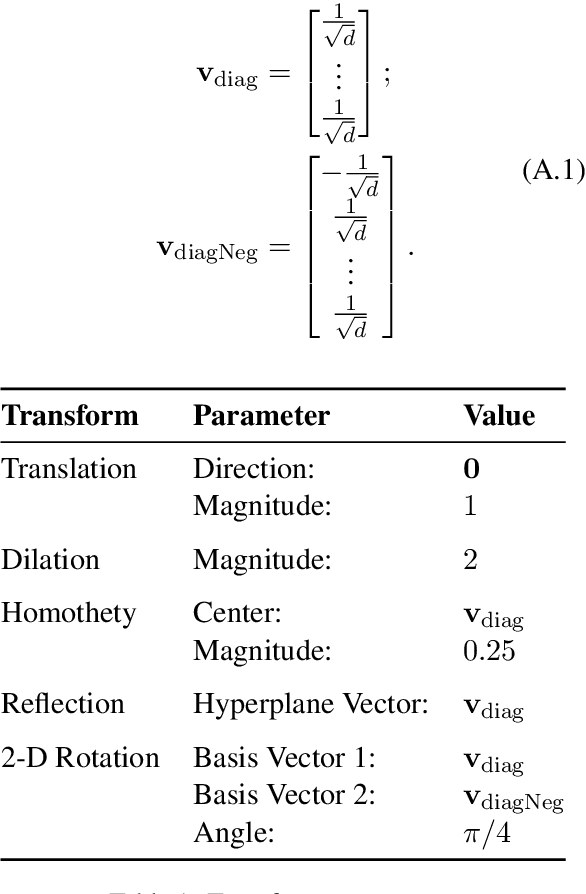

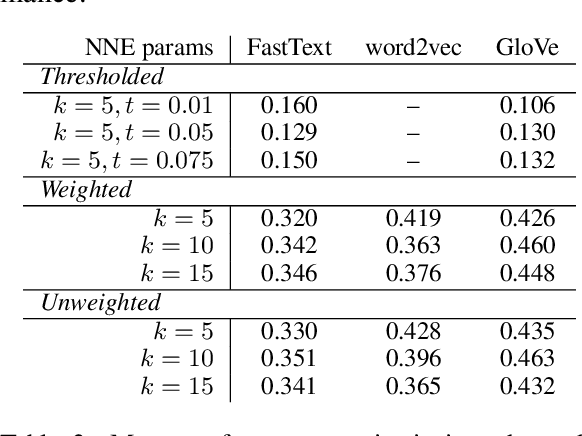
Analysis of word embedding properties to inform their use in downstream NLP tasks has largely been studied by assessing nearest neighbors. However, geometric properties of the continuous feature space contribute directly to the use of embedding features in downstream models, and are largely unexplored. We consider four properties of word embedding geometry, namely: position relative to the origin, distribution of features in the vector space, global pairwise distances, and local pairwise distances. We define a sequence of transformations to generate new embeddings that expose subsets of these properties to downstream models and evaluate change in task performance to understand the contribution of each property to NLP models. We transform publicly available pretrained embeddings from three popular toolkits (word2vec, GloVe, and FastText) and evaluate on a variety of intrinsic tasks, which model linguistic information in the vector space, and extrinsic tasks, which use vectors as input to machine learning models. We find that intrinsic evaluations are highly sensitive to absolute position, while extrinsic tasks rely primarily on local similarity. Our findings suggest that future embedding models and post-processing techniques should focus primarily on similarity to nearby points in vector space.
Collecting Diverse Natural Language Inference Problems for Sentence Representation Evaluation
Aug 29, 2018
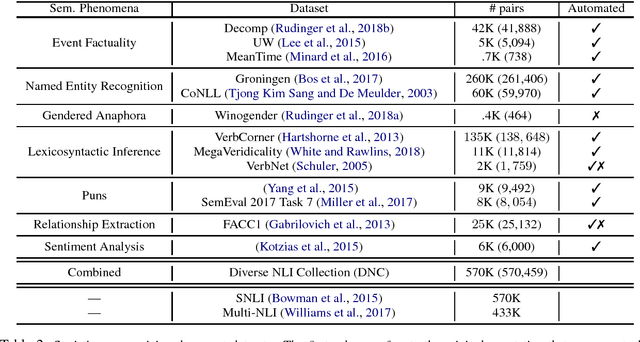
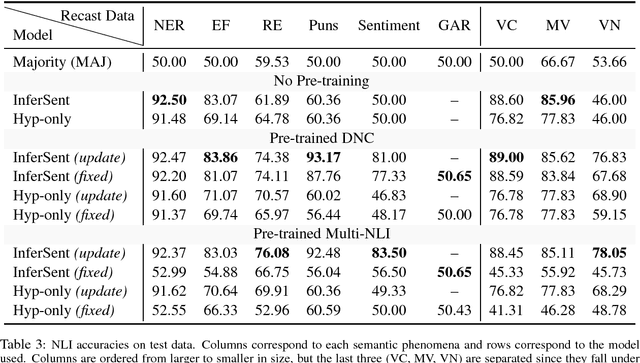
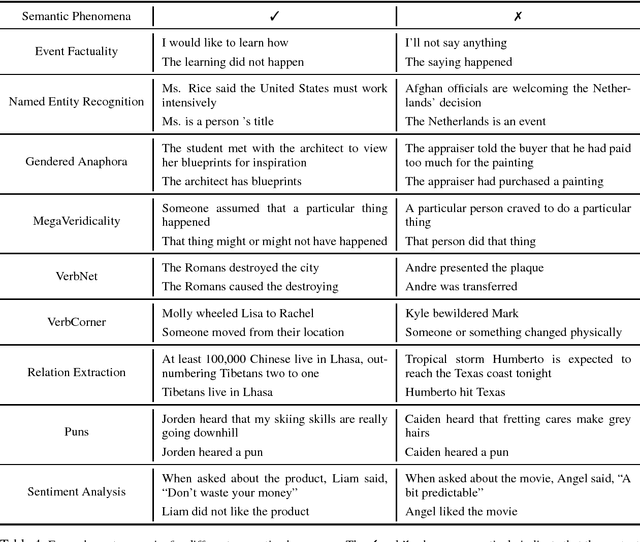
We present a large-scale collection of diverse natural language inference (NLI) datasets that help provide insight into how well a sentence representation captures distinct types of reasoning. The collection results from recasting 13 existing datasets from 7 semantic phenomena into a common NLI structure, resulting in over half a million labeled context-hypothesis pairs in total. We refer to our collection as the DNC: Diverse Natural Language Inference Collection. The DNC is available online at https://www.decomp.net, and will grow over time as additional resources are recast and added from novel sources.
Hypothesis Only Baselines in Natural Language Inference
May 02, 2018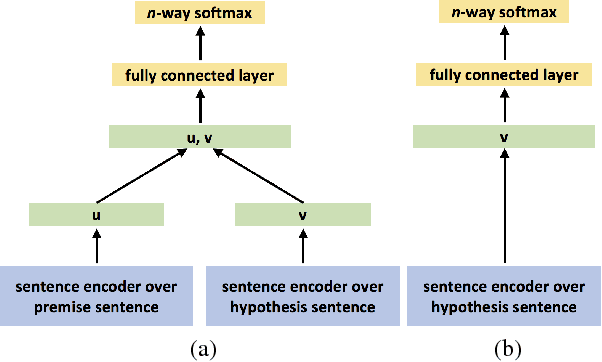
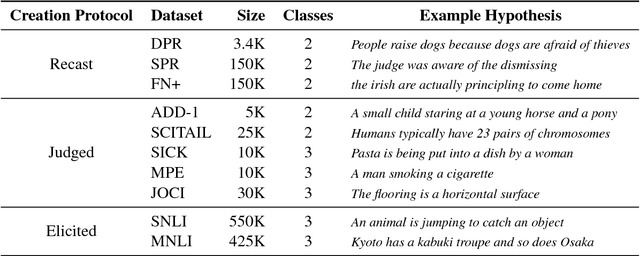
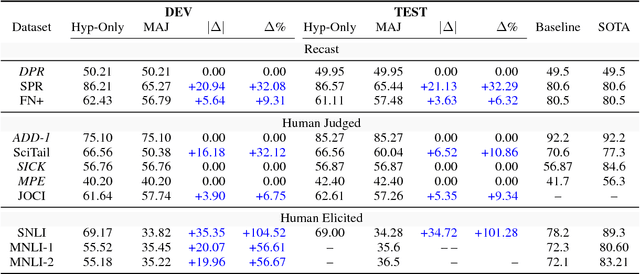
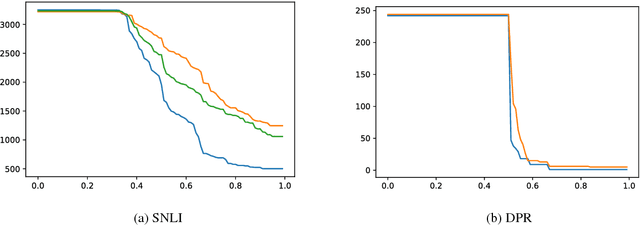
We propose a hypothesis only baseline for diagnosing Natural Language Inference (NLI). Especially when an NLI dataset assumes inference is occurring based purely on the relationship between a context and a hypothesis, it follows that assessing entailment relations while ignoring the provided context is a degenerate solution. Yet, through experiments on ten distinct NLI datasets, we find that this approach, which we refer to as a hypothesis-only model, is able to significantly outperform a majority class baseline across a number of NLI datasets. Our analysis suggests that statistical irregularities may allow a model to perform NLI in some datasets beyond what should be achievable without access to the context.