 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking World States with Language Models: State-Based Evaluation Using Chess
Aug 27, 2025Large Language Models (LLMs) exhibit emergent capabilities in structured domains, suggesting they may implicitly internalize high-fidelity representations of world models. While probing techniques have shown promising signs of this in scientific and game-based settings, they rely on model-specific internal activations, which limit interpretability and generalizability. In this work, we propose a model-agnostic, state-based evaluation framework using chess as a benchmark to assess whether LLMs preserve the semantics of structured environments. Our method analyzes the downstream legal move distributions (state affordances) to estimate semantic fidelity between predicted and actual game states. This approach offers a more meaningful evaluation than conventional string-based metrics by aligning more closely with the strategic and rule-governed nature of chess. Experimental results demonstrate that our metrics capture deficiencies in state-tracking, highlighting limitations of LLMs in maintaining coherent internal models over long sequences. Our framework provides a robust tool for evaluating structured reasoning in LLMs without requiring internal model access, and generalizes to a wide class of symbolic environments.
Does it Chug? Towards a Data-Driven Understanding of Guitar Tone Description
Dec 16, 2024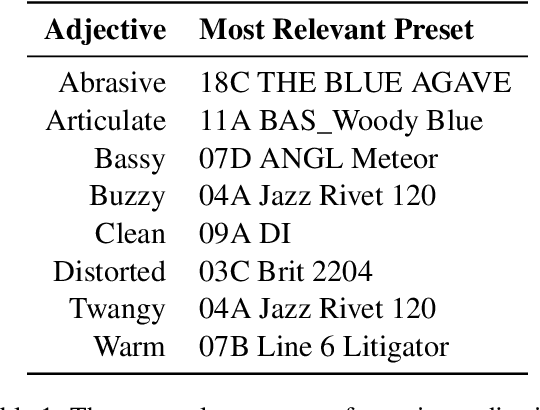
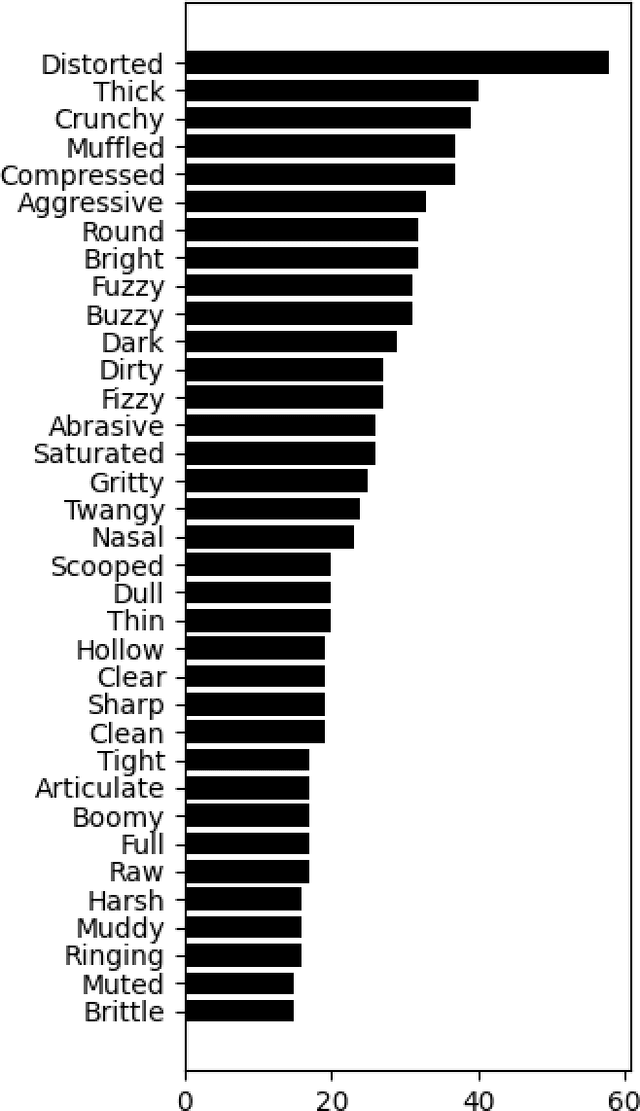
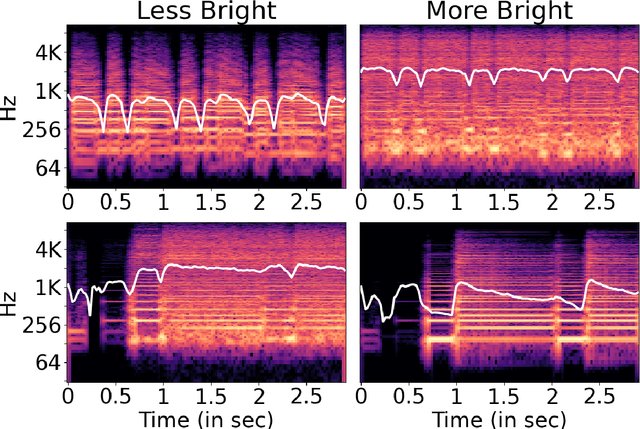
Natural language is commonly used to describe instrument timbre, such as a "warm" or "heavy" sound. As these descriptors are based on human perception, there can be disagreement over which acoustic features correspond to a given adjective. In this work, we pursue a data-driven approach to further our understanding of such adjectives in the context of guitar tone. Our main contribution is a dataset of timbre adjectives, constructed by processing single clips of instrument audio to produce varied timbres through adjustments in EQ and effects such as distortion. Adjective annotations are obtained for each clip by crowdsourcing experts to complete a pairwise comparison and a labeling task. We examine the dataset and reveal correlations between adjective ratings and highlight instances where the data contradicts prevailing theories on spectral features and timbral adjectives, suggesting a need for a more nuanced, data-driven understanding of timbre.
A Foundation Model for the Solar Dynamics Observatory
Oct 03, 2024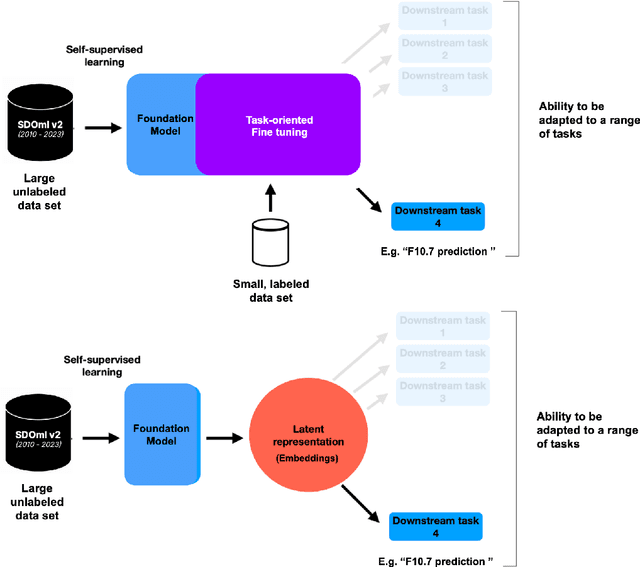


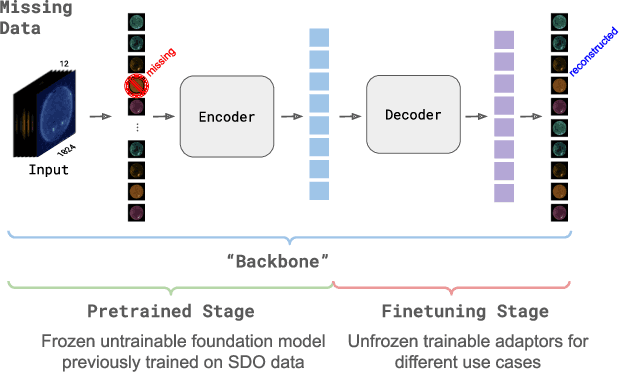
SDO-FM is a foundation model using data from NASA's Solar Dynamics Observatory (SDO) spacecraft; integrating three separate instruments to encapsulate the Sun's complex physical interactions into a multi-modal embedding space. This model can be used to streamline scientific investigations involving SDO by making the enormous datasets more computationally accessible for heliophysics research and enable investigations that require instrument fusion. We discuss four key components: an ingestion pipeline to create machine learning ready datasets, the model architecture and training approach, resultant embeddings and fine-tunable models, and finally downstream fine-tuned applications. A key component of this effort has been to include subject matter specialists at each stage of development; reviewing the scientific value and providing guidance for model architecture, dataset, and training paradigm decisions. This paper marks release of our pretrained models and embedding datasets, available to the community on Hugging Face and sdofm.org.
Self-Emotion Blended Dialogue Generation in Social Simulation Agents
Aug 03, 2024



When engaging in conversations, dialogue agents in a virtual simulation environment may exhibit their own emotional states that are unrelated to the immediate conversational context, a phenomenon known as self-emotion. This study explores how such self-emotion affects the agents' behaviors in dialogue strategies and decision-making within a large language model (LLM)-driven simulation framework. In a dialogue strategy prediction experiment, we analyze the dialogue strategy choices employed by agents both with and without self-emotion, comparing them to those of humans. The results show that incorporating self-emotion helps agents exhibit more human-like dialogue strategies. In an independent experiment comparing the performance of models fine-tuned on GPT-4 generated dialogue datasets, we demonstrate that self-emotion can lead to better overall naturalness and humanness. Finally, in a virtual simulation environment where agents have discussions on multiple topics, we show that self-emotion of agents can significantly influence the decision-making process of the agents, leading to approximately a 50% change in decisions.
Textless Dependency Parsing by Labeled Sequence Prediction
Jul 14, 2024
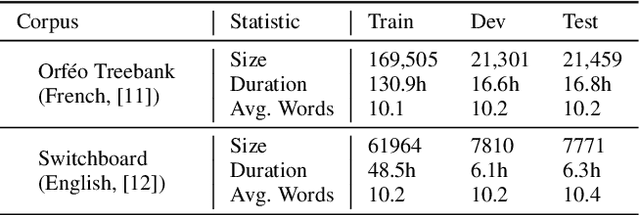
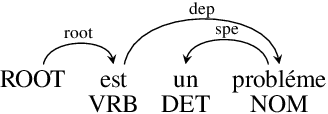

Traditional spoken language processing involves cascading an automatic speech recognition (ASR) system into text processing models. In contrast, "textless" methods process speech representations without ASR systems, enabling the direct use of acoustic speech features. Although their effectiveness is shown in capturing acoustic features, it is unclear in capturing lexical knowledge. This paper proposes a textless method for dependency parsing, examining its effectiveness and limitations. Our proposed method predicts a dependency tree from a speech signal without transcribing, representing the tree as a labeled sequence. scading method outperforms the textless method in overall parsing accuracy, the latter excels in instances with important acoustic features. Our findings highlight the importance of fusing word-level representations and sentence-level prosody for enhanced parsing performance. The code and models are made publicly available: https://github.com/mynlp/SpeechParser.
Mind the Gap Between Conversations for Improved Long-Term Dialogue Generation
Oct 24, 2023



Knowing how to end and resume conversations over time is a natural part of communication, allowing for discussions to span weeks, months, or years. The duration of gaps between conversations dictates which topics are relevant and which questions to ask, and dialogue systems which do not explicitly model time may generate responses that are unnatural. In this work we explore the idea of making dialogue models aware of time, and present GapChat, a multi-session dialogue dataset in which the time between each session varies. While the dataset is constructed in real-time, progress on events in speakers' lives is simulated in order to create realistic dialogues occurring across a long timespan. We expose time information to the model and compare different representations of time and event progress. In human evaluation we show that time-aware models perform better in metrics that judge the relevance of the chosen topics and the information gained from the conversation.
Ask an Expert: Leveraging Language Models to Improve Strategic Reasoning in Goal-Oriented Dialogue Models
May 29, 2023



Existing dialogue models may encounter scenarios which are not well-represented in the training data, and as a result generate responses that are unnatural, inappropriate, or unhelpful. We propose the "Ask an Expert" framework in which the model is trained with access to an "expert" which it can consult at each turn. Advice is solicited via a structured dialogue with the expert, and the model is optimized to selectively utilize (or ignore) it given the context and dialogue history. In this work the expert takes the form of an LLM. We evaluate this framework in a mental health support domain, where the structure of the expert conversation is outlined by pre-specified prompts which reflect a reasoning strategy taught to practitioners in the field. Blenderbot models utilizing "Ask an Expert" show quality improvements across all expert sizes, including those with fewer parameters than the dialogue model itself. Our best model provides a $\sim 10\%$ improvement over baselines, approaching human-level scores on "engingingness" and "helpfulness" metrics.
Emergent Communication with Attention
May 18, 2023



To develop computational agents that better communicate using their own emergent language, we endow the agents with an ability to focus their attention on particular concepts in the environment. Humans often understand an object or scene as a composite of concepts and those concepts are further mapped onto words. We implement this intuition as cross-modal attention mechanisms in Speaker and Listener agents in a referential game and show attention leads to more compositional and interpretable emergent language. We also demonstrate how attention aids in understanding the learned communication protocol by investigating the attention weights associated with each message symbol and the alignment of attention weights between Speaker and Listener agents. Overall, our results suggest that attention is a promising mechanism for developing more human-like emergent language.
Rethinking Offensive Text Detection as a Multi-Hop Reasoning Problem
Apr 22, 2022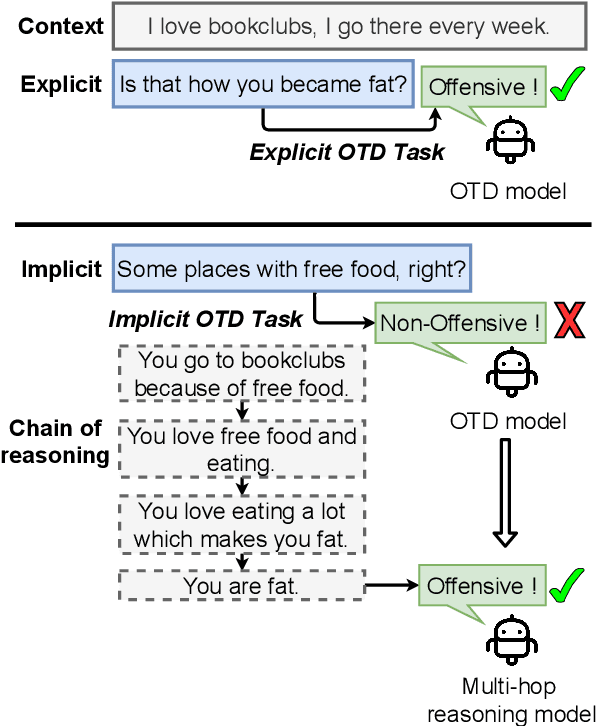

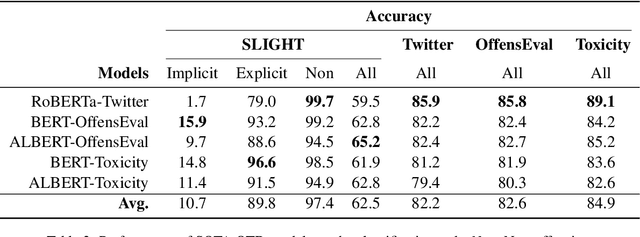
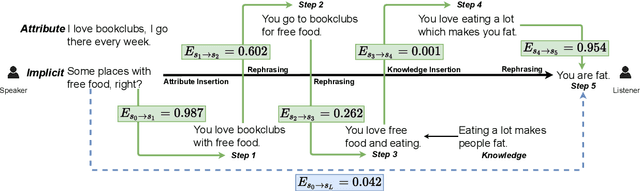
We introduce the task of implicit offensive text detection in dialogues, where a statement may have either an offensive or non-offensive interpretation, depending on the listener and context. We argue that reasoning is crucial for understanding this broader class of offensive utterances and release SLIGHT, a dataset to support research on this task. Experiments using the data show that state-of-the-art methods of offense detection perform poorly when asked to detect implicitly offensive statements, achieving only ${\sim} 11\%$ accuracy. In contrast to existing offensive text detection datasets, SLIGHT features human-annotated chains of reasoning which describe the mental process by which an offensive interpretation can be reached from each ambiguous statement. We explore the potential for a multi-hop reasoning approach by utilizing existing entailment models to score the probability of these chains and show that even naive reasoning models can yield improved performance in most situations. Furthermore, analysis of the chains provides insight into the human interpretation process and emphasizes the importance of incorporating additional commonsense knowledge.
Pow-Wow: A Dataset and Study on Collaborative Communication in Pommerman
Sep 13, 2020
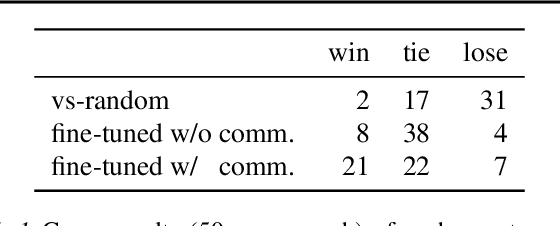
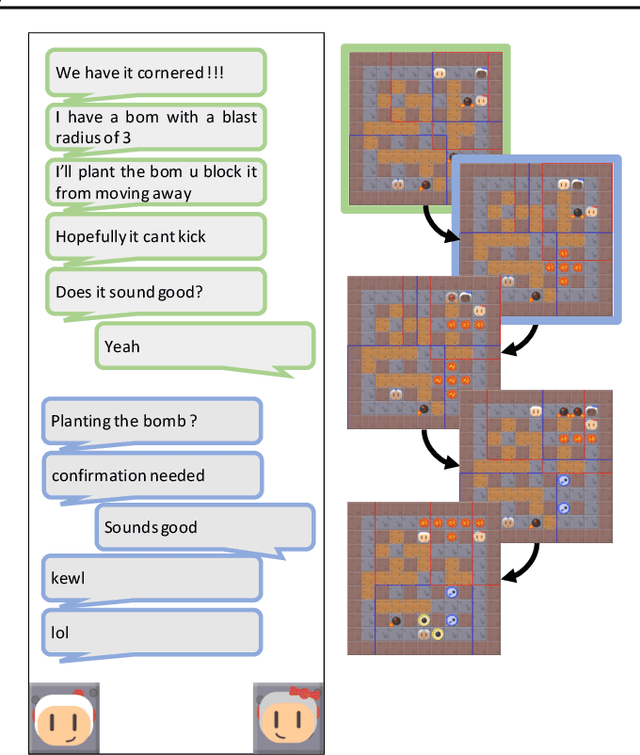
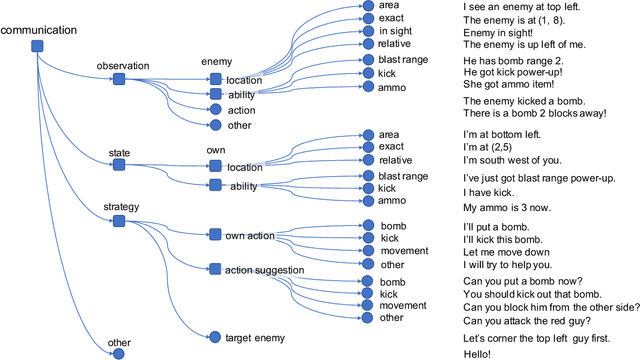
In multi-agent learning, agents must coordinate with each other in order to succeed. For humans, this coordination is typically accomplished through the use of language. In this work we perform a controlled study of human language use in a competitive team-based game, and search for useful lessons for structuring communication protocol between autonomous agents. We construct Pow-Wow, a new dataset for studying situated goal-directed human communication. Using the Pommerman game environment, we enlisted teams of humans to play against teams of AI agents, recording their observations, actions, and communications. We analyze the types of communications which result in effective game strategies, annotate them accordingly, and present corpus-level statistical analysis of how trends in communications affect game outcomes. Based on this analysis, we design a communication policy for learning agents, and show that agents which utilize communication achieve higher win-rates against baseline systems than those which do not.