 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Foundation Model for the Solar Dynamics Observatory
Oct 03, 2024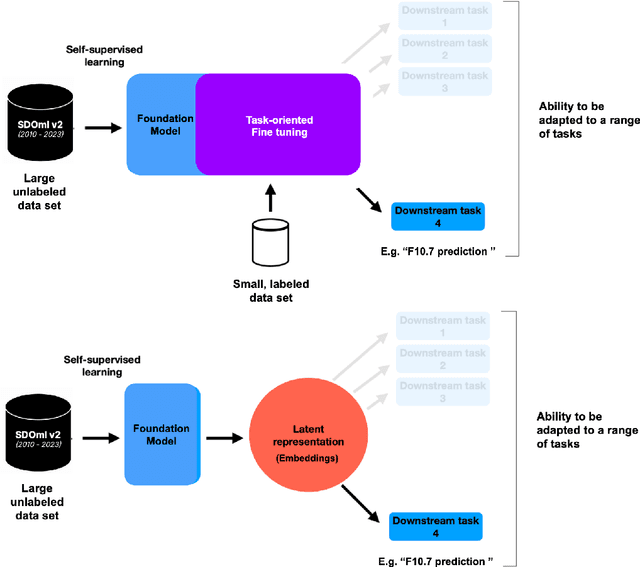


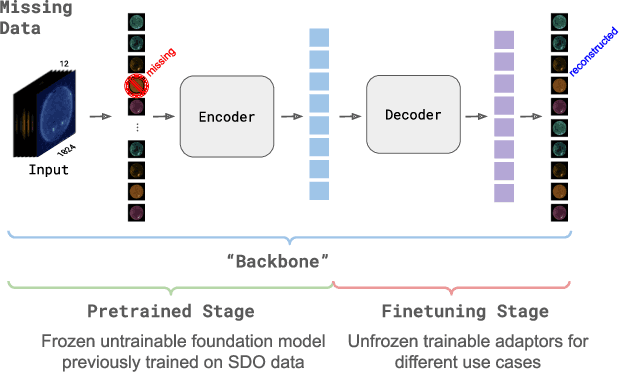
SDO-FM is a foundation model using data from NASA's Solar Dynamics Observatory (SDO) spacecraft; integrating three separate instruments to encapsulate the Sun's complex physical interactions into a multi-modal embedding space. This model can be used to streamline scientific investigations involving SDO by making the enormous datasets more computationally accessible for heliophysics research and enable investigations that require instrument fusion. We discuss four key components: an ingestion pipeline to create machine learning ready datasets, the model architecture and training approach, resultant embeddings and fine-tunable models, and finally downstream fine-tuned applications. A key component of this effort has been to include subject matter specialists at each stage of development; reviewing the scientific value and providing guidance for model architecture, dataset, and training paradigm decisions. This paper marks release of our pretrained models and embedding datasets, available to the community on Hugging Face and sdofm.org.
FloodBrain: Flood Disaster Reporting by Web-based Retrieval Augmented Generation with an LLM
Nov 05, 2023Fast disaster impact reporting is crucial in planning humanitarian assistance. Large Language Models (LLMs) are well known for their ability to write coherent text and fulfill a variety of tasks relevant to impact reporting, such as question answering or text summarization. However, LLMs are constrained by the knowledge within their training data and are prone to generating inaccurate, or "hallucinated", information. To address this, we introduce a sophisticated pipeline embodied in our tool FloodBrain (floodbrain.com), specialized in generating flood disaster impact reports by extracting and curating information from the web. Our pipeline assimilates information from web search results to produce detailed and accurate reports on flood events. We test different LLMs as backbones in our tool and compare their generated reports to human-written reports on different metrics. Similar to other studies, we find a notable correlation between the scores assigned by GPT-4 and the scores given by human evaluators when comparing our generated reports to human-authored ones. Additionally, we conduct an ablation study to test our single pipeline components and their relevancy for the final reports. With our tool, we aim to advance the use of LLMs for disaster impact reporting and reduce the time for coordination of humanitarian efforts in the wake of flood disasters.
Compartmental Models for COVID-19 and Control via Policy Interventions
Mar 06, 2022
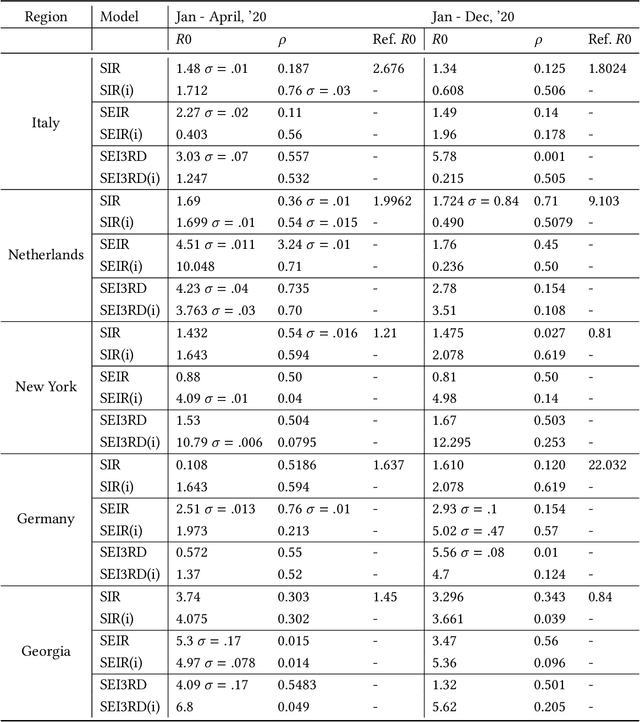

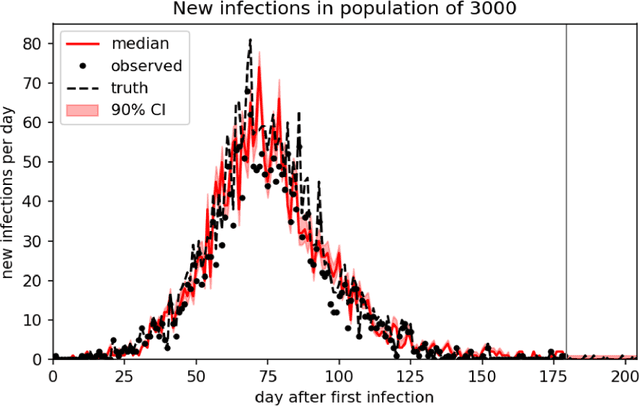
We demonstrate an approach to replicate and forecast the spread of the SARS-CoV-2 (COVID-19) pandemic using the toolkit of probabilistic programming languages (PPLs). Our goal is to study the impact of various modeling assumptions and motivate policy interventions enacted to limit the spread of infectious diseases. Using existing compartmental models we show how to use inference in PPLs to obtain posterior estimates for disease parameters. We improve popular existing models to reflect practical considerations such as the under-reporting of the true number of COVID-19 cases and motivate the need to model policy interventions for real-world data. We design an SEI3RD model as a reusable template and demonstrate its flexibility in comparison to other models. We also provide a greedy algorithm that selects the optimal series of policy interventions that are likely to control the infected population subject to provided constraints. We work within a simple, modular, and reproducible framework to enable immediate cross-domain access to the state-of-the-art in probabilistic inference with emphasis on policy interventions. We are not epidemiologists; the sole aim of this study is to serve as an exposition of methods, not to directly infer the real-world impact of policy-making for COVID-19.