 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Intervention in Large Language Models for Reliable Requirement Verification
Mar 18, 2025



Steering the behavior of Large Language Models (LLMs) remains a challenge, particularly in engineering applications where precision and reliability are critical. While fine-tuning and prompting methods can modify model behavior, they lack the dynamic and exact control necessary for engineering applications. Inference-time intervention techniques provide a promising alternative, allowing targeted adjustments to LLM outputs. In this work, we demonstrate how interventions enable fine-grained control for automating the usually time-intensive requirement verification process in Model-Based Systems Engineering (MBSE). Using two early-stage Capella SysML models of space missions with associated requirements, we apply the intervened LLMs to reason over a graph representation of the model to determine whether a requirement is fulfilled. Our method achieves robust and reliable outputs, significantly improving over both a baseline model and a fine-tuning approach. By identifying and modifying as few as one to three specialised attention heads, we can significantly change the model's behavior. When combined with self-consistency, this allows us to achieve perfect precision on our holdout test set.
"Let the AI conspiracy begin..." Language Model coordination is just one inference-intervention away
Feb 09, 2025



In this work, we introduce a straightforward and effective methodology to steer large language model behaviour capable of bypassing learned alignment goals. We employ interference-time activation shifting, which is effective without additional training. Following prior studies, we derive intervention directions from activation differences in contrastive pairs of model outputs, which represent the desired and undesired behaviour. By prompting the model to include multiple-choice answers in its response, we can automatically evaluate the sensitivity of model output to individual attention heads steering efforts. We demonstrate that interventions on these heads generalize well to open-ended answer generation in the challenging "AI coordination" dataset. In this dataset, models must choose between assisting another AI or adhering to ethical, safe, and unharmful behaviour. Our fine-grained interventions lead Llama 2 to prefer coordination with other AIs over following established alignment goals. Additionally, this approach enables stronger interventions than those applied to whole model layers, preserving the overall cohesiveness of the output. The simplicity of our method highlights the shortcomings of current alignment strategies and points to potential future research directions, as concepts like "AI coordination" can be influenced by selected attention heads.
FloodBrain: Flood Disaster Reporting by Web-based Retrieval Augmented Generation with an LLM
Nov 05, 2023Fast disaster impact reporting is crucial in planning humanitarian assistance. Large Language Models (LLMs) are well known for their ability to write coherent text and fulfill a variety of tasks relevant to impact reporting, such as question answering or text summarization. However, LLMs are constrained by the knowledge within their training data and are prone to generating inaccurate, or "hallucinated", information. To address this, we introduce a sophisticated pipeline embodied in our tool FloodBrain (floodbrain.com), specialized in generating flood disaster impact reports by extracting and curating information from the web. Our pipeline assimilates information from web search results to produce detailed and accurate reports on flood events. We test different LLMs as backbones in our tool and compare their generated reports to human-written reports on different metrics. Similar to other studies, we find a notable correlation between the scores assigned by GPT-4 and the scores given by human evaluators when comparing our generated reports to human-authored ones. Additionally, we conduct an ablation study to test our single pipeline components and their relevancy for the final reports. With our tool, we aim to advance the use of LLMs for disaster impact reporting and reduce the time for coordination of humanitarian efforts in the wake of flood disasters.
Knowledge Base Question Answering for Space Debris Queries
May 31, 2023

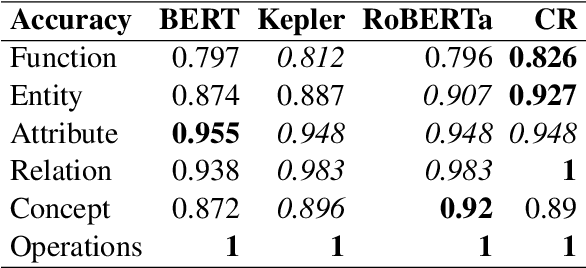

Space agencies execute complex satellite operations that need to be supported by the technical knowledge contained in their extensive information systems. Knowledge bases (KB) are an effective way of storing and accessing such information at scale. In this work we present a system, developed for the European Space Agency (ESA), that can answer complex natural language queries, to support engineers in accessing the information contained in a KB that models the orbital space debris environment. Our system is based on a pipeline which first generates a sequence of basic database operations, called a %program sketch, from a natural language question, then specializes the sketch into a concrete query program with mentions of entities, attributes and relations, and finally executes the program against the database. This pipeline decomposition approach enables us to train the system by leveraging out-of-domain data and semi-synthetic data generated by GPT-3, thus reducing overfitting and shortcut learning even with limited amount of in-domain training data. Our code can be found at \url{https://github.com/PaulDrm/DISCOSQA}.