 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompartmental Models for COVID-19 and Control via Policy Interventions
Mar 06, 2022
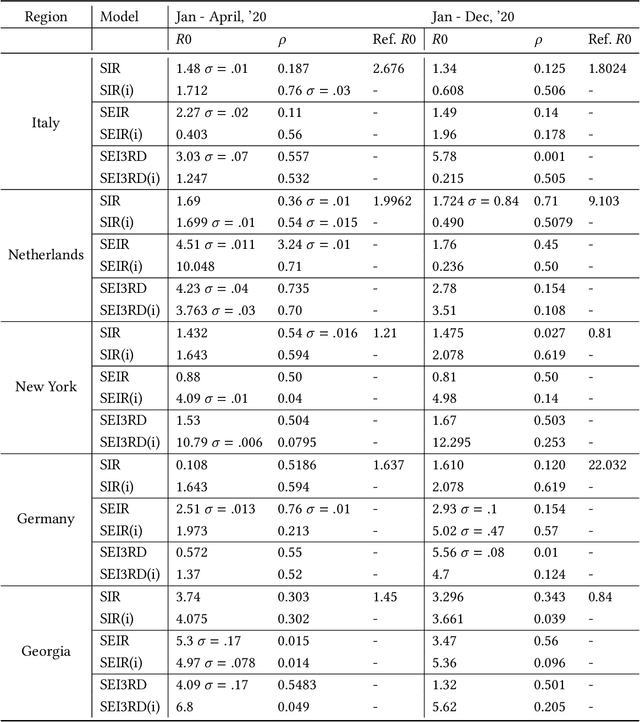

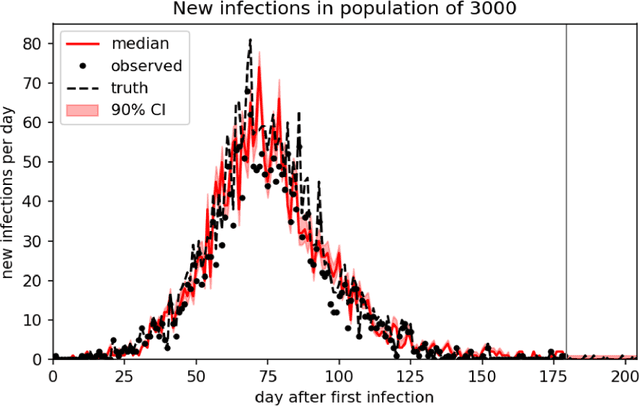
We demonstrate an approach to replicate and forecast the spread of the SARS-CoV-2 (COVID-19) pandemic using the toolkit of probabilistic programming languages (PPLs). Our goal is to study the impact of various modeling assumptions and motivate policy interventions enacted to limit the spread of infectious diseases. Using existing compartmental models we show how to use inference in PPLs to obtain posterior estimates for disease parameters. We improve popular existing models to reflect practical considerations such as the under-reporting of the true number of COVID-19 cases and motivate the need to model policy interventions for real-world data. We design an SEI3RD model as a reusable template and demonstrate its flexibility in comparison to other models. We also provide a greedy algorithm that selects the optimal series of policy interventions that are likely to control the infected population subject to provided constraints. We work within a simple, modular, and reproducible framework to enable immediate cross-domain access to the state-of-the-art in probabilistic inference with emphasis on policy interventions. We are not epidemiologists; the sole aim of this study is to serve as an exposition of methods, not to directly infer the real-world impact of policy-making for COVID-19.
Anomaly Detection for Network Connection Logs
Dec 01, 2018We leverage a streaming architecture based on ELK, Spark and Hadoop in order to collect, store, and analyse database connection logs in near real-time. The proposed system investigates outliers using unsupervised learning; widely adopted clustering and classification algorithms for log data, highlighting the subtle variances in each model by visualisation of outliers. Arriving at a novel solution to evaluate untagged, unfiltered connection logs, we propose an approach that can be extrapolated to a generalised system of analysing connection logs across a large infrastructure comprising thousands of individual nodes and generating hundreds of lines in logs per second.
A Big Data Architecture for Log Data Storage and Analysis
Dec 01, 2018



We propose an architecture for analysing database connection logs across different instances of databases within an intranet comprising over 10,000 users and associated devices. Our system uses Flume agents to send notifications to a Hadoop Distributed File System for long-term storage and ElasticSearch and Kibana for short-term visualisation, effectively creating a data lake for the extraction of log data. We adopt machine learning models with an ensemble of approaches to filter and process the indicators within the data and aim to predict anomalies or outliers using feature vectors built from this log data.